 |
ブロガーが3年間かけて丁寧に作り上げた書籍『ビッグデータプラットフォームのアーキテクチャとプロトタイプの実現:データセンター構築の実戦』が、有名IT書籍ブランド電子工業出版社より出版されました。データプラットフォームは難しすぎる!エンジニアリングプロトタイプを送ってください!"書籍の詳細については、JD 書籍購入リンク: https://item.jd.com/12677623.htmlをご覧ください。左側の QR コードをスキャンして、JD 携帯電話書籍購入ページに入ります。 |
Apache Hudi の DeltaStreamer は、ほぼリアルタイムでデータを取り込み、それを Hudi テーブルに書き込むツール クラスです。これにより、データをレイクにストリーミングし、それを Hudi テーブルとして保存する操作が簡素化されます。リリース以来、Hudi は Based on を追加しまし0.10.0たDebezium の CDC データ処理機能により、Debezium によって収集された CDC データを Hudi テーブルに直接ログ記録でき、ソース ビジネス データベースから Hudi データ レイクへのデータ統合作業が大幅に簡素化されます。この記事は Apache Hudi パブリック アカウントで公開されました。この記事のアドレス: https://laurence.blog.csdn.net/article/details/132011197、転載する場合は出典を示してください。
その一方で、すぐに使用できる、運用とメンテナンスがゼロという極めて優れた経験のおかげで、ますます多くのクラウド ユーザーがサーバーレス製品を採用し始めています。Amazon クラウド プラットフォーム上の EMR は、さまざまな主流のビッグ データ ツールを統合するコンピューティング プラットフォームです。リリース以来6.6.0、EMR はサーバーレス バージョンを開始し、サーバーレス Spark オペレーティング環境を提供します。ユーザーは、Hadoop/Spark クラスターを維持する必要はありません。 Spark ジョブを簡単に送信します。
1 つは「フル構成」の Hudi ツール クラスで、もう 1 つは「すぐに使用できる」 Spark オペレーティング環境です。この 2 つを組み合わせると、CDC 処理コードを作成したり、Spark クラスターを構築したりする必要はありません。 1 つのコマンドだけで簡単に実装できます CDC データをレイクに入力することは、非常に魅力的な技術ソリューションです。この記事では、このソリューションの全体的なアーキテクチャと実装の詳細について詳しく紹介します。
1. 全体構成
0.10.0このバージョンで Apache Huid によって導入された DeltaStreamer CDC は、CDC データ処理チェーン全体のエンド リンクです。その中での DeltaStreamer の位置と役割を誰もが明確に理解できるようにするために、完全なアーキテクチャを確認する必要があります。
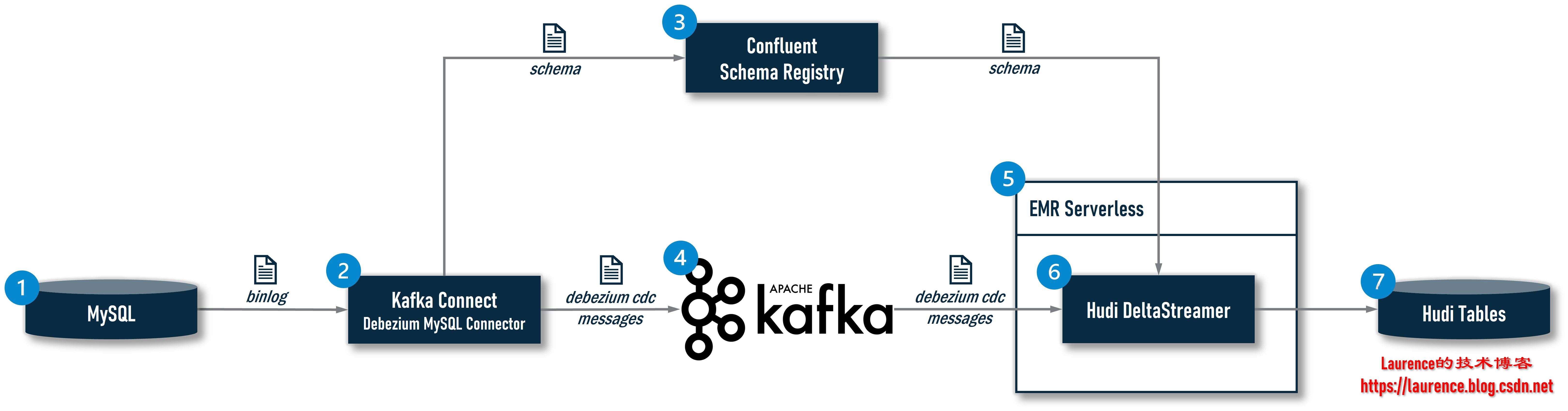
①: MySQL はビジネス データベースであり、CDC データのソースです。
②: システムは CDC インジェスト ツールを使用して MySQL のバイナリをリアルタイムで読み取ります。業界の主流の CDC インジェスト ツールには、Debezium、Maxwell、FlinkCDC などが含まれます。このアーキテクチャでは、Debezium MySQL コネクタがインストールされた Kafka Connect が選択された;
③: 現在、上流ビジネス システムのスキーマ変更をより適切に制御し、より制御可能なスキーマ進化を実現するために、スキーマ レジストリを導入する CDC データ インジェスト ソリューションが増え始めています。オープン ソース コミュニティでは、より主流の製品は Confluent Schema Registry であり、現在 Hudi の DeltaStreamer は Confluent Schema Registry のみをサポートしているため、このアーキテクチャにも選択されています。スキーマ レジストリの導入後、Kafka Connect がレコードをキャプチャすると、対応するスキーマがローカル スキーマ キャッシュに既に存在するかどうかが最初にチェックされます。存在する場合は、ローカル キャッシュからスキーマ ID を直接取得します。存在しない場合は、スキーマ ID が保存されます。スキーマ レジストリに送信すると、スキーマ レジストリはスキーマの登録を完了し、生成されたスキーマ ID を Kafka Connect に返し、Kafka Connect はスキーマ ID に基づいて元の CDC データをカプセル化 (シリアル化) します。 まず、スキーマを追加します。 2 つ目は、メッセージが Avro 形式で配信される場合、Kafka Connect は Avro メッセージのスキーマ部分を削除し、生データのみを保持します。これは、スキーマ情報がプロデューサーとコンシューマーにローカルにキャッシュされているか、または保存されている可能性があるためです。スキーマ レジストリを通じて一度に取得できるため、Raw Data の送信を伴う必要がなく、Avro メッセージのサイズが大幅に削減され、送信効率が向上します。これらのジョブは、Confluent が提供する Avro Converter() を通じてio.confluent.connect.avro.AvroConverter実行されます。
④: Kafka Connect は、カプセル化された Avro メッセージを Kafka に配信します。
⑤: EMR Serverless は、DeltaStreamer 用のサーバーレス Spark オペレーティング環境を提供します。
⑥: Hudi の DeltaStreamer は、EMR サーバーレス環境で Spark ジョブとして実行され、Kafka から Avro メッセージを読み取った後、Confluent が提供する Avro デシリアライザー ( ) を使用して Avro メッセージを解析し、スキーマ ID と生データを取得しますio.confluent.kafka.serializers.KafkaAvroDeserializer。また、最初に ID に従ってローカル スキーマ キャッシュ内の対応するスキーマを検索します。見つかった場合は、スキーマに従って生データを逆シリアル化します。見つからない場合は、スキーマ レジストリにスキーマを取得するよう要求します。 ID に対応させてデシリアライズします。
⑦: DeltaStreamer は、解析されたデータを S3 に保存されている Hudi テーブルに書き込みます。データ テーブルが存在しない場合は、自動的にテーブルを作成し、Hive MetaStore に同期します。
2. 環境の準備
紙面の都合上、本記事ではリンク①、②、③、④の構築については紹介しませんが、以下のドキュメントを参照して、ご自身で完全なテスト環境を構築してください。
①MySQL:テスト目的であればDebeziumが提供する公式Dockerイメージの使用を推奨、構築作業については公式ドキュメントを参照してください(以下の運用例で処理しているCDCデータは、Debeziumのインベントリデータベースから取得したものです) MySQL イメージ);
②Kafka Connect: テスト目的のみ、Confluent が提供する公式 Docker イメージを使用することをお勧めします。構築操作については、公式ドキュメントを参照するか、AWS でホストされている Kafka Connect: Amazon MSK Connect を使用してください。Debezium MySQL Connector と Confluent Avro Converter という 2 つのプラグインを Kafka Connect にインストールする必要があるため、これら 2 つのプラグインは公式イメージに基づいて手動で追加する必要があることに注意してください。
③Confluent スキーマ レジストリ: テスト目的のみの場合は、 Confluent が提供する公式の Docker イメージを使用することをお勧めします。構築操作はその公式ドキュメントを参照できます。
④Kafka: テスト目的のみの場合は、 Confluent が提供する公式 Docker イメージを使用することをお勧めします。構築操作については、公式ドキュメントを参照するか、AWS: Amazon MSK でホストされている Kafka を使用してください。
上記の作業が完了すると、DeltaStreamer CDC ジョブを開始するために必要な条件である 2 つの依存サービス「Confluent Schema Registry」と「Kafka Bootstrap Servers」のアドレスを取得し、次の形式で DeltaStreamer ジョブに渡します。パラメータの。
3. グローバル変数を設定する
環境準備が整ったら、⑤、⑥、⑦の作業を開始します。この記事のすべての操作はコマンドによって完了し、シェル スクリプトの形式で読者に提供されます。実際の操作手順のシリアル番号はスクリプトにマークされます。2 つのオプションの操作の場合は、文字 a/b。一部の操作には、読者が参照できる例もあります。スクリプトの移植性を高めるため、環境関連の依存関係やユーザーによるカスタマイズが必要な設定項目を抽出し、グローバル変数の形で一元的に設定します。変更する必要があるのは、特定のコマンドではなく、次のグローバル変数だけです。
| 変数 | 説明する | 時間を設定する |
|---|---|---|
| APP_NAME | ユーザーがこのアプリケーションに割り当てた名前 | 事前に設定した |
| APP_S3_HOME | このアプリケーションに対してユーザーが設定した S3 専用バケット | 事前に設定した |
| APP_LOCAL_HOME | このアプリケーションに対してユーザーが設定したローカル作業ディレクトリ | 事前に設定した |
| SCHEMA_REGISTRY_URL | ユーザー環境の Confluent スキーマ レジストリ アドレス | 事前に設定した |
| KAFKA_BootSTRAP_SERVERS | ユーザー環境内の Kafka Bootstrap サーバーのアドレス | 事前に設定した |
| EMR_SERVERLESS_APP_SUBNET_ID | 作成するEMRサーバーレスアプリケーションが属するサブネットのID | 事前に設定した |
| EMR_SERVERLESS_APP_SECURITY_GROUP_ID | 作成するEMRサーバーレスアプリケーションが所属するセキュリティグループのID | 事前に設定した |
| EMR_SERVERLESS_APP_ID | 作成するEMRサーバーレスアプリケーションのID | その過程で生み出される |
| EMR_SERVERLESS_EXECUTION_ROLE_ARN | 作成するEMRサーバーレス実行ロールのARN | その過程で生み出される |
| EMR_SERVERLESS_JOB_RUN_ID | EMR サーバーレス ジョブを送信した後に返されるジョブ ID | その過程で生み出される |
次に実践段階に入りますAWS CLIがインストールされ、ユーザー認証情報が設定されたLinux 環境が必要です(Amazon Linux2 を推奨) SSH でログイン後、まずコマンドを使用してsudo yum -y install jqjson を操作するためのコマンドライン ツールをインストールしますファイル: jq (後続のスクリプトで使用されます)、次に上記のグローバル変数をすべてエクスポートします (AWS アカウントとローカル環境に従ってコマンドラインの対応する値を置き換えてください):
# 实操步骤(1)
export APP_NAME='change-to-your-app-name'
export APP_S3_HOME='change-to-your-app-s3-home'
export APP_LOCAL_HOME='change-to-your-app-local-home'
export SCHEMA_REGISTRY_URL='change-to-your-schema-registry-url'
export KAFKA_BOOTSTRAP_SERVERS='change-to-your-kafka-bootstrap-servers'
export EMR_SERVERLESS_APP_SUBNET_ID='change-to-your-subnet-id'
export EMR_SERVERLESS_APP_SECURITY_GROUP_ID='change-to-your-security-group-id'
以下に例を示します。
# 示例(非实操步骤)
export APP_NAME='apache-hudi-delta-streamer'
export APP_S3_HOME='s3://apache-hudi-delta-streamer'
export APP_LOCAL_HOME='/home/ec2-user/apache-hudi-delta-streamer'
export SCHEMA_REGISTRY_URL='http://localhost:8081'
export KAFKA_BOOTSTRAP_SERVERS='localhost:9092'
export EMR_SERVERLESS_APP_SUBNET_ID='subnet-0a11afe6dbb4df759'
export EMR_SERVERLESS_APP_SECURITY_GROUP_ID='sg-071f18562f41b5804'
EMR_SERVERLESS_APP_ID、についてはEMR_SERVERLESS_EXECUTION_ROLE_ARN、EMR_SERVERLESS_JOB_RUN_ID3 つの変数が後続の操作で生成され、エクスポートされます。
4. 専用の作業ディレクトリとバケットを作成する
ベスト プラクティスとして、最初に、アプリケーション (ジョブ) 用の専用のローカル作業ディレクトリ (つまり、設定されたAPP_LOCAL_HOMEパス) と S3 ストレージ バケット (つまり、APP_S3_HOME設定されたバケット) を作成します (アプリケーション スクリプト、構成ファイル、依存パッケージ)。 、ログ、生成されたデータはすべて専用のディレクトリとバケットに保存されるため、保守が簡単です。
# 实操步骤(2)
mkdir -p $APP_LOCAL_HOME
aws s3 mb $APP_S3_HOME
5.EMRサーバーレス実行ロールの作成
EMR サーバーレス ジョブを実行するには、IAM ロールを設定する必要があります。このロールにより、EMR サーバーレス ジョブに AWS 関連のリソースにアクセスする権限が与えられます。少なくとも DeltaStreamer CDC ジョブを割り当てる必要があります。
- S3 専用バケットの読み取りおよび書き込み権限
- Glue データ カタログへの読み取りおよび書き込みアクセス
- Glue スキーマ レジストリへの読み取りおよび書き込みアクセス
EMR Serverless の公式ドキュメントに従ってこのロールを手動で作成し、その ARN を変数としてエクスポートできます (AWS アカウント環境に応じてコマンドラインの対応する値を置き換えてください)。
# 实操步骤(3/a)
export EMR_SERVERLESS_EXECUTION_ROLE_ARN='change-to-your-emr-serverless-execution-role-arn'
以下に例を示します。
# 示例(非实操步骤)
export EMR_SERVERLESS_EXECUTION_ROLE_ARN='arn:aws:iam::123456789000:role/EMR_SERVERLESS_ADMIN'
このロールを手動で作成するのは面倒であることを考慮して、この記事では、AWS アカウントに管理者権限を持つロールを作成できる次のスクリプトを提供します。これにより、このセクションの作業をすぐに完了できるようになります (注: このロールEMR_SERVERLESS_ADMINはは最高の権限を持っています。慎重に使用する必要があります。簡単な検証を完了した後も、運用環境で権限が厳密に制限された専用の実行ロールを構成する必要があります)。
# 实操步骤(3/b)
EMR_SERVERLESS_EXECUTION_ROLE_NAME='EMR_SERVERLESS_ADMIN'
cat << EOF > $APP_LOCAL_HOME/assume-role-policy.json
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "EMRServerlessTrustPolicy",
"Effect": "Allow",
"Principal": {
"Service": "emr-serverless.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
EOF
jq . $APP_LOCAL_HOME/assume-role-policy.json
export EMR_SERVERLESS_EXECUTION_ROLE_ARN=$(aws iam create-role \
--no-paginate --no-cli-pager --output text \
--role-name "$EMR_SERVERLESS_EXECUTION_ROLE_NAME" \
--assume-role-policy-document file://$APP_LOCAL_HOME/assume-role-policy.json \
--query Role.Arn)
aws iam attach-role-policy \
--policy-arn "arn:aws:iam::aws:policy/AdministratorAccess" \
--role-name "$EMR_SERVERLESS_EXECUTION_ROLE_NAME"
6. EMRサーバーレスアプリケーションの作成
EMR サーバーレスにジョブを送信する前に、EMR サーバーレス アプリケーションを作成する必要があります。これは EMR サーバーレスの概念であり、仮想 EMR クラスターとして理解できます。アプリケーションを作成するときは、EMR バージョン、ネットワーク構成、クラスター サイズ、予熱されたノードなどの情報を指定する必要があります。通常、作成作業を完了するには次のコマンドのみが必要です。
# 示例(非实操步骤)
aws emr-serverless create-application \
--name "$APP_NAME" \
--type "SPARK" \
--release-label "emr-6.11.0"
ただし、この方法で作成されたアプリケーションにはネットワーク構成がありません。DeltaStreamer CDC ジョブは特定の VPC にある Confluent スキーマ レジストリと Kafka ブートストラップ サーバーにアクセスする必要があるため、アプリケーションのサブネットとセキュリティ グループを明示的に設定する必要があります。 DeltaStreamer はこれら 2 つのサービスと通信できます。したがって、次のコマンドを使用して、特定のネットワーク構成でアプリケーションを作成する必要があります。
# 实操步骤(4)
cat << EOF > $APP_LOCAL_HOME/create-application.json
{
"name":"$APP_NAME",
"releaseLabel":"emr-6.11.0",
"type":"SPARK",
"networkConfiguration":{
"subnetIds":[
"$EMR_SERVERLESS_APP_SUBNET_ID"
],
"securityGroupIds":[
"$EMR_SERVERLESS_APP_SECURITY_GROUP_ID"
]
}
}
EOF
jq . $APP_LOCAL_HOME/create-application.json
export EMR_SERVERLESS_APP_ID=$(aws emr-serverless create-application \
--no-paginate --no-cli-pager --output text \
--release-label "emr-6.11.0" --type "SPARK" \
--cli-input-json file://$APP_LOCAL_HOME/create-application.json \
--query "applicationId")
7. Apache Hudi DeltaStreamer CDC ジョブを送信します。
アプリケーションを作成した後、ジョブを送信できます。Apache Hudi DeltaStreamer CDC は、多くの構成項目を含む比較的複雑なジョブです。これは、Hudi 公式ブログで示されている例からわかります。私たちが行う必要があるのは: スパークを使用することです-submit コマンドによって送信されたジョブは、EMR サーバーレス ジョブに「変換」されます。
7.1 ジョブ記述ファイルの準備
コマンド ラインを使用して EMR サーバーレス ジョブを送信するには、JSON 形式でジョブ記述ファイルを提供する必要があります。通常、spark-submit コマンド ラインで構成されたパラメーターは、このファイルによって記述されます。DeltaStreamer ジョブは設定項目が多いため、紙面の都合上、一つ一つ説明することができませんが、以下のジョブ記述ファイルと Hudi の公式ブログが提供するネイティブ Spark ジョブを比較していただくと理解していただけると思います。比較的簡単に職務内容を説明し、ファイルの役割を説明します。
<your-xxx>次のスクリプトを実行するときは、AWS アカウントとローカル環境に応じてスクリプトのすべての部分を置き換えてください。これらの置き換えられる部分は、ローカル環境のソース データベース、データ テーブル、Kakfa トピック、およびスキーマに依存します。その他の情報については、テーブルが変更されるたびに対応する値を調整する必要があるため、グローバル変数には抽出されません。
さらに、このジョブは実際にはサードパーティの Jar パッケージに依存しておらず、使用する Confluent Avro Converter はhudi-utilities-bundle.jarに統合されています--conf spark.jars=$(...)。読者の参照が必要です。
# 实操步骤(5)
cat << EOF > $APP_LOCAL_HOME/start-job-run.json
{
"name":"apache-hudi-delta-streamer",
"applicationId":"$EMR_SERVERLESS_APP_ID",
"executionRoleArn":"$EMR_SERVERLESS_EXECUTION_ROLE_ARN",
"jobDriver":{
"sparkSubmit":{
"entryPoint":"/usr/lib/hudi/hudi-utilities-bundle.jar",
"entryPointArguments":[
"--continuous",
"--enable-sync",
"--table-type", "COPY_ON_WRITE",
"--op", "UPSERT",
"--target-base-path", "<your-table-s3-path>",
"--target-table", "<your-table>",
"--min-sync-interval-seconds", "60",
"--source-class", "org.apache.hudi.utilities.sources.debezium.MysqlDebeziumSource",
"--source-ordering-field", "_event_origin_ts_ms",
"--payload-class", "org.apache.hudi.common.model.debezium.MySqlDebeziumAvroPayload",
"--hoodie-conf", "bootstrap.servers=$KAFKA_BOOTSTRAP_SERVERS",
"--hoodie-conf", "schema.registry.url=$SCHEMA_REGISTRY_URL",
"--hoodie-conf", "hoodie.deltastreamer.schemaprovider.registry.url=${SCHEMA_REGISTRY_URL}/subjects/<your-registry-name>.<your-src-database>.<your-src-table>-value/versions/latest",
"--hoodie-conf", "hoodie.deltastreamer.source.kafka.value.deserializer.class=io.confluent.kafka.serializers.KafkaAvroDeserializer",
"--hoodie-conf", "hoodie.deltastreamer.source.kafka.topic=<your-kafka-topic-of-your-table-cdc-message>",
"--hoodie-conf", "auto.offset.reset=earliest",
"--hoodie-conf", "hoodie.datasource.write.recordkey.field=<your-table-recordkey-field>",
"--hoodie-conf", "hoodie.datasource.write.partitionpath.field=<your-table-partitionpath-field>",
"--hoodie-conf", "hoodie.datasource.hive_sync.partition_extractor_class=org.apache.hudi.hive.MultiPartKeysValueExtractor",
"--hoodie-conf", "hoodie.datasource.write.hive_style_partitioning=true",
"--hoodie-conf", "hoodie.datasource.hive_sync.database=<your-sync-database>",
"--hoodie-conf", "hoodie.datasource.hive_sync.table==<your-sync-table>",
"--hoodie-conf", "hoodie.datasource.hive_sync.partition_fields=<your-table-partition-fields>"
],
"sparkSubmitParameters":"--class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer --conf spark.serializer=org.apache.spark.serializer.KryoSerializer --conf spark.hadoop.hive.metastore.client.factory.class=com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory --conf spark.jars=<your-app-dependent-jars>"
}
},
"configurationOverrides":{
"monitoringConfiguration":{
"s3MonitoringConfiguration":{
"logUri":"<your-s3-location-for-emr-logs>"
}
}
}
}
EOF
jq . $APP_LOCAL_HOME/start-job-run.json
以下に例を示します。
# 示例(非实操步骤)
cat << EOF > $APP_LOCAL_HOME/start-job-run.json
{
"name":"apache-hudi-delta-streamer",
"applicationId":"$EMR_SERVERLESS_APP_ID",
"executionRoleArn":"$EMR_SERVERLESS_EXECUTION_ROLE_ARN",
"jobDriver":{
"sparkSubmit":{
"entryPoint":"/usr/lib/hudi/hudi-utilities-bundle.jar",
"entryPointArguments":[
"--continuous",
"--enable-sync",
"--table-type", "COPY_ON_WRITE",
"--op", "UPSERT",
"--target-base-path", "$APP_S3_HOME/data/mysql-server-3/inventory/orders",
"--target-table", "orders",
"--min-sync-interval-seconds", "60",
"--source-class", "org.apache.hudi.utilities.sources.debezium.MysqlDebeziumSource",
"--source-ordering-field", "_event_origin_ts_ms",
"--payload-class", "org.apache.hudi.common.model.debezium.MySqlDebeziumAvroPayload",
"--hoodie-conf", "bootstrap.servers=$KAFKA_BOOTSTRAP_SERVERS",
"--hoodie-conf", "schema.registry.url=$SCHEMA_REGISTRY_URL",
"--hoodie-conf", "hoodie.deltastreamer.schemaprovider.registry.url=${SCHEMA_REGISTRY_URL}/subjects/osci.mysql-server-3.inventory.orders-value/versions/latest",
"--hoodie-conf", "hoodie.deltastreamer.source.kafka.value.deserializer.class=io.confluent.kafka.serializers.KafkaAvroDeserializer",
"--hoodie-conf", "hoodie.deltastreamer.source.kafka.topic=osci.mysql-server-3.inventory.orders",
"--hoodie-conf", "auto.offset.reset=earliest",
"--hoodie-conf", "hoodie.datasource.write.recordkey.field=order_number",
"--hoodie-conf", "hoodie.datasource.write.partitionpath.field=order_date",
"--hoodie-conf", "hoodie.datasource.hive_sync.partition_extractor_class=org.apache.hudi.hive.MultiPartKeysValueExtractor",
"--hoodie-conf", "hoodie.datasource.write.hive_style_partitioning=true",
"--hoodie-conf", "hoodie.datasource.hive_sync.database=inventory",
"--hoodie-conf", "hoodie.datasource.hive_sync.table=orders",
"--hoodie-conf", "hoodie.datasource.hive_sync.partition_fields=order_date"
],
"sparkSubmitParameters":"--class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer --conf spark.serializer=org.apache.spark.serializer.KryoSerializer --conf spark.hadoop.hive.metastore.client.factory.class=com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory --conf spark.jars=$(aws s3 ls $APP_S3_HOME/jars/ | grep -o '\S*\.jar$'| awk '{print "'"$APP_S3_HOME/jars/"'"$1","}' | tr -d '\n' | sed 's/,$//')"
}
},
"configurationOverrides":{
"monitoringConfiguration":{
"s3MonitoringConfiguration":{
"logUri":"$APP_S3_HOME/logs"
}
}
}
}
EOF
jq . $APP_LOCAL_HOME/start-job-run.json
7.2 課題の提出
ジョブ記述ファイルを準備したら、ジョブを正式に送信できます。コマンドは次のとおりです。
# 实操步骤(6)
export EMR_SERVERLESS_JOB_RUN_ID=$(aws emr-serverless start-job-run \
--no-paginate --no-cli-pager --output text \
--name apache-hudi-delta-streamer \
--application-id $EMR_SERVERLESS_APP_ID \
--execution-role-arn $EMR_SERVERLESS_EXECUTION_ROLE_ARN \
--execution-timeout-minutes 0 \
--cli-input-json file://$APP_LOCAL_HOME/start-job-run.json \
--query jobRunId)
7.3 ジョブの監視
ジョブが送信された後、コンソールでジョブの実行ステータスを確認できます。コマンド ライン ウィンドウでジョブを継続的に監視する場合は、次のスクリプトを使用できます。
# 实操步骤(7)
now=$(date +%s)sec
while true; do
jobStatus=$(aws emr-serverless get-job-run \
--no-paginate --no-cli-pager --output text \
--application-id $EMR_SERVERLESS_APP_ID \
--job-run-id $EMR_SERVERLESS_JOB_RUN_ID \
--query jobRun.state)
if [ "$jobStatus" = "PENDING" ] || [ "$jobStatus" = "SCHEDULED" ] || [ "$jobStatus" = "RUNNING" ]; then
for i in {
0..5}; do
echo -ne "\E[33;5m>>> The job [ $EMR_SERVERLESS_JOB_RUN_ID ] state is [ $jobStatus ], duration [ $(date -u --date now-$now +%H:%M:%S) ] ....\r\E[0m"
sleep 1
done
else
echo -ne "The job [ $EMR_SERVERLESS_JOB_RUN_ID ] is [ $jobStatus ]\n\n"
break
fi
done
7.4 エラーの取得
ジョブの実行開始後、Spark Driver と Executor は構成されたパスに保存されるログの生成を続行します$APP_S3_HOME/logs。ジョブが失敗した場合は、次のスクリプトを使用してエラー情報をすばやく取得できます。
# 实操步骤(8)
JOB_LOG_HOME=$APP_LOCAL_HOME/log/$EMR_SERVERLESS_JOB_RUN_ID
rm -rf $JOB_LOG_HOME && mkdir -p $JOB_LOG_HOME
aws s3 cp --recursive $APP_S3_HOME/logs/applications/$EMR_SERVERLESS_APP_ID/jobs/$EMR_SERVERLESS_JOB_RUN_ID/ $JOB_LOG_HOME >& /dev/null
gzip -d -r -f $JOB_LOG_HOME >& /dev/null
grep --color=always -r -i -E 'error|failed|exception' $JOB_LOG_HOME
7.5 ジョブの停止
DeltaStreamer は継続的に実行されているジョブです。ジョブを停止する必要がある場合は、次のコマンドを使用できます。
# 实操步骤(9)
aws emr-serverless cancel-job-run \
--no-paginate --no-cli-pager\
--application-id $EMR_SERVERLESS_APP_ID \
--job-run-id $EMR_SERVERLESS_JOB_RUN_ID
8. 結果の検証
ジョブが開始されると、データ テーブルが自動的に作成され、データは指定された S3 の場所に書き込まれます。次のコマンドを使用して、自動的に作成されたデータ テーブルとランディング データ ファイルを表示します。
# 实操步骤(10)
aws s3 ls --recursive <your-table-s3-path>
aws glue get-table --no-paginate --no-cli-pager \
--database-name <your-sync-database> --name <your-sync-table>
# 示例(非实操步骤)
aws s3 ls --recursive $APP_S3_HOME/data/mysql-server-3/inventory/orders/
aws glue get-table --no-paginate --no-cli-pager \
--database-name inventory --name orders
9. 評価と展望
この記事では、「コーディングゼロ」「運用保守ゼロ」の超軽量ソリューションであるApache Hudi DeltaStreamerをEMRサーバーレス上で実行し、CDCデータをHudiテーブルに接続する方法を詳しく紹介します。ただし、その制限も明らかです。つまり、DeltaStreamer ジョブは 1 つのテーブルにしかアクセスできません。これは、毎ターン数百、さらには数千のテーブルにアクセスする必要があるデータ レイクにとっては実用的ではありません。ただし、Hudi はマルチテーブル用の MultiTableDeltaStreamer も提供しています。アクセスできますが、このツール クラスの現在の成熟度と完全性は運用には十分ではありません。さらに、Hudi はその後、0.10.0Kafka Connect 用の Hudi Sink プラグイン (現在は単一のテーブルのみをサポート) を提供しています。これにより、CDC データが Hudi データ レイクにアクセスするための新しい方法が開かれ、これは継続的に評価される価値のある新しいハイライトです。注意。
長期的には、CDC データが湖に入り、Hudi テーブルとして着陸することは非常に一般的な需要です。DeltaStreamer、HoodieMultiTableDeltaStreamer、Kafka Connect Hudi Sink プラグインを含むさまざまなネイティブ コンポーネントの反復と改善は、今後ますます一般的になるでしょう。 Hudi の精力的な開発により、これらのコンポーネントは成熟し続け、徐々に実稼働環境に適用されると私は強く信じています。