
ソリューション
K8sがNebulaGraphクラスターをデプロイした後にクラスターに接続できないという問題を解決する最も便利な方法は、nebula-operatorshow hosts metaと域名:端口し、アドレスを入力することです。構成へのMetaDフォーマット。
注:ここではバージョン2.6.2以降が必要です。nebula-spark-connector/ nebula-algorithmは、ドメイン名の形式のMetaDアドレスのみをサポートします。
実際のネットワーク構成は次のとおりです。
- MetaDアドレスを取得する
(root@nebula) [(none)]> show hosts meta
+------------------------------------------------------------------+------+----------+--------+--------------+---------+
| Host | Port | Status | Role | Git Info Sha | Version |
+------------------------------------------------------------------+------+----------+--------+--------------+---------+
| "nebula-metad-0.nebula-metad-headless.default.svc.cluster.local" | 9559 | "ONLINE" | "META" | "d113f4a" | "2.6.2" |
+------------------------------------------------------------------+------+----------+--------+--------------+---------+
Got 1 rows (time spent 1378/2598 us)
Mon, 14 Feb 2022 08:22:33 UTC
後続の構成ファイルで使用できるように、ホスト名をここに記録する必要があります。
- nebula-algorithmの構成ファイルに入力します
ドキュメントhttps://github.com/vesoft-inc/nebula-algorithm/blob/master/nebula-algorithm/src/main/resources/application.confを参照してください。設定ファイルに入力するには、TOMLファイルを変更する方法とnebula-spark-connectorコードに設定情報を追加する方法の2つがあります。
方法1:TOMLファイルを変更する
# ...
nebula: {
# algo's data source from Nebula. If data.source is nebula, then this nebula.read config can be valid.
read: {
# 这里填上刚获得到的 meta 的 Host 名,多个地址的话用英文字符下的逗号隔开;
metaAddress: "nebula-metad-0.nebula-metad-headless.default.svc.cluster.local:9559"
#...
方法2:nebula-spark-connectorのコードを呼び出す
val config = NebulaConnectionConfig
.builder()
// 这里填上刚获得到的 meta 的 Host 名
.withMetaAddress("nebula-metad-0.nebula-metad-headless.default.svc.cluster.local:9559")
.withConenctionRetry(2)
.build()
val nebulaReadVertexConfig: ReadNebulaConfig = ReadNebulaConfig
.builder()
.withSpace("foo_bar_space")
.withLabel("person")
.withNoColumn(false)
.withReturnCols(List("birthday"))
.withLimit(10)
.withPartitionNum(10)
.build()
val vertex = spark.read.nebula(config, nebulaReadVertexConfig).loadVerticesToDF()
さて、これまでのところ、プロセスはかなり簡単に見えます。では、なぜこのような単純なプロセスは記事に値するのでしょうか。
構成情報は無視しやすい
具体的な実際の操作について話しましたが、ここにはいくつかの理論的な知識があります。
a。MetaDは、Spark環境からStorageDのアドレスにアクセスできるようにする必要があります。
b。StorageDアドレスはMetaDから取得されます。
c。NebulaK8sオペレーターでは、MetaDに保存されているStorageDアドレス(サービスディスカバリ)のソースは、K8sの内部アドレスであるStorageD構成ファイルです。
背景知識
a。の理由は比較的単純で、星雲のアーキテクチャに関連しています。グラフのデータはストレージサービスに保存されます。通常、ステートメントのクエリはグラフサービスを介して透過的に送信されます。GraphDの接続のみが十分なnebula-spark-コネクタがNebulaGraphを使用するシナリオは、グラフ全体またはサブグラフをスキャンすることです。現時点では、コンピューティングとストレージの分離の設計により、クエリとコンピューティングレイヤーをバイパスして直接かつ効率的に読み取ることができます。グラフデータ。
だから問題は、なぜあなたはMetaDアドレスだけが必要で、必要なのかということです。
これはアーキテクチャにも関連しています。メタサービスには完全なグラフの分散データと、分散ストレージサービスの各シャードとインスタンスの分散が含まれているため、一方ではメタのみが完全なグラフの情報を持っています(必須) )、一方、情報のこの部分(のみ)はMetaから取得できるためです。これがbの答えです。
- 詳細な星雲グラフアーキテクチャ情報は、アーキテクチャ三部作シリーズを参照できます
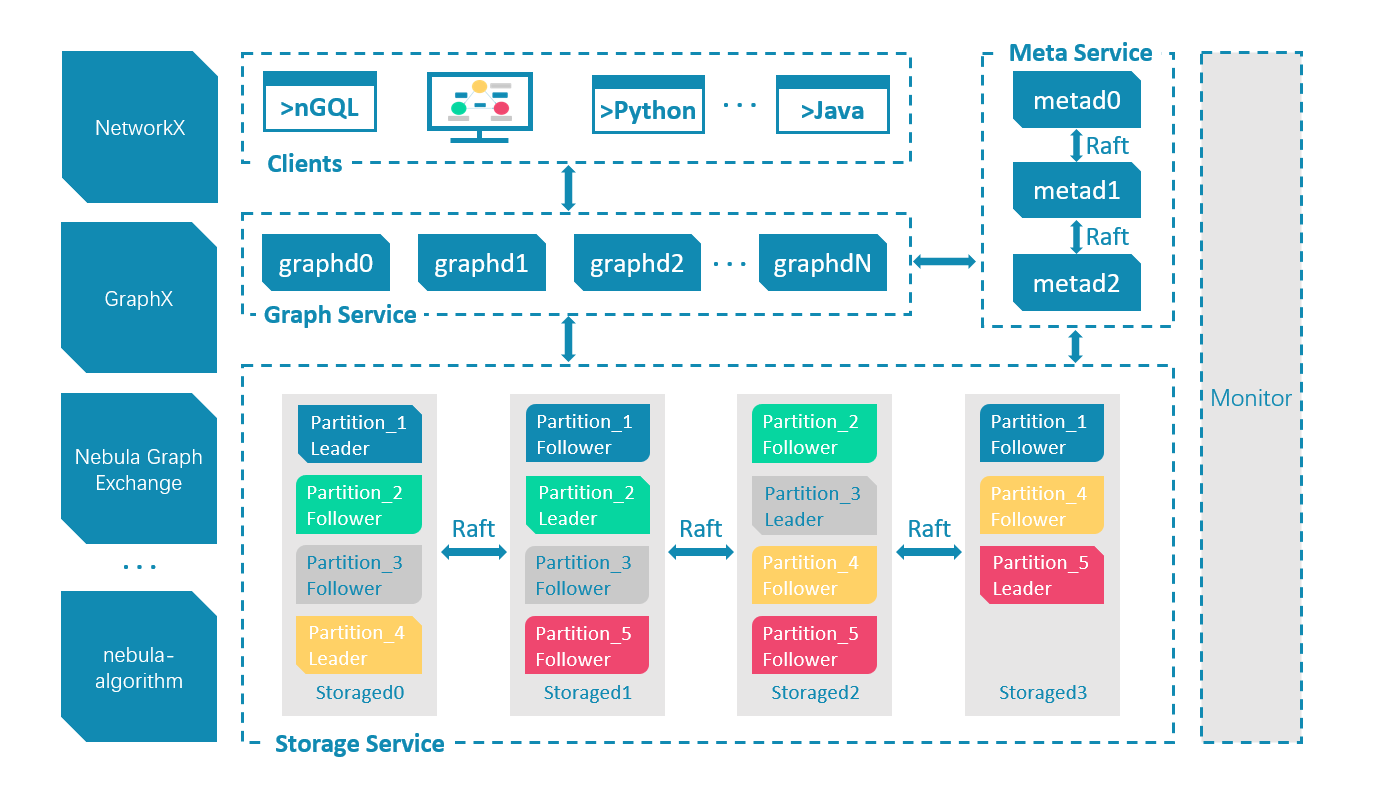
cの背後にあるロジックを見てみましょう。
c。NebulaK8sオペレーターでは、MetaDに保存されているStorageDアドレス(サービスディスカバリ)のソースは、k8sの内部アドレスであるStorageD構成ファイルです。
これは、Nebula Graphのサービス検出メカニズムに関連しています。NebulaGraphクラスターでは、GraphServiceとStorageServiceの両方がハートビートを介してメタサービスに情報を報告し、サービス自体のアドレスのソースは対応するネットワークから取得されます。構成ファイルの構成。
-
サービス自体のアドレス構成については、ドキュメント「ストレージネットワーク構成」を参照してください。
-
サービスディスカバリの詳細については、Four Kings:Graph Database Nebula Graph Cluster Communication:StartingwithHeartbeatの記事を参照してください。

最後に、Nebula Operatorは、K8sクラスターの構成に従ってNebulaクラスターのK8sコントロールプレーンを自動的に作成、維持、スケーリングするアプリケーションであることがわかっています。GraphDやStorageDインスタンス。それらが設定されている実際のアドレスは、実際にはヘッドレスサービスアドレスです。
これらのアドレス(次のとおり)は、デフォルトではK8s外部ネットワークからアクセスできないため、GraphDおよびMetaDの場合、それらを公開するサービスを簡単に作成できます。
(root@nebula) [(none)]> show hosts meta
+------------------------------------------------------------------+------+----------+--------+--------------+---------+
| Host | Port | Status | Role | Git Info Sha | Version |
+------------------------------------------------------------------+------+----------+--------+--------------+---------+
| "nebula-metad-0.nebula-metad-headless.default.svc.cluster.local" | 9559 | "ONLINE" | "META" | "d113f4a" | "2.6.2" |
+------------------------------------------------------------------+------+----------+--------+--------------+---------+
Got 1 rows (time spent 1378/2598 us)
Mon, 14 Feb 2022 09:22:33 UTC
(root@nebula) [(none)]> show hosts graph
+---------------------------------------------------------------+------+----------+---------+--------------+---------+
| Host | Port | Status | Role | Git Info Sha | Version |
+---------------------------------------------------------------+------+----------+---------+--------------+---------+
| "nebula-graphd-0.nebula-graphd-svc.default.svc.cluster.local" | 9669 | "ONLINE" | "GRAPH" | "d113f4a" | "2.6.2" |
+---------------------------------------------------------------+------+----------+---------+--------------+---------+
Got 1 rows (time spent 2072/3403 us)
Mon, 14 Feb 2022 10:03:58 UTC
(root@nebula) [(none)]> show hosts storage
+------------------------------------------------------------------------+------+----------+-----------+--------------+---------+
| Host | Port | Status | Role | Git Info Sha | Version |
+------------------------------------------------------------------------+------+----------+-----------+--------------+---------+
| "nebula-storaged-0.nebula-storaged-headless.default.svc.cluster.local" | 9779 | "ONLINE" | "STORAGE" | "d113f4a" | "2.6.2" |
| "nebula-storaged-1.nebula-storaged-headless.default.svc.cluster.local" | 9779 | "ONLINE" | "STORAGE" | "d113f4a" | "2.6.2" |
| "nebula-storaged-2.nebula-storaged-headless.default.svc.cluster.local" | 9779 | "ONLINE" | "STORAGE" | "d113f4a" | "2.6.2" |
+------------------------------------------------------------------------+------+----------+-----------+--------------+---------+
Got 3 rows (time spent 1603/2979 us)
Mon, 14 Feb 2022 10:05:24 UTC
ただし、前述のnebula-spark-connectorはMeta Serviceを介してStorageDのアドレスを取得し、このアドレスはサービスによって検出されるため、nebula-spark-connectorによって実際に取得されるStorageDアドレスは、上記のヘッドレスサービスです。外部から直接アクセスします。
したがって、条件が整っている場合は、SparkをNebula Clusterと同じK8sネットワークで実行するだけで、すべてが解決されます。それ以外の場合は、次のことを行う必要があります。
-
Ingressを使用してMetaDおよびStorageDのL4(TCP)アドレスを公開します。
Nebula Operatorのドキュメントを参照できます:https ://github.com/vesoft-inc/nebula-operator
-
これらのヘッドレスサービスは、リバースプロキシとDNSを介して対応するStorageDに解決できます。
それで、もっと便利な方法はありますか?
残念ながら、最も便利な方法は、記事の冒頭で説明したとおりです。Sparkを星雲クラスター内で実行させます。実際、私はNebula Sparkコミュニティをプッシュして、構成可能なStorageAddressesオプションをサポートしようとしています。これにより、前述の2.は不要になります。
より便利な星雲-アルゴリズム+星雲-オペレーター体験
K8sでnebula-graphとnebula-algorithmを早期に採用している学生を支援するために、アムウェイ自身が作成した小さなツールNeubla-Operator-KinDを次に示します。Operatorとすべての依存関係(ストレージプロバイダーを含む)ウィジェット。それだけでなく、小さな星雲クラスターを自動的に展開します。以下の手順をご覧ください。
最初のステップは、K8s + nebula-operator+NebulaClusterをデプロイすることです。
curl -sL nebula-kind.siwei.io/install.sh | bash

2番目のステップは、ツールのドキュメントの次の手順に従います
a。コンソールを使用してクラスターに接続し、サンプルデータセットをロードします
- Spark環境を作成する
kubectl create -f http://nebula-kind.siwei.io/deployment/spark.yaml
kubectl wait pod --timeout=-1s --for=condition=Ready -l '!job-name'
- 上記の待機の準備ができたら、スパークポッドに入ります。
kubectl exec -it deploy/spark-deployment -- bash
2.6.2このバージョンなどのnebula-algorithmをダウンロードします。その他のバージョンについては、 https://github.com/vesoft-inc/nebula-algorithm/を参照してください。
予防:
- 公式リリースバージョンは、https ://repo1.maven.org/maven2/com/vesoft/nebula-algorithm/から入手できます。
- この問題のため:https
2.6.2://github.com/vesoft-inc/nebula-algorithm/issues/42MetaDへのドメイン名アクセスをサポートしているのはそれ以降のバージョンのみです。
# 下载 nebula-algorithm-2.6.2.jar
wget https://repo1.maven.org/maven2/com/vesoft/nebula-algorithm/2.6.2/nebula-algorithm-2.6.2.jar
# 下载 nebula-algorthm 配置文件
wget https://github.com/vesoft-inc/nebula-algorithm/raw/v2.6/nebula-algorithm/src/main/resources/application.conf
- nebula-algorithmのmeteおよびgraphアドレス情報を変更します。
sed -i '/^ metaAddress/c\ metaAddress: \"nebula-metad-0.nebula-metad-headless.default.svc.cluster.local:9559\"' application.conf
sed -i '/^ graphAddress/c\ graphAddress: \"nebula-graphd-0.nebula-graphd-svc.default.svc.cluster.local:9669\"' application.conf
##### change space
sed -i '/^ space/c\ space: basketballplayer' application.conf
##### read data from nebula graph
sed -i '/^ source/c\ source: nebula' application.conf
##### execute algorithm: labelpropagation
sed -i '/^ executeAlgo/c\ executeAlgo: labelpropagation' application.conf
- バスケットボール選手のグラフ空間でLPAアルゴリズムを実行する
/spark/bin/spark-submit --master "local" --conf spark.rpc.askTimeout=6000s \
--class com.vesoft.nebula.algorithm.Main \
nebula-algorithm-2.6.2.jar \
-p application.conf
- 結果は次のとおりです。
bash-5.0# ls /tmp/count/
_SUCCESS part-00000-5475f9f4-66b9-426b-b0c2-704f946e54d3-c000.csv
bash-5.0# head /tmp/count/part-00000-5475f9f4-66b9-426b-b0c2-704f946e54d3-c000.csv
_id,lpa
1100,1104
2200,2200
2201,2201
1101,1104
2202,2202
次に、ハッピーグラフができます!
交換グラフデータベース技術?星雲交換グループに参加するには、最初に星雲の名刺を記入してください。星雲のアシスタントがあなたをグループに引き込みます~~