この記事は、Kafkaのコピー複製メカニズムを完全に理解しています
過去の大容量データメモリ過去のメモリビッグデータ
も過去に移動できます。大容量メモリデータの読み取りブログ(元のテキストを読むには、以下をクリックしてください)https://www.iteblog.com/archives/2556.html
分散システムの操作を許可しますシンプルになります、ある程度、それは芸術であり、この実現は通常、多くの実践から要約されます。Apache Kafkaの人気は、主にその設計と操作の単純さによるものです。コミュニティがさらに機能を追加すると、開発者は戻って複雑な動作を単純化する方法を再考します。
Apache Kafkaのより微妙な機能は、そのレプリケーションプロトコルです。単一のクラスター上のさまざまなサイズのワークロードの場合、さまざまな状況に適応するようにKafkaレプリケーションを調整することは、今日では少し注意が必要です。これを特に困難にする課題の1つは、レプリカが同期レプリカリスト(ISRとも呼ばれます)に参加したり、リストから脱退したりするのを防ぐ方法です。ユーザーの観点からすると、これは、プロデューサー(プロデューサー)が「十分に大きい」メッセージのバッチを送信する場合、Kafkaブローカーが複数のアラートを発行する可能性があることを意味します。これらのアラートは、特定のトピックが「複製不足」であることを示しています。これは、データが十分なブローカーに複製されていないことを意味し、データが失われる可能性が高くなります。したがって、Kafkaクラスターが「複製されていない」パーティションの総数を注意深く監視することは非常に重要です。この記事では、この動作の根本原因と、この問題を解決する方法について説明します。
Kafkaレプリケーションメカニズムについて1分で学ぶ
Kafkaトピックの各パーティションには先行書き込みログがあり、Kafkaに書き込んだメッセージが保存されます。ここでの各メッセージには一意のオフセットがあり、現在のパーティションログでの位置を識別するために使用されます。次の図に示すように、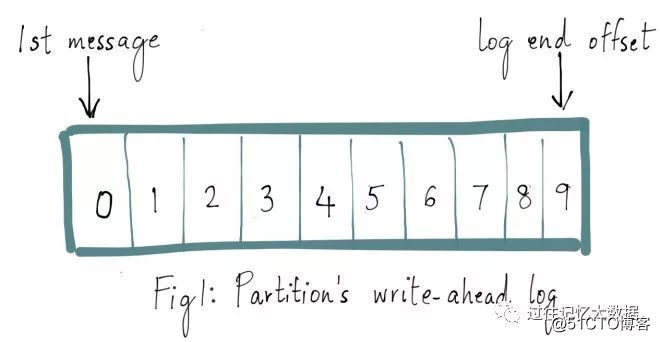
Spark、Hadoop、またはHBase関連の記事について時間内に知りたい場合は、WeChatの公式アカウントに注意してください。iteblog_hadoopKafkaの
各トピックパーティションはn回複製されています。ここで、nは複製です。トピックの要素。)。これにより、Kafkaは、クラスターサーバーに障害が発生した場合にこれらのレプリカに自動的に切り替えることができるため、障害が発生した場合でもメッセージを利用できます。Kafkaのレプリケーションはパーティションに基づいており、パーティションの先行書き込みログはn台のサーバーにレプリケートされます。n個のレプリカのうち、1個のレプリカがリーダーとして機能し、他のレプリカがフォロワーになります。名前が示すように、プロデューサーはリーダーパーティションにのみデータを書き込むことができ(読み取りはリーダーパーティションからのみ実行できます)、フォロワーはリーダーからログを順番にコピーするだけです。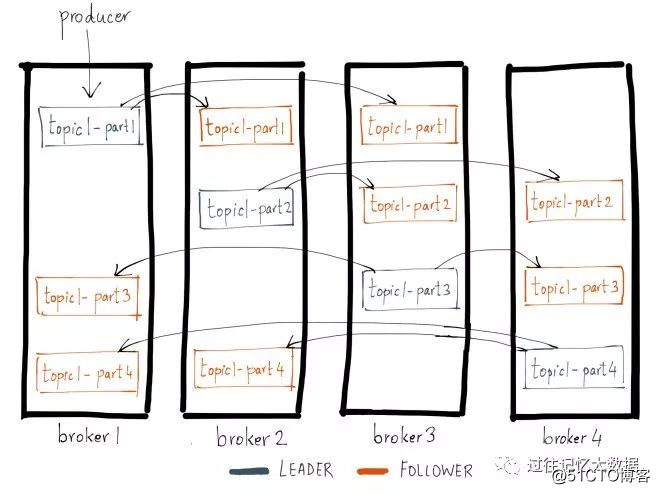
Spark、Hadoop、またはHbase関連の記事について時間内に知りたい場合は、WeChatパブリックアカウントに注意してください。iteblog_hadoop
ログレプリケーションアルゴリズム(ログレプリケーションアルゴリズム)は、メッセージが送信されたことをクライアントに通知する場合、基本的な保証を提供する必要があります。送信され、現在のリーダーが失敗した場合、新しく選出されたリーダーにもこのメッセージが必要です。障害が発生した場合、Kafkaは、障害が発生したリーダーのISRからフォロワーをパーティションの新しいリーダーとして選択します。つまり、フォロワーがリーダーの書き込みの進行状況に追いついているためです。
各パーティションのリーダーは、同期レプリカ(同期レプリカリスト、ISRとも呼ばれます)を維持します。プロデューサーがブローカーにメッセージを送信すると、メッセージは最初に対応するリーダーパーティションに書き込まれ、次にこのパーティションのすべてのレプリカにコピーされます。メッセージがすべての同期レプリカ(ISR)に正常にコピーされた後でのみ、メッセージは送信されたと見なされます。メッセージ複製の待ち時間は最も遅い同期コピーによって制限されるため、遅いコピーをすばやく検出してISRから削除することが重要です。Kafkaレプリケーション契約の詳細は少し異なります。このブログでは、このトピックについて詳しく説明するつもりはありません。興味のある学生は、ここにアクセスして、Kafkaレプリケーションの動作原理について詳しく学ぶことができます。
どのような状況でレプリカはリーダーに追いつくことができますか
レプリカがリーダーのログの進行状況に追いついていない場合は、非同期レプリカとしてマークされる可能性があります。キャッチアップの意味を説明するために例を使用します。fooという名前のトピックがあり、パーティションが1つだけで、レプリケーション係数が3であるとします。このパーティションのコピーがブローカー1、2、および3にあり、トピックfooに関する3つのメッセージを送信したとします。ブローカー1のレプリカがリーダーであり、レプリカ2と3がフォロワーであり、すべてのレプリカがISRの一部です。Replica.lag.max.messagesが4に設定されているとすると、これは、フォロワーがリーダーの後ろに3つ以下のメッセージを持っている限り、ISRから削除されないことを意味します。Replica.lag.time.max.msを500ミリ秒に設定しました。これは、フォロワーが500ミリ秒またはそれ以前ごとにリーダーにフェッチ要求を送信する限り、それらはデッドとしてマークされず、から削除されないことを意味します。 ISR削除。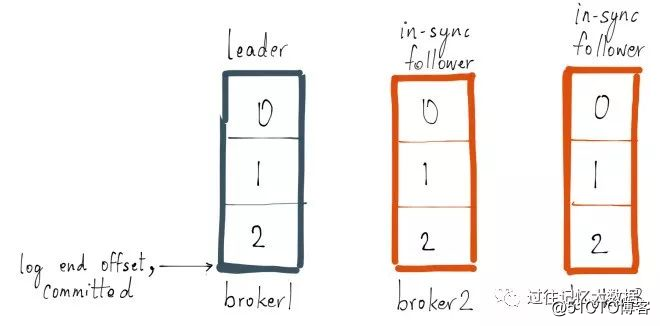
Spark、Hadoop、またはHbase関連の記事について時間内に知りたい場合は、WeChatパブリックアカウントに注意してください:iteblog_hadoop
ここで、プロデューサーが次のメッセージをリーダーに送信するとします。同時に、GCの一時停止が発生します。ブローカー3、そして現在は各ブローカーのパーティション状況は次のとおりです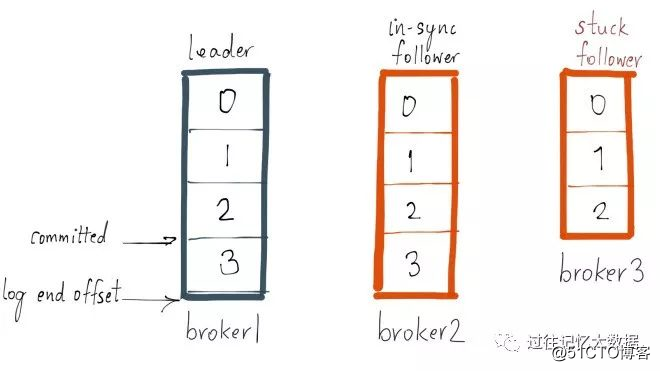
。Spark、Hadoop、またはHbase関連の記事について時間内に知りたい場合は、WeChatパブリックアカウントiteblog_hadoopに注意してください。
ブローカー3はISRにあるため、ブローカー3がISRから削除されるか、ブローカー3のパーティションがリーダーのログ終了オフセットに追いつくまで、最新のメッセージは送信されたとは見なされません。ボーダー3はリーダーのメッセージより遅れているため、replica.lag.max.messages = 4よりも小さいため、ISRから削除するための条件を満たしていないことに注意してください。これは、ブローカー3のパーティションが、メッセージをリーダーからのオフセット3と同期する必要があることを意味します。同期する場合、このレプリカはリーダーに追いつきます。ブローカー3が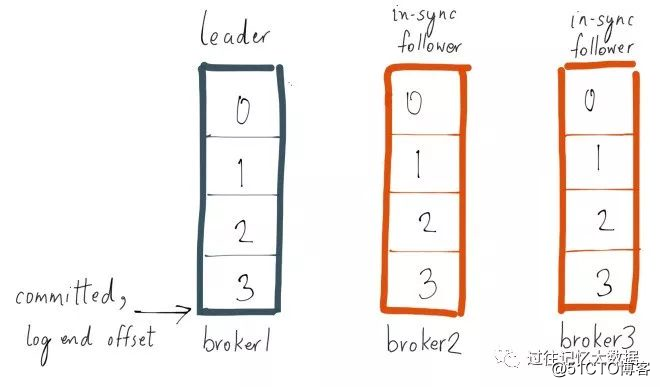
100ミリ秒以内にGCを完了し、リーダーのログエンドオフセットに追いつくと仮定すると、最新の状況は次のようになります。Spark、Hadoop、またはHbase関連の記事について時間内に知りたい場合は、WeChatパブリックに注意してください。アカウント:iteblog_hadoop
どのような状況でレプリカがリーダーとの同期を失う原因になりますか
レプリカがリーダーとの同期を失う理由はたくさんあります。主に次のようなものがあります。
- 遅いレプリカ:フォロワーレプリカは、一定期間、リーダーの書き込みの進行状況に追いつくことができませんでした。この状況の最も一般的な理由の1つは、フォロワーレプリカのI / Oボトルネックです。これにより、リーダーからのメッセージを消費するのにかかる時間よりも長くログが保持されます。
- スタックレプリカ:フォロワーレプリカは、リーダーからのメッセージの取得を長時間停止します。これは、GCが一時停止しているか、コピーに障害があることが原因である可能性があります。
- ブートストラップレプリカ:ユーザーがトピックへのレプリケーション係数を増やすと、リーダーのログに追いつくまで、新しいフォロワーレプリカは同期されません。
レプリカがリーダーパーティションより遅れている場合、レプリカは同期していないか遅れていると見なされます。Kafka 0.8.2では、レプリカのラグはreplica.lag.max.messagesまたはreplica.lag.time.max.msによって測定されます。前者は低速レプリカの検出に使用され、後者は低速レプリカの検出に使用されます。 。スタックレプリカを検出します(スタックレプリカ)。コピーが遅れていることを確認する方法
スタックレプリカを検出するためにreplica.lag.time.max.msを使用すると、すべての場合にうまく機能します。フォロワーのコピーがリーダーに取得要求を送信しなかった時間を追跡し、フォロワーが正常であるかどうかを推測するために使用できます。一方、メッセージ数を使用して非同期の低速レプリカを検出するモデルは、これらのパラメーターが単一のトピックまたは同様のトラフィックパターンを持つ複数のトピックに設定されている場合にのみ適切に機能しますが、それができないことがわかりました。本番環境に拡張クラスター内のすべてのトピック。私の前の例に基づいて、fooが2 msg /秒の
データの速度で書き込む場合のテーマで、リーダーは通常1つのバッチを受信し、通常は3つを超えることはありません。この場合、replica.lagこのトピックを知っています。 .messagesパラメーターは4に設定できます。どうして?リーダーに最大速度でデータを書き込み、フォロワーのコピーがこれらのメッセージを複製する前に、フォロワーのログはリーダーより3メッセージ以内遅れます。同時に、トピックfooのフォロワーコピーが常にリーダーの後ろに3つ以上のメッセージがある場合は、メッセージ書き込み遅延の増加を防ぐために、リーダーが遅いフォロワーコピーを削除することを期待します。
これは基本的にreplica.lag.max.messagesの目標であり、リーダーと常に同期していないレプリカを検出できるようにすることです。このトピックのトラフィックがピークのために増加していると仮定すると、プロデューサーは最終的に4つのメッセージのバッチをfooに送信します。これは、replica.lag.max.messages = 4の構成値に等しくなります。この時点で、2つのフォロワーレプリカはリーダーと同期していないと見なされ、ISRは削除されます。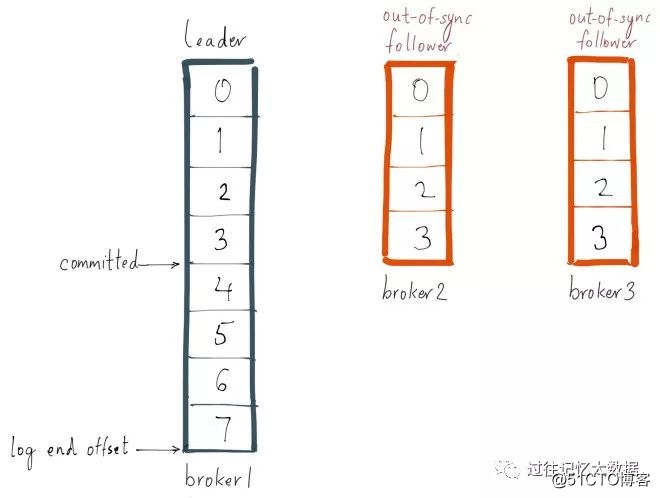
Spark、Hadoop、またはHbase関連の記事について時間内に知りたい場合は、WeChatパブリックアカウントに注意してください:iteblog_hadoop
ただし、両方のフォロワーレプリカがアクティブであるため、次のフェッチ要求でリーダーのログ終了オフセットに追いつき、ISRに追加されます。プロデューサーがリーダーに多数のメッセージを送信し続ける場合、上記と同じプロセスが繰り返されます。これは、フォロワーコピーがISRに出入りするときに、不要な誤警報がトリガーされることを示しています。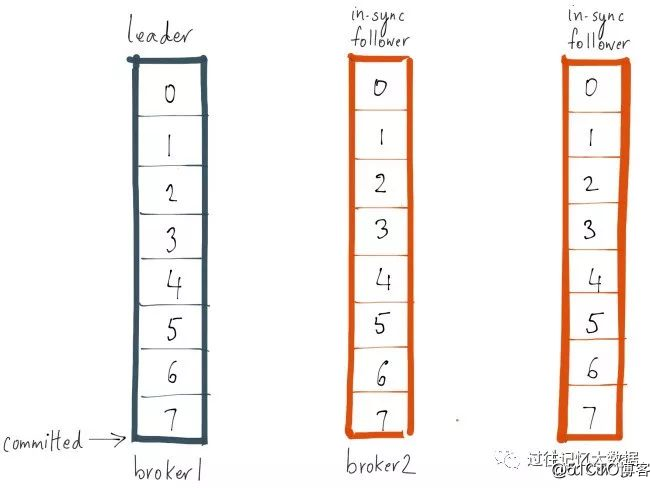
Spark、Hadoop、またはHbase関連の記事について時間内に知りたい場合は、WeChatパブリックアカウントに注意してください。iteblog_hadoopreplica.lag.max.messages
パラメーターの主要な問題は、ユーザーがこの値の構成方法を推測する必要があることです。 Kafkaの着信トラフィックがわからないため、特にネットワークのピークの場合はどれくらいになるでしょうか。1つのパラメータですべてを処理します
スタックしたレプリカや遅いレプリカを検出するために本当に重要なことは、レプリカがリーダーと同期していないときです。推測によって設定されたreplica.lag.max.messagesパラメーターを削除しました。これで、サーバーでreplica.lag.time.max.msパラメーターを構成するだけで済みます。このパラメーターは、レプリカがリーダーと同期していない時間を意味します。
スタックしたレプリカを検出する方法は以前と同じです。レプリカがreplica.lag.time.max.msの時間内にフェッチ要求を送信できなかった場合、レプリカはデッドレプリカとして扱われ、ISRから削除されます
。遅いレプリカを検出するメカニズムが変更されました-レプリカがreplica.lag.time.max.msを超えてリーダーの後ろにある場合、それは遅すぎると見なされ、ISRから削除されます。
したがって、トラフィックがピークに達した場合でも、レプリカが常にreplica.lag.time.max.msをリーダーの背後に保持しない限り、プロデューサーはリーダーに多数のメッセージを送信します。そうしないと、ISRにランダムに出入りしません。
この記事は、ハンズフリーKafkaレプリケーションから翻訳されています:操作の単純さのレッスン:https://de.confluent.io/blog/hands-free-kafka-replication-a-lesson-in-operational-simplicity/