Apache Spark 3.0動的パーティションプルーニング(動的パーティションプルーニング)に関する記事
過去のメモリビッグデータ過去のメモリビッグデータ
静的パーティションプルーニング
照会するときに使用されるスパークを持っている誰もが、そのスパークSQLがサポートするパーティションの切断を知っている。例えば、我々は次のクエリを持っている場合:
SELECT Sales_iteblog FROM WHERE DAY_OF_WEEK =「月」
自動的に次の最適化を実行しますスパーク: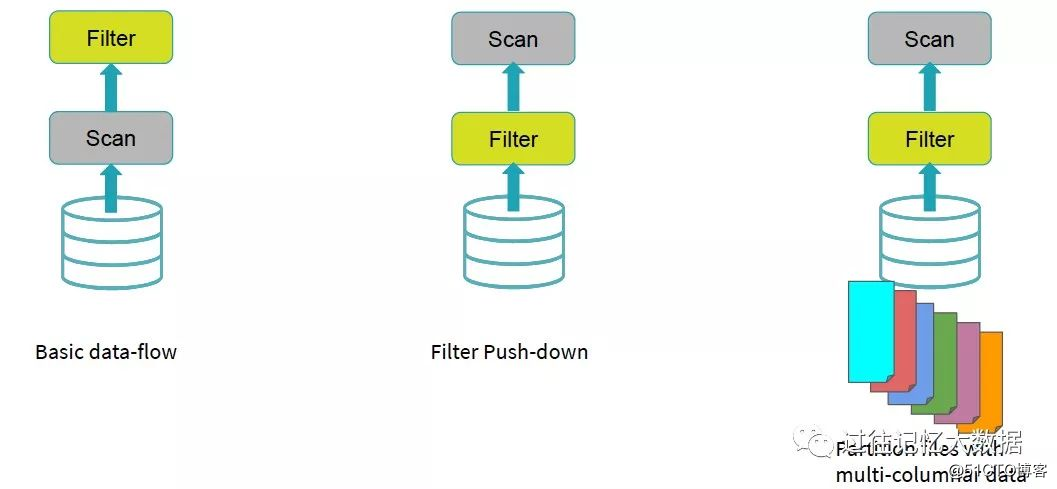
あなたが火花を学びたい場合やHadoop in timeまたはHbase関連の記事については、WeChatパブリックアカウントに注意してください。iteblog_hadoop
上の図からわかるように、Sparkは、SQLのコンパイル時に、フィルター演算子をデータソースに自動的にプッシュします。つまり、フィルター操作は次のようになります。 Scanの前に実行され、day_of_week = 'Mon'のすべてのデータを取り出し、不要な他のデータを取り出して、Spark SQLで処理されるデータが少なくなり、SQL全体のクエリデータが速くなるようにします。すべてこれはコンパイル時です。したがって、これは静的パーティションプルーニングと呼ばれます。
上記のSQLクエリはSparkのオペレーターによってプッシュダウンされ、クエリパフォーマンスの向上に対応することができました。実世界のデータのクエリは、すべてその単純ではない。しかし、のは、以下のクエリステートメントを見てみましょう:
SELECT Date.day_of_week =「月」参加日販売から
貧しいクエリエンジンがこれを行うに: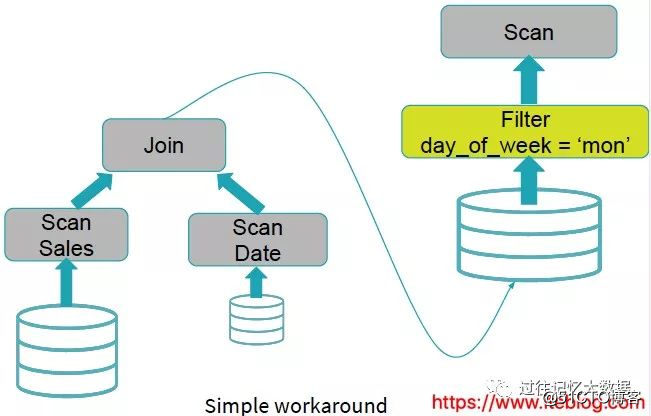
あなたは、Sparkについて学びたいのであれば、 HadoopまたはHbaseに関連する記事については、WeChatパブリックアカウントに従ってください:iteblog_hadoop
上の図からわかるように、クエリエンジンはフィルタ条件Date.day_of_week = 'Mon'を直接無視します。2つのテーブルが結合され、結合の結果がフィルタリングされます。これにより、多くの無効な計算が発生する可能性があります。 。Date.day_of_week= 'Mon'の場合、多くの役に立たないデータを除外できます。これにより、クエリのパフォーマンスが確実に向上します。この状況はSparkSQLで適切に処理できます。Date.day_of_week= 'Mon'フィルター条件を日付テーブルのスキャンの前にプッシュします。Spark 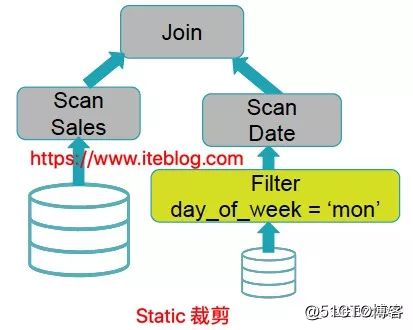
、Hadoop、またはHbase関連の記事について知りたい場合は、WeChatpublicに注意してください。アカウント:iteblog_hadoop
動的パーティションプルーニング(動的パーティションプルーニング)
上記のSpark SQLによって実行されたオペレーターのプッシュダウンは、クエリのパフォーマンスを向上させることができなくなりましたか?役に立たないデータをさらに除外するためのより良い方法はありますか?これは、この記事で紹介する動的パーティション調整です。動的パーティショントリミングの機能はSpark3.0で導入されました。詳細については、SPARK-11150およびSPARK-28888を参照してください。
動的パーティショントリミングとは何ですか?いわゆる動的パーティション切断は、実行時(実行時)に推測された情報に基づいて、さらにパーティションを切断します。たとえば、次のクエリがあります。
SELECT * FROM dim_iteblog
JOIN fact_iteblog
ON (dim_iteblog.partcol = fact_iteblog.partcol)
WHERE dim_iteblog.othercol > 10動的クエリの実行プランは次のとおりです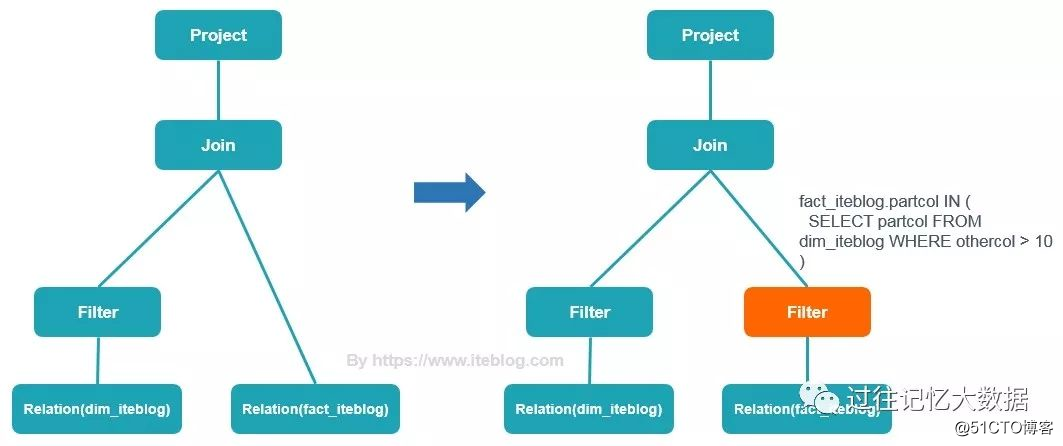
。Spark、Hadoop、またはHbase関連の記事について時間内に知りたい場合は、WeChatパブリックアカウントに注意してください。iteblog_hadoop
上記からわかるように、動的パーティションを調整します。 、Sparkは、実行時に最初にfact_iteblogテーブルのpartcolをチェックできます。一度フィルタリングしてからdim_iteblogテーブルに結合すると、特にfact_iteblogテーブルに多くの役に立たないデータがある場合、このパフォーマンスは一般的に向上すると考えられます。 。パフォーマンスの向上は非常に大きくなります。
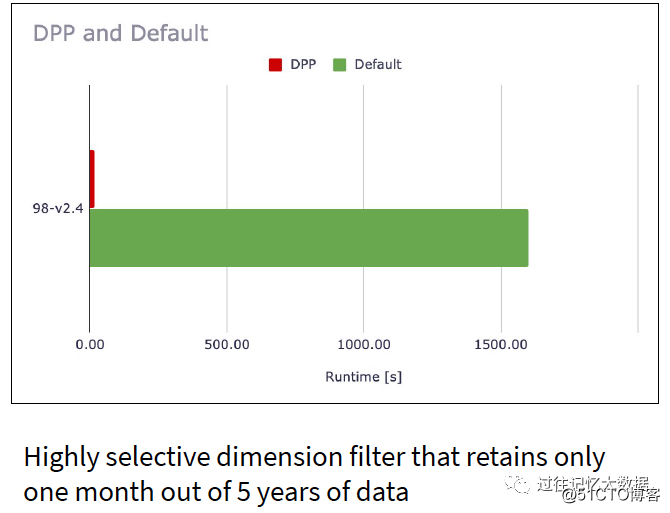
Databricksは、i3.xlargeとして構成された10個のクラスターでTPC-DSテストを実施し、102個のクエリで60個のクエリのクエリパフォーマンスがSpark 2.4と比較して2〜18倍向上したと結論付けました。
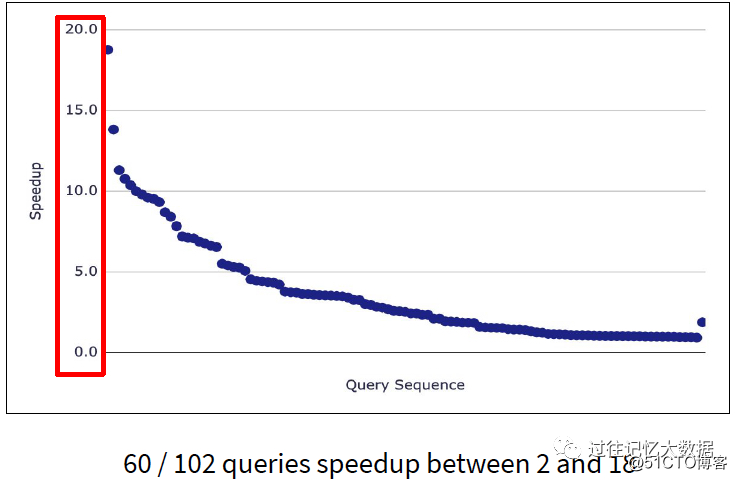
クエリ98のクエリでは、パフォーマンスが100倍向上しました。