学习致谢:
https://www.bilibili.com/video/BV1Xz4y1m7cv?p=42
需求:
对从Socket接收的数据做WordCoun并要求能够和历史数据进行累加!
如:先发了一个spark,得到spark,1然后不管隔多久再发一个spark,得到spark,2也就是说要对数据的历史状态进行维护!
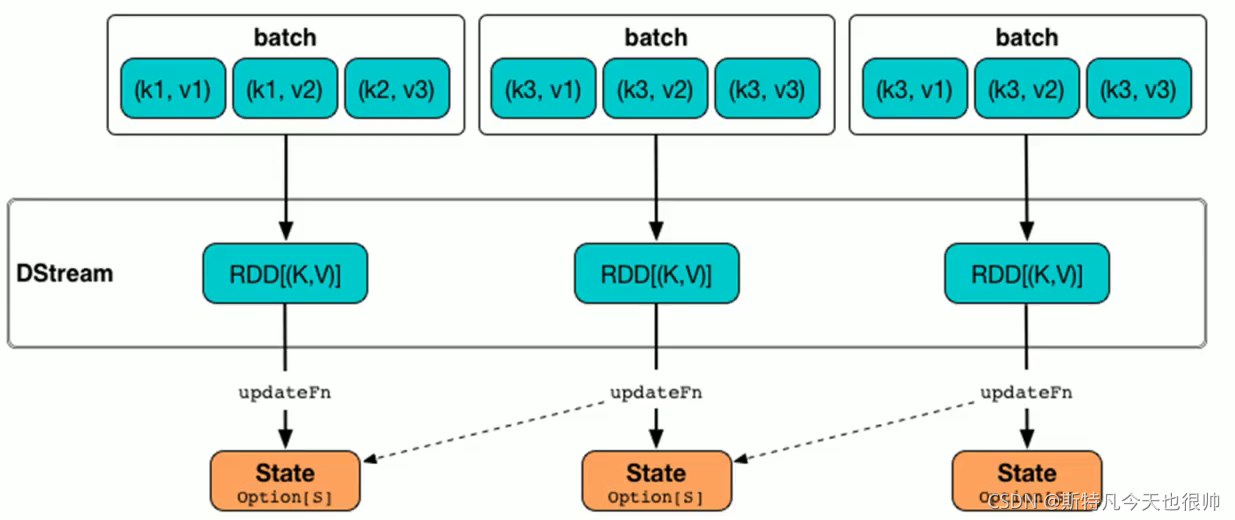
实现思路:
一、updataStateByKey
先设置checkpoint存储状态status,使用updataStateByKey实现状态管理的单词统计,需要自己写一个updateFunc方法,如下:

代码实现
package streaming
import org.apache.spark.{
SparkConf, SparkContext}
import org.apache.spark.streaming.{
Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{
DStream, ReceiverInputDStream}
/**
* Author itcast
* Desc 使用SparkStreaming接受node1"9999的数据并做WordCount+实现状态管理
* 如输入 spark hadoop得到(spark,1)(hadoop,1)
* 再下一个批次输入spark,得到spark,2
*/
object Status {
def main(args: Array[String]): Unit = {
//TODO 0.准备环境
val conf:SparkConf=new SparkConf().setMaster("spark").setMaster("local[*]")
val sc: SparkContext=new SparkContext(conf)
sc.setLogLevel("WARN")
//the time interval at which streaming data will be dicided into batches
val ssc:StreamingContext= new StreamingContext(sc,Seconds(5))
//The checkpoint directory has not been set. PLease set it by streamingContext.checkpoint().
//注意:state存在checkpoint中
ssc.checkpoint("./ckp")
//TODO 1.加载数据
val lines:ReceiverInputDStream[String]=ssc.socketTextStream("node1",9999)
//TODO 2.处理数据
//定义一个函数用来处理状态:把当前数据和历史状态累加
//currentValues:表示该key(spark)的当前批次的值,如:[1,1]
//historyValue:表示该key(如spark)的历史值,第一次是0,后面之后就是之前的累加值,如1
val updateFunc=(currentValues:Seq[Int],historyValue:Option[Int])=>{
if(currentValues.size>0){
val currentResult:Int=currentValues.sum+historyValue.getOrElse(0)
Some(currentResult)
}else{
historyValue
}
}
val resuleDS:DStream[(String,Int)]=lines.flatMap(_.split(" "))
.map((_,1))
//updateFunc:(Seq[v],Option[s]) =>option[s]
.updateStateByKey(updateFunc)
//TODO 3.输出结果
resuleDS.print()
//TODO 4.启动并等待结束
ssc.start()
ssc.awaitTermination()//注意:流式应用程序启动之后需要一直运行等待停止、等待到来
//TODO 5.关闭资源
ssc.stop(stopSparkContext = true,stopGracefully = true)//优雅关闭
}
}
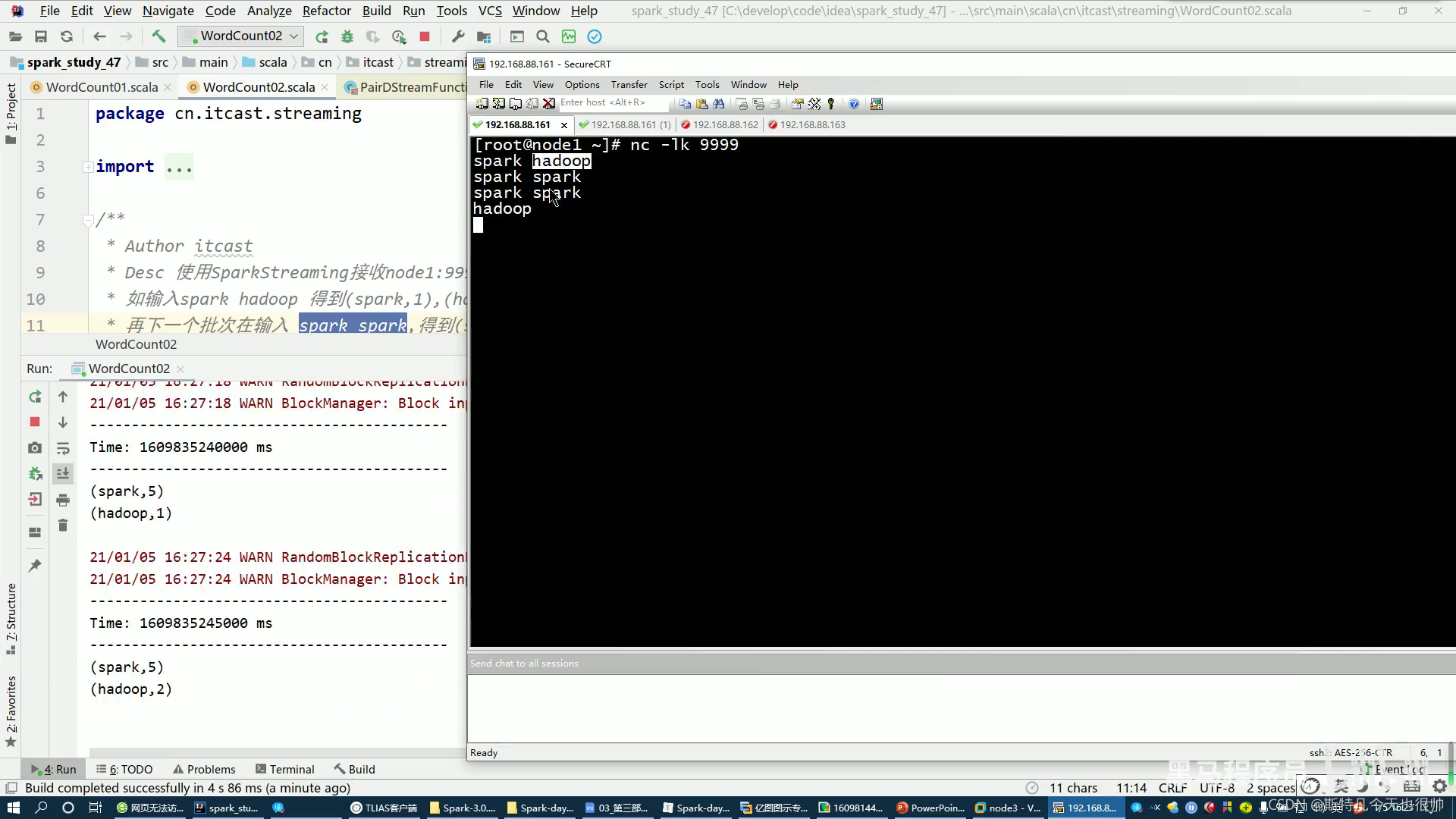
演示:
(1)如图,不同批次实现了累计
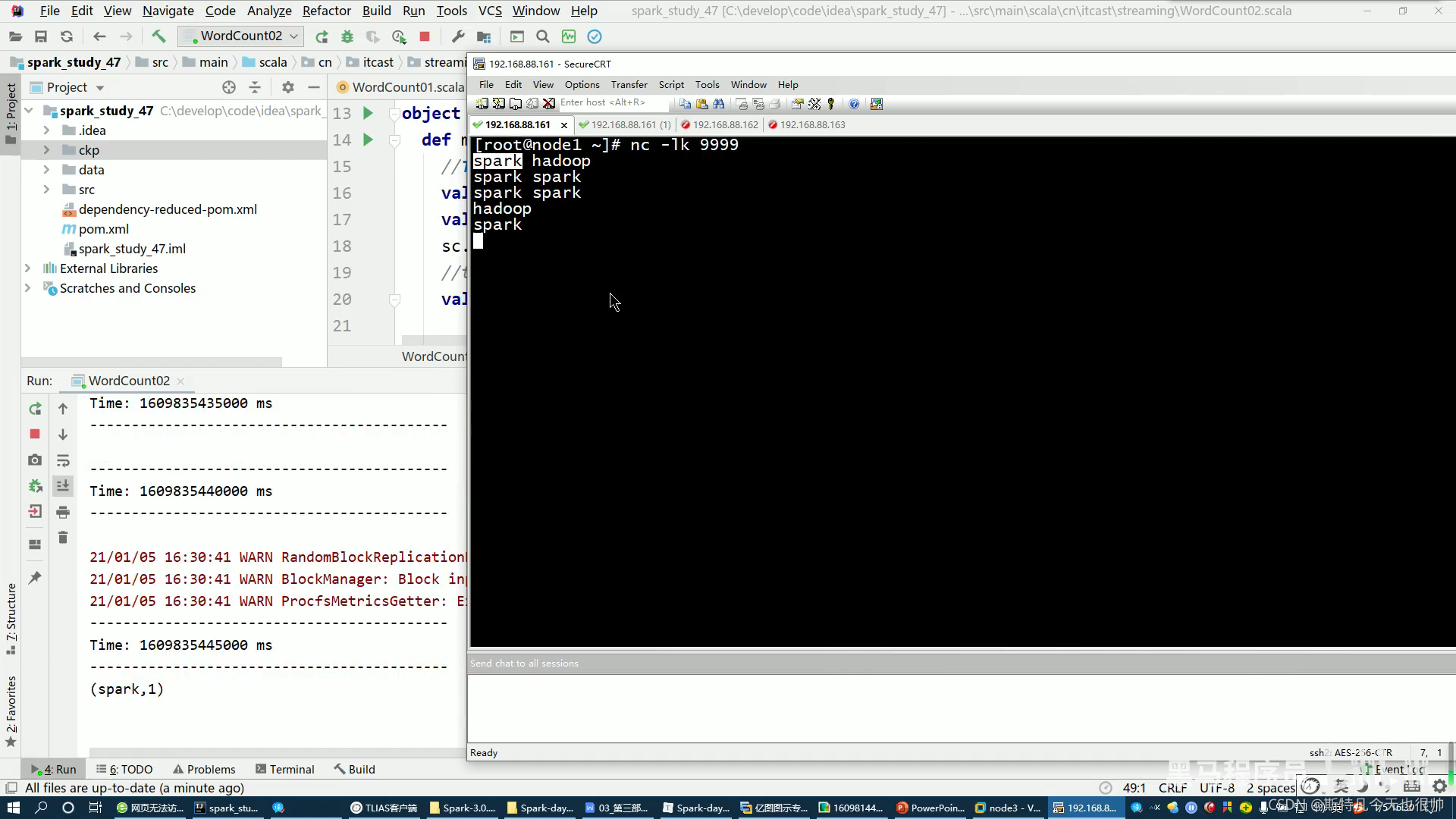
(2)停掉之后再重新启动,后之前的数据恢复不了了,就是说历史状态维护只能在当前应用
二、mapWithState
