我们来看看zk的服务端源码
他服务器源码是从 QuorumPeerMain 这个类中看的
org.apache.zookeeper.server.quorum.QuorumPeerConfig
这个方法就是加载配置文件 将配置文件中的内容加入进来 要注意一点就是
配置文件中如果以 server.开头的 他会给你放入到 observers 这个和servers 这个集合中
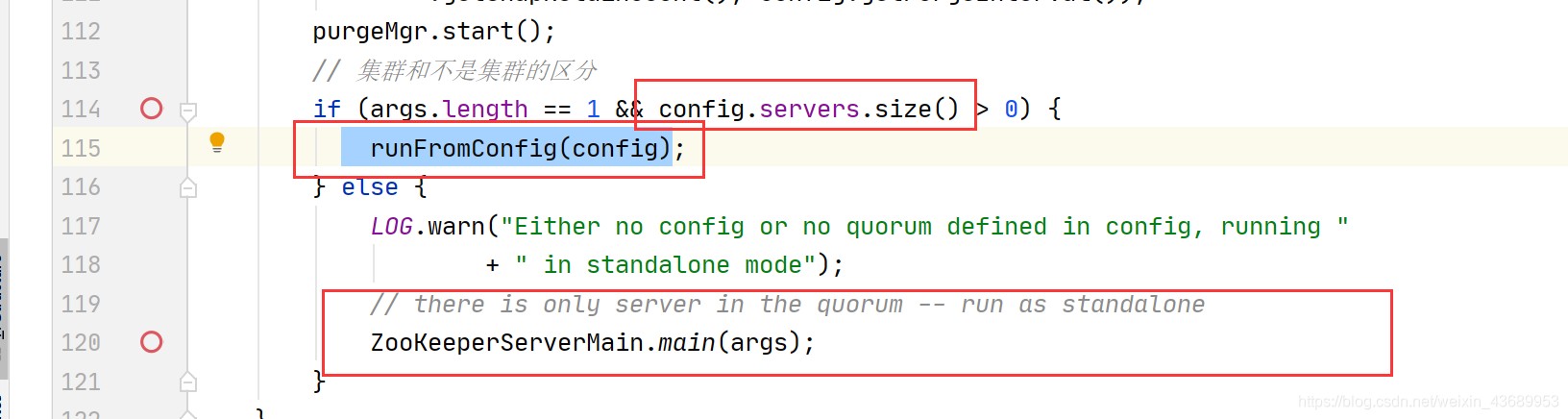
然后他就在这里区分了 如果是集群模式下就会走 runFromConfig(config);
单机版就会走 ZooKeeperServerMain.main(args);
org.apache.zookeeper.server.ZooKeeperServerMain
接下来看这个方法 单机版 根据配置文件会执行什么操作
zk服务端的启动其实有这么几步,zk服务端有事务日志和快照这么一说,比方说 我现在操作一个create,我们创造的节点,zk肯定会进行持久化操作的,他这个节点 同时在内存中也有一份,内存中的叫做DataBase,DataTree,以及DataNode, DataNode最终就是我们创造的节点
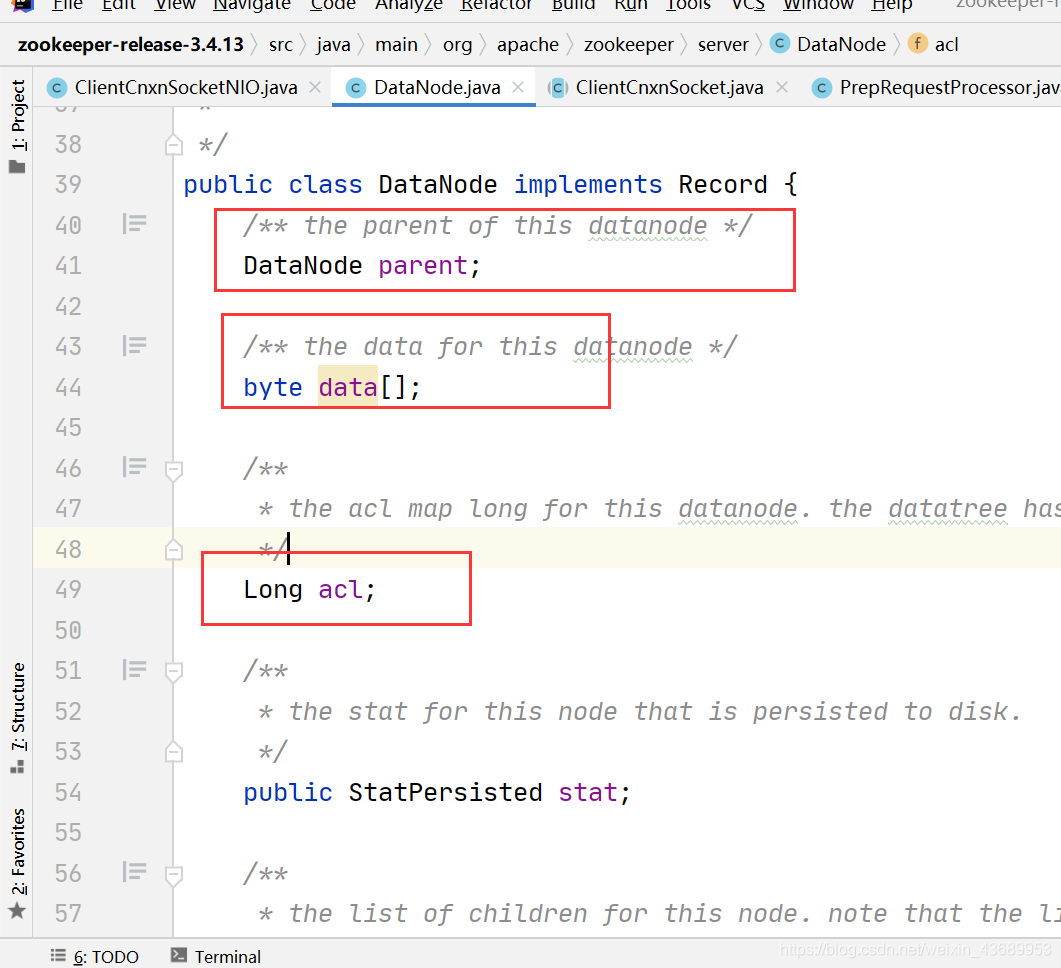
DataNode中的属性有什么 父节点 数据内容 acl权限列表 , 这些数据结构基本上只有在内存中才会有
呢么事务日志是什么意思呢 比方说我现在create一个节点,就像数据库一样插入一条数据, 数据库会有一条关于事务的日志来做记录,这里也一样, 对于zk的server端,当接受到这么一个create命令的时候,他第一步
>1.会创建事务日志,然后直接保存到日志的目录去
>2,在某个点会打个快照,快照就是对database的快照,也是以文件的形式存进去的
>3,这个时候才会去更新内存,操作dataBase
>4.这一套成功或者失败 返回成功信息 或者失败信息
这其中包括2个持久化 一个是日志文件的持久化 一个是快照文件的持久化
服务器启动的时候 会从文件中加载数据到内存,主要是这个额dataDir(快照)
dataLogDir 将事务日志存储在该路径下,比较重要,这个日志存储的设备效率会影响ZK的写吞吐量。
dataDir 内存快照存放地址,
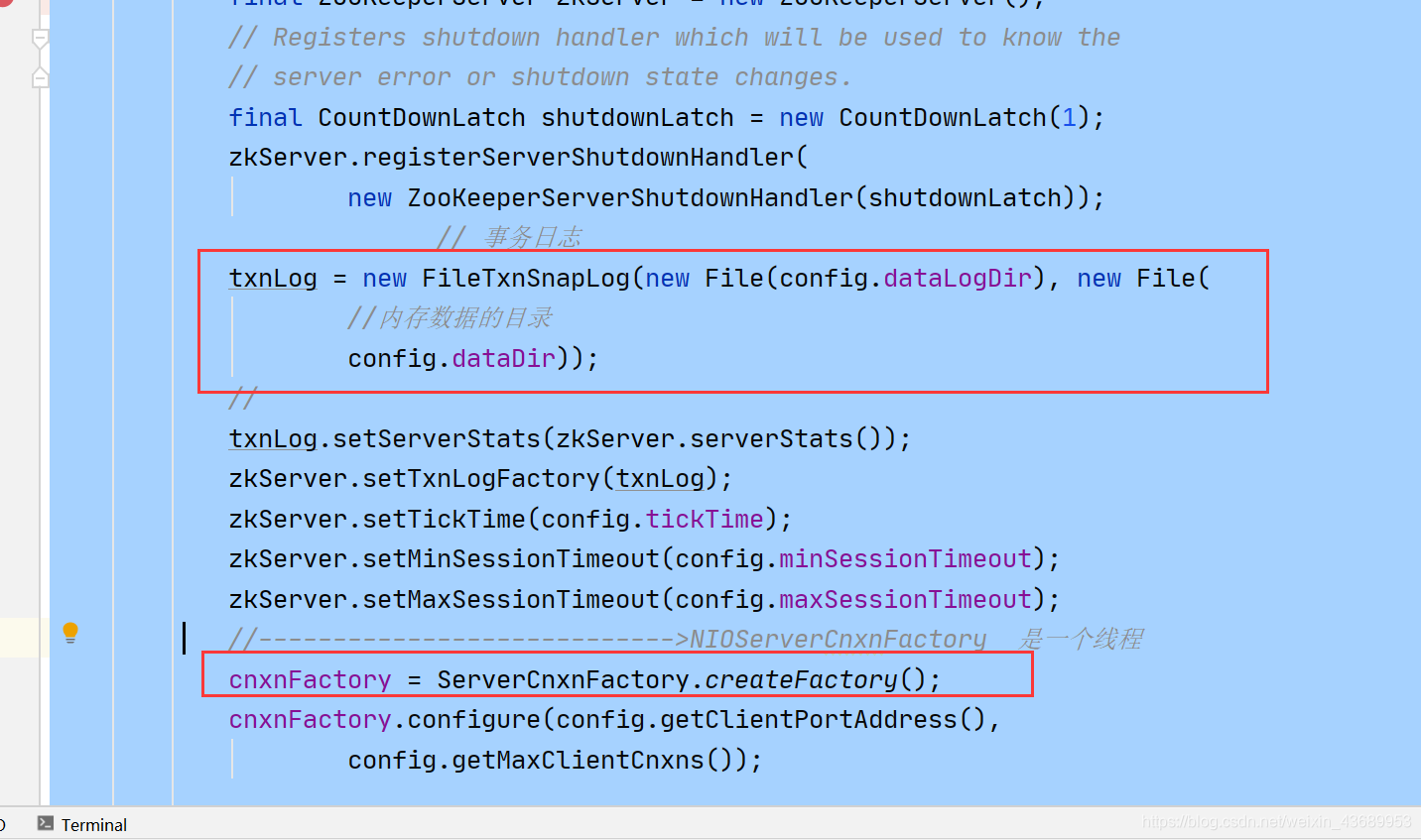
FileTxnSnapLog这个类是个工具类
事务日志和持久化工具类
1.TnxLog-事务日志
2.SnapShot 快照日志
2,cnxnFactory = ServerCnxnFactory.createFactory();//可以看到 zk服务端也是用的nio来接受数据的 NIOServerCnxnFactory 但是此时他是一个线程 ,线程意味着可以run
1. 我们看下这段逻辑
org.apache.zookeeper.server.NIOServerCnxnFactory
@Override
public void configure(InetSocketAddress addr, int maxcc) throws IOException {
configureSaslLogin();
// 吧当前类作为线程
thread = new ZooKeeperThread(this, "NIOServerCxn.Factory:" + addr);
// 守护线程 GC 线程就是守护线程
thread.setDaemon(true);
maxClientCnxns = maxcc;
// 开启socket
this.ss = ServerSocketChannel.open();
ss.socket().setReuseAddress(true);
LOG.info("binding to port " + addr);
ss.socket().bind(addr);
ss.configureBlocking(false);
ss.register(selector, SelectionKey.OP_ACCEPT);
}
1。上面我也说了zk底层用的nio 接受数据的
2,并且开放端口号 然后注册到selector上 标注为 accept事件
我为了学zk 我专门看了看nio
org.apache.zookeeper.server.NIOServerCnxnFactory
@Override
public void startup(ZooKeeperServer zks) throws IOException,
InterruptedException {
start();
setZooKeeperServer(zks);
zks.startdata();
zks.startup();
}
//接着看这个方法 第一步就是 start
1.start---> 启动呢个线程
2,zks.startdata(); 从txnLogFactory里读取快照数据。
3.org.apache.zookeeper.server.ZooKeeperServer
这个方法主要是处理session 的
客户端和服务端其实是有session连接的,session会在服务端进行一个倒计时,就类似于一个跟踪器 [sessionTracker]
这个session 追踪器也是个线程 他主要做的事情就是 你服务端检测出来如果有session 过期了,按道理 你会通知客户端进行关闭
你服务端启动的大致逻辑大概就是这样的
1。有一个nio 得线程
2.加载数据到内存
3.启动一个session追踪器
重点是setupRequestProcessors();
设置一个请求处理器,请求处理器 肯定是处理请求的
org.apache.zookeeper.server.ZooKeeperServer
//看下这个方法 里面 有3个处理器,这三个处理器都是线程
PrepRequestProcessor----->SyncRequestProcessor--->FinalRequestProcessor
大致意思是说一个请求过来 会根据不通的处理器 处理不同的逻辑
这些请求处理器在什么时候会用呢?
我们在看下我们的nio 的run方法做了什么事情,主要还是nio的呢一套逻辑我们只要看下他的读写事件
NIOServerCnxn c = (NIOServerCnxn) k.attachment();
// 读数据
c.doIO(k);
readPayload() ; // 主要看这句话
org.apache.zookeeper.server.NIOServerCnxn
我们主要看这段代码逻辑 就是读数据的
org.apache.zookeeper.server.ZooKeeperServer
看这个提交请求的逻辑
firstProcessor.processRequest(si); 主要看这里 这里的firstProcessor就是之前初始化的呢个 PrepRequestProcessor
我们看 PrepRequestProcessor,processRequest(si); 看下这个请求处理器如何处理请求的
public void processRequest(Request request) {
// request.addRQRec(">prep="+zks.outstandingChanges.size());
submittedRequests.add(request);
}
他的做法很简单就是把当前这个请求放到submittedRequests 这个队列里面
呢么 你把请求加入到这个submittedRequests 队列里面 到底谁来处理呢
PrepRequestProcessor 这个也是一个线程 我们看下他的run方法
@Override
public void run() {
try {
while (true) {
Request request = submittedRequests.take();
long traceMask = ZooTrace.CLIENT_REQUEST_TRACE_MASK;
// 如果是ping ,打印日志
if (request.type == OpCode.ping) {
traceMask = ZooTrace.CLIENT_PING_TRACE_MASK;
}
if (LOG.isTraceEnabled()) {
ZooTrace.logRequest(LOG, traceMask, 'P', request, "");
}
if (Request.requestOfDeath == request) {
break;
}
pRequest(request);
}
} catch (RequestProcessorException e) {
if (e.getCause() instanceof XidRolloverException) {
LOG.info(e.getCause().getMessage());
}
handleException(this.getName(), e);
} catch (Exception e) {
handleException(this.getName(), e);
}
LOG.info("PrepRequestProcessor exited loop!");
}
......
看他的run 方法里面就是从submittedRequests 里面拿到请求然后再进行处理的
如果是ping请求的话就打印日志,如果不是Ping请求的话 处理请求
pRequest(request);
org.apache.zookeeper.server.PrepRequestProcessor
接下来看看这个方法 根据 request.type 类型不同走不不一样的逻辑
然后
nextProcessor.processRequest(request);// 处理完之后会把这个请求移交给下一个处理器,下一个处理器是SyncRequestProcessor
这个处理器主要是做持久化操作的
SyncRequestProcessor这个处理器也是 把这个请求放到一个队列中去,然后 run方法跑线程去消费 run方法中处理的逻辑主要是请求中获取数据就是去持久化的
public void processRequest(Request request) {
// request.addRQRec(">sync");
queuedRequests.add(request);
}