Apache Arrow:クロスプラットフォームのメモリデータ交換フォーマット
過去のメモリビッグデータ過去のメモリビッグデータ
ApacheArrowは、Apache Foundationの新しいオープンソースプロジェクトであり、トップレベルのプロジェクトでもあります。その目的は、クロスプラットフォームのデータレイヤーとしてビッグデータ分析プロジェクトの運用をスピードアップすることです。柱状メモリストレージの処理と相互作用の仕様を提供します。現在、Calcite、Cassandra、Drill、Hadoop、HBase、Ibis、Impala、Kudu、Pandas、Parquet、Phoenix、Spark、Stormを含む13のコミュニティの開発者が、ビッグデータシステムプロジェクトのデファクトスタンダードにすることに取り組んでいます。
経済的なストレージおよびバッチ処理プラットフォームとしてHadoopなどのビッグデータプラットフォームを使用することに加えて、ユーザーはビッグデータ分析を適用する際の分析システムのスケーラビリティとパフォーマンスも高く評価します。過去数年間、オープンソースコミュニティは、ビッグデータ分析のエコシステムを改善するための多くのツールをリリースしました。これらのツールは、列指向ストレージ形式(Parquet / ORC)、インメモリコンピューティングレイヤー(Drill)など、データ分析のすべての側面をカバーします。 、Spark、Impala、Storm)と強力なAPIインターフェース(PythonとR言語)。Arrowは最新の追加であり、クロスプラットフォームおよびクロスアプリケーションのメモリデータ交換フォーマットを提供します。たとえば、最近リリースされたSpark 3.0では、Arrowを使用してSparkRのパフォーマンスを少なくとも40%向上させました。ApacheSpark3.0.0の公式バージョンがついにリリースされ、重要な機能が完全に分析されていることを確認してください。
ビッグデータ分析のパフォーマンスを向上させるための重要な手段は、列データの設計と処理です。柱状データ処理により、ベクトルコンピューティングとSIMDによってハードウェアの可能性を十分に引き出すことができます。ビッグデータクエリエンジンであるApacheDrillは、ハードディスク上でもメモリ内でも列に存在し、ArrowはDrillの値ベクトルデータ形式から開発されています。柱状データに加えて、Apache Arrowはリレーショナルおよび動的データセットもサポートしているため、モノのインターネットなどのデータを処理するための理想的な形式を選択できます。
ApacheArrowがビッグデータエコシステムにもたらす可能性は無限大です。将来的にはApacheArrowが標準のデータ交換フォーマットとなり、さまざまなデータ分析システムとアプリケーション間の双方向性が新たなレベルに達したと言えます。以前は、CPUサイクルのほとんどがデータのシリアル化と逆シリアル化に費やされていましたが、現在では、異なるシステム間でシームレスなデータ共有を実現できます。これは、ユーザーが異なるシステムを組み合わせるときにデータ形式について心配する必要がなくなったことを意味します。次の図は、列ストレージ形式と行ストレージ形式の違いを示しています。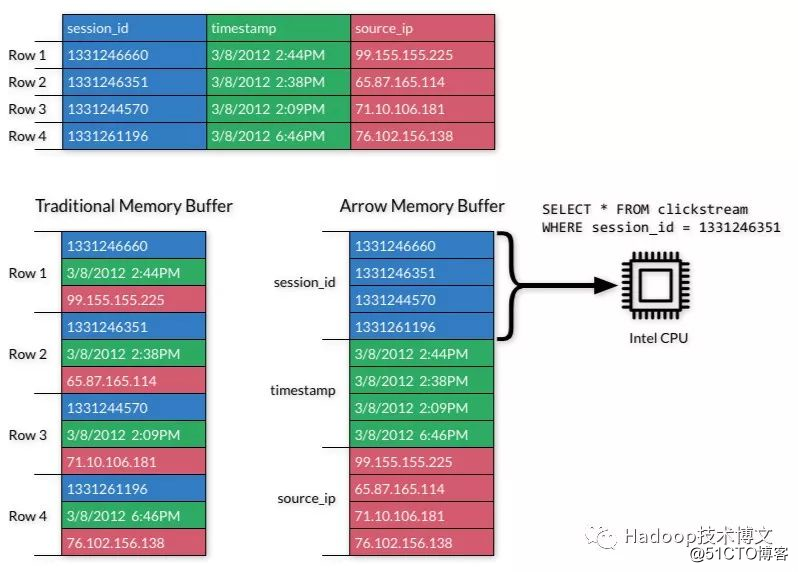
ApacheArrowを使用する前後の利点の比較
Apache Arrowが誕生する前は、異なるシステム間でデータを交換する必要がある場合は、次のように処理する必要がありました。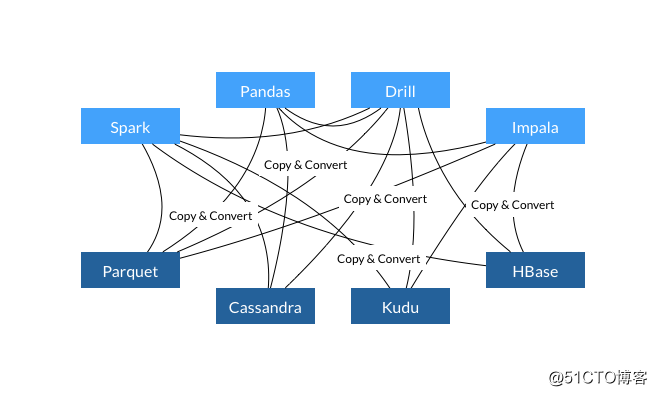
これによって引き起こされる問題は次のとおりです。
- 各システムには独自の内部メモリ形式があります。
- CPUの70-80%は、シリアル化および逆シリアル化プロセスで浪費されます。
- 同様の機能が複数のプロジェクトに実装されており、単一の標準はありません。
プロジェクトでシステムデータの相互作用にApacheArrowを使用すると、アーキテクチャは次の形式になります。次の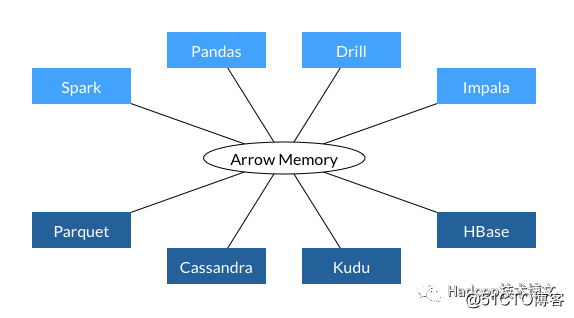
ことがわかります。
- すべてのシステムは同じメモリフォーマットを使用します。
- システム間の通信のオーバーヘッドを回避します。
- プロジェクト間で機能を共有できます(Parquet-to-Arrowリーダーなど)
ApacheArrowには次の利点があります。
- 円柱状のメモリレイアウトにより、ランダムアクセスの速度をO(1)に到達させることができます。このメモリレイアウトは、分析ストリームを処理し、SIMD(単一入力複数データ)の最適化を可能にする最新のプロセッサで非常に効率的です。開発者は、ApacheArrowのデータ構造を処理するための非常に効率的なアルゴリズムを開発できます。
- これにより、システム間のデータの相互作用が非常に効率的になり、データのシリアル化と逆シリアル化の消費が回避されます。
- 複雑なデータ型をサポートします。
Apache Arrowがデータにランダムアクセスできる理由はO(1)に達します。これは、ApacheArrowが次のデータなどの構造化データの分析用に最適化されているためです。
people = [
{
name: ‘mary’, age: 30,
places_lived: [
{city: ‘Akron’, state: ‘OH’},
{city: ‘Bath’, state: OH’}
]
},
{
name: ‘mark’, age: 33,
places_lived: [
{city: ‘Lodi’, state: ‘OH’},
{city: ‘Ada’, state: ‘OH’},
{city: ‘Akron’, state: ‘OH}
]
}
]ここで、people.places_lived.cityの値にアクセスする必要があるとします。矢印では、配列値へのアクセスは次のようになります:
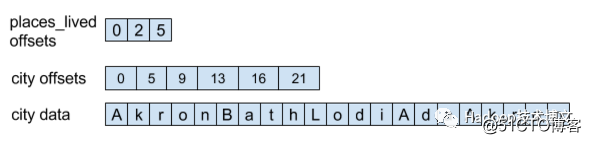
矢印はplaces_livedフィールドとcityフィールドのオフセットを記録し、このオフセットを介してフィールドの値を取得できます。Arrowはオフセットを記録して、データアクセスを非常に効率的にするためです。
Apache Arrowプロジェクトの公式ウェブサイト:http://arrow.apache.org/
Apache ArrowプロジェクトGithub:https://github.com/apache/arrow