Delta LakeのDML実装原則(更新、削除、マージ)の詳細な理解
過去のメモリビッグデータ
DeltaLakeは、DELETE、UPDATE、MERGEなどのDMLコマンドをサポートしており、CDC、監査、ガバナンス、GDPR / CCPAワークフローなどのビジネスシナリオを簡素化します。この記事では、これらのDMLコマンドの使用方法を示し、これらのコマンドの実装を紹介し、対応するコマンドのパフォーマンスチューニング手法もいくつか紹介します。
デルタ湖:基本原則
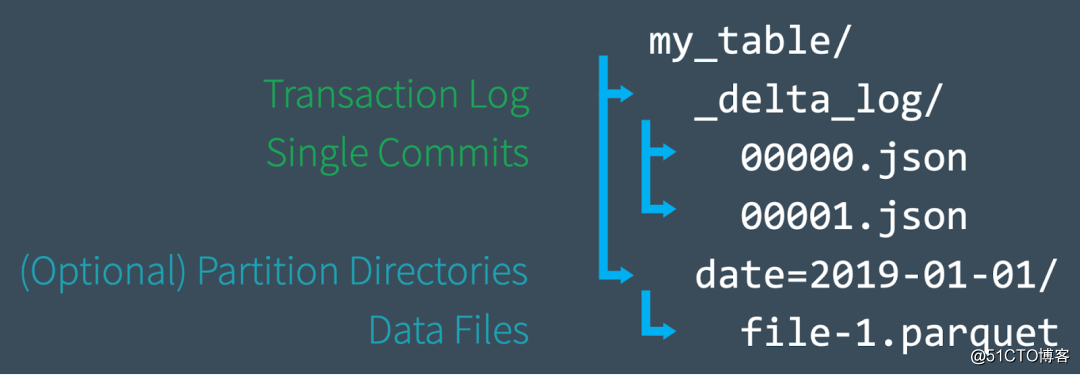
Delta Lakeを学習しているだけの場合は、この章を読んで、DeltaLakeの基本原則をすばやく理解できます。このセクションでは、主にファイルレベルでのDeltaLakeテーブルの構築について説明します。
新しいテーブルを作成すると、Deltaはデータを一連のParquetファイルに保存し、テーブルのルートディレクトリに_delta_logフォルダーを作成します。このフォルダーには、Delta Lakeのトランザクションログが含まれ、ACIDトランザクションログは、対応するテーブルごとに記録されます。変化する。テーブルを変更すると(たとえば、新しいデータを追加したり、更新、マージ、削除を実行したりすることで)、DeltaLakeは新しい各トランザクションのレコードを番号付きのJSONファイルとしてdelta_logフォルダーに00 ... 00000から保存します。 json名が始まり、その後に00 ... 00001.json、00 ... 00002.jsonなどが続きます。10トランザクションごとに、Deltaはdelta_logフォルダーに「チェックポイント」Parquetファイルも生成します。テーブルの状態をすばやく再作成します。
最後に、Delta Lakeテーブルにクエリを実行すると、最初にトランザクションログを読み取って、クラウドオブジェクトストレージ内のすべてのファイルを一覧表示する必要なしに、テーブルの最新バージョンを構成するデータファイルをすばやく特定できます。これにより、クエリのパフォーマンスが大幅に向上します。 。DML操作を実行すると、Delta Lakeは元のファイルを変更する代わりに新しいファイルを作成し、トランザクションログを使用して、新しいファイルなど、これらすべての操作を記録します。これについて詳しく知りたい場合は、記事「Apache Spark DeltaLakeトランザクションログの詳細な理解」を参照してください。
さて、前の基本的な紹介で、DeltaLakeのDMLコマンドの使用方法とその背後にある動作原理を紹介できます。次の例では、SQLを使用して操作します。これには、Delta Lake0.7.0とApacheSpark 3.0を使用する必要があります。詳細については、「DeltaLakeでSparkSQLDDLとDMLを有効にする」を参照してください。
UPDATEの使用と内部原則
UPDATE操作を使用して、フィルター条件(述部とも呼ばれます)に一致する行を選択的に更新できます。次のコードは、UPDATEステートメントの一部として各タイプの述部を使用する方法を示しています。Delta Lakeの更新はPython、Scala、SQLで使用できますが、この記事の目的上、ここではSQLを使用してその使用法を紹介するだけです。
-- Update events
UPDATE events SET eventType = 'click' WHERE eventType = 'click'
UPDATE: Under the hoodDelta LakeでのUPDATEの実装は、次の2つのステップに分かれています。
•最初に、述語に一致し、更新が必要なデータを含むファイルを見つけて選択します。このプロセスでは、DeltaLakeはデータスキップテクノロジーを使用してこのプロセスを高速化できます。データスキップ技術は、レンガの数の商務省でのみ利用可能であるようであり、オープンソースバージョンは見られていないようです。
•一致する各ファイルをメモリに読み込み、関連する行を更新して、結果を新しいデータファイルに書き込みます。
全体のプロセスは次のとおりです。
Delta LakeがUPDATEを正常に実行すると、トランザクションログにコミットが追加され、古いデータファイルを置き換えるために新しいデータファイルが今後使用されることを示します。ただし、古いデータファイルは削除されません。代わりに、トゥームストーンとしてマークされています。つまり、このファイルは古いバージョンのテーブルデータファイルにのみ属し、現在のバージョンのデータファイルには属していません。Delta Lakeはこれを使用して、データバージョン管理とタイムトラベルを提供できます。
UPDATE +デルタレイクタイムトラベル=簡単なデバッグ
古いデータファイルを保持すると、いつでもDelta Lakeタイムトラベルを使用して履歴に戻り、以前のバージョンのテーブルをクエリできるため、デバッグに非常に役立ちます。ある日、誤ってテーブルを誤って更新し、何が起こったのかを知りたい場合は、2つのバージョンのテーブルを簡単に比較できます。
SELECT * FROM events VERSION AS OF 12更新:パフォーマンスチューニング
Delta LakeのUPDATEコマンドのパフォーマンスを向上させる主な方法は、検索スペースを狭めるために述語を追加することです。検索が具体的であればあるほど、DeltaLakeがスキャンおよび/または変更する必要のあるファイルは少なくなります。
Databricksの商用バージョンのDeltaLakeには、データスキップの改善、ブルームフィルターの使用、Z-Order Optimizeなど、いくつかのエンタープライズ拡張機能があります。Z-OrderOptimizeは、各データファイルのレイアウトを再編成して、類似した列の値を作成します。最大の効率のために互いに近くに。
DELETEの使用と内部原則
DELETEコマンドを使用して、述語(フィルター条件)に基づいて任意の行を選択的に削除できます。
DELETE FROM events WHERE date < '2017-01-01'偶発的な削除操作を回復したい場合は、次のPythonコードスニペットに示すように、タイムトラベルを使用してテーブルを元の状態にロールバックできます。
# Read correct version of table into memory
dt = spark.read.format("delta") \
.option("versionAsOf", 4) \
.load("/tmp/loans_delta")
# Overwrite current table with DataFrame in memory
dt.write.format("delta") \
.mode("overwrite") \
.save(deltaPath)
削除:ボンネットの下
DELETEはUPDATEと同じように機能します。Delta Lakeはデータを2回スキャンします。最初のスキャンは、述語条件に一致する行を含むデータファイルを特定することです。2回目のスキャンでは、一致するデータファイルがメモリに読み込まれます。このとき、Delta Lakeは関連する行を削除してから、削除されていないデータをディスク上の新しいファイルに書き込みます。
Delta Lakeが削除操作を正常に完了した後、古いデータファイルは削除されません。古いデータファイルはディスクに残りますが、これらのファイルはDelta Lakeトランザクションログにトゥームストーンとして記録されます(アクティブテーブルの一部ではなくなります)。タイムトラベル機能を使用して以前のバージョンのデータにジャンプする必要がある場合があるため、これらの古いファイルはすぐには削除されないことに注意してください。特定の期間を超えるファイルを削除する場合は、VACUUMコマンドを使用できます。
DELETE + VACUUM:古いファイルをクリーンアップします
VACUUMコマンドを実行して、次の条件を満たすすべてのデータファイルを完全に削除します。
•アクティブテーブルの一部ではなくなり、
•保持しきい値を超えました(デフォルトは7日です)。
Delta Lakeは古いファイルを自動的に削除しません。以下に示すように、VACUUMコマンドを自分で実行する必要があります。デフォルト値とは異なる保持期間を指定したい場合は、それをパラメーターとして指定できます。
from delta.tables import *
# vacuum files not required by versions older than the default
# retention period, which is 168 hours (7 days) by default
dt.vacuum()
deltaTable.vacuum(48) # vacuum files older than 48 hours注:VACUUMコマンドの実行時に指定された保持時間が0時間の場合、最新バージョンのテーブル内の未使用のファイルはすべて削除されます。このコマンドを実行するときは、対応するテーブルへの書き込み操作がないことを確認してください。そうしないと、データが失われる可能性があります。
DELETE:パフォーマンスの調整
はUPDATEコマンドと同じです。DeltaLakeDELETE操作のパフォーマンスを向上させる主な方法は、検索スペースを狭めるために述語を追加することです。Databricksの商用バージョンのDeltaLakeには、データスキップの改善、ブルームフィルターの使用、Z-Order Optimizeなど、いくつかのエンタープライズ拡張機能があります。
マージの使用と内部原則
Delta LakeのMERGEコマンドを使用すると、実際にはUPDATEとINSERTを組み合わせたアップサートのセマンティクスを実現できます。アップサートの意味を理解するために、テーブル(ターゲットテーブル)と、新しいレコードと既存のレコードの更新を含むソーステーブルがあるとします。アップサートは次のように機能します。
•ソーステーブルのレコードがターゲットテーブルの既存のレコードと一致すると、DeltaLakeはレコードを更新します。
•一致するものがない場合、DeltaLakeは新しいレコードを挿入します。
MERGE INTO events
USING updates
ON events.eventId = updates.eventId
WHEN MATCHED THEN UPDATE
SET events.data = updates.data
WHEN NOT MATCHED THEN
INSERT (date, eventId, data) VALUES (date, eventId, data) Delta LakeのMERGEコマンドは、ワークフローを大幅に簡素化します。
マージ:ボンネットの下
Delta Lakeは、次の2つの手順でMERGEを実装します。
•ターゲットテーブルとソーステーブルの間で内部結合を実行して、一致するすべてのファイルを選択します。
•ターゲットテーブルで選択したファイルとソーステーブルの間で外部結合を実行し、更新/削除/挿入されたデータを書き出します。
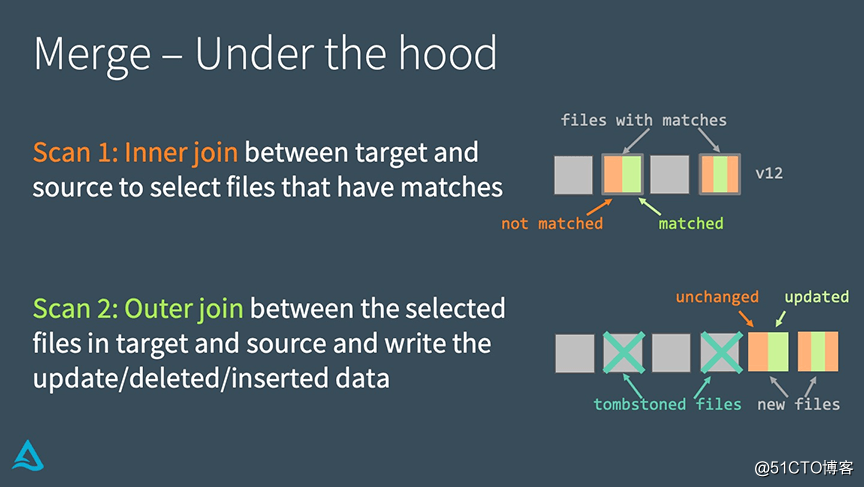
MERGEとUPDATEまたはDELETEの実装の主な違いは、joinを使用することです。この事実により、パフォーマンスを向上させるためにいくつかの独自の戦略を使用できます。
MERGE:パフォーマンスチューニング
MERGEの実行パフォーマンスを向上させるには、上記の2つの結合のどちらがプログラムの実行に影響するかを理解する必要があります。
内部結合がMERGE実行のボトルネックである場合(たとえば、Delta Lakeで書き換える必要のあるファイルを見つけるのに時間がかかりすぎる場合)、次の戦略を使用してそれを解決できます。
•フィルター条件を追加して検索スペースを削減します。
•シャッフルパーティションの数を
調整します。
•ブロードキャスト結合のしきい値を調整します。•テーブルに小さなファイルが多数ある場合は、最初にそれらを圧縮してマージできますが、そうではありません。 Delta Lakeはファイル全体をコピーして再書き込みする必要があるため、圧縮しすぎる大きなファイル。
外部結合がMERGE実行のボトルネックである場合(たとえば、ファイルの書き換えに時間がかかりすぎる場合)、次の戦略を使用してそれを解決できます。
•シャッフルパーティションの数を調整します。
•このパーティションテーブルは、多数の小さなファイルを生成する可能性があります。
•ファイルを書き込む前に自動再パーティション化をオンにして、Reduceによって生成されるファイルを減らします。
•ブロードキャストしきい値を調整します。完全外部結合を使用する場合、Sparkはブロードキャスト結合を実行できませんが、
右外部結合を使用する場合、Sparkを使用できます。実際の状況に応じてブロードキャストしきい値を調整できます。•キャッシュソーステーブル/DataFrame。•
キャッシュソーステーブル。2回目のスキャン時間を高速化しますが、キャッシュの一貫性の問題が発生する可能性があるため、ターゲットテーブルをキャッシュしないように注意してください。
総括する
Delta Lakeは、UPDATE、DELETE、MERGE INTOなどのDMLコマンドをサポートしており、多くの一般的なビッグデータ操作のワークフローを大幅に簡素化します。この記事では、Delta Lakeでこれらのコマンドを使用する方法を示し、これらのDMLコマンドの実装原則を紹介し、いくつかのパフォーマンスチューニング手法を提供しました。