1つは、マスタースレーブの同期/レプリケーションです。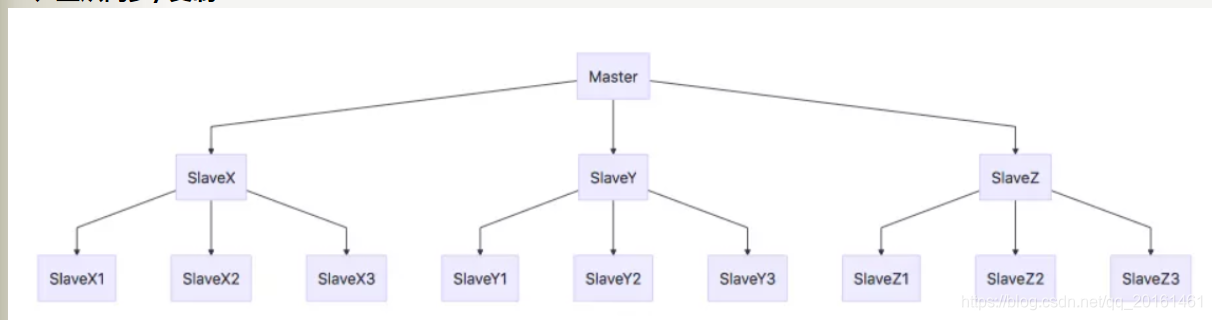
永続化機能により、Redisは、サーバーを再起動してもデータが失われない(または少量の損失が発生しない)ことを保証します。これは、永続性によってデータがメモリにハードディスクに保存され、再起動によってデータがハードディスクに読み込まれるためです。ハードディスク。ただし、データはサーバーに保存されているため、このサーバーにハードディスク障害などの問題があると、データの損失も発生します。
単一障害点を回避するために、通常は、データベースの複数のコピーを複製して異なるサーバーに展開し、1つのサーバーに障害が発生した場合でも、他のサーバーがサービスを提供し続けることができるようにします。この目的のために、Redisは、1つのデータベースのデータが更新されたときに、更新されたデータを他のデータベースに自動的に同期できるレプリケーション機能を提供します。
レプリケーションの概念では、データベースは2つのカテゴリに分類されます。1つはマスターデータベース(マスター)で、もう1つはスレーブデータベース(スレーブ)です。マスターデータベースは読み取りおよび書き込み操作を実行でき、書き込み操作によってデータが変更されると、データがスレーブデータベースに自動的に同期されます。スレーブデータベースは通常読み取り専用であり、マスターデータベースから同期されたデータを受け入れます。マスターデータベースには複数のスレーブデータベースを含めることができ、スレーブデータベースには1つのマスターデータベースしか含めることができません。
マスタースレーブレプリケーションの特性
*マスターデータベースは読み取りおよび書き込み操作を実行できます。読み取りおよび書き込み操作によってデータが変更されると、データは自動的にスレーブデータベースに同期されます 。スレーブデータベースは通常、読み取り専用であり、マスターデータベースから同期されたデータを受信します。 *一つのマスターが複数のスレーブを持つことができますが、1スレーブ1つのマスターにのみ対応することができます *スレーブハングは、他のスレーブとマスターの読み取りと書き込みの読み取りおよび書き込みには影響しません。再起動した後、データはマスターから同期されます。 *後マスターがハングすると、スレーブの読み取りには影響しませんが、Redisは書き込みサービスを提供しなくなります。マスターが再起動すると、redisは外部書き込みサービスを再度提供し ます。マスターがハングアップした後、マスターを再選択することはありません。スレーブノード。
利点:
マスタースレーブレプリケーションをサポートします。マスターはデータをスレーブに自動的に同期し、読み取りと書き込みを分離できます。
マスターの読み取り操作のプレッシャーを軽減するために、スレーブサーバーはクライアントに読み取り専用の操作サービスを提供できます。書き込みサービスは引き続きマスターコンプリートによって提供される必要があります。
スレーブは他のスレーブからの接続と同期要求を受け入れることもできます。これにより、マスターの同期圧力を効果的にオフロードできます。
マスターサーバーは非ブロッキング方式でスレーブにサービスを提供します。したがって、マスター/スレーブ同期期間中も、クライアントはクエリまたは変更要求を送信できます。
スレーブサーバーは、非ブロッキング方式でデータ同期も完了します。同期中にクライアントがクエリリクエストを送信すると、Redisは同期前にデータを返します。
短所:
Redisには自動フォールトトレランスおよびリカバリ機能がありません。ホストとスレーブのダウンタイムにより、フロントエンドの読み取りおよび書き込み要求の一部が失敗します。マシンが再起動するのを待つか、フロントエンドIPを手動で切り替える必要があります。回復するために;
ホストがダウンしていて、ダウンタイムの前に一部のデータがタイムリーではないスレーブに同期し、IPスイッチの後にデータの不整合の問題が発生し、システムの可用性が低下します;
複数のスレーブが切断されている場合再起動する必要があります。同時に再起動しないようにしてください。スレーブが起動している間は同期要求を送信し、ホストは完全に同期します。複数のスレーブを再起動すると、マスターIOが急激に増加し、ダウンタイムが発生する場合があります。
Redisはオンライン拡張をサポートするのがより難しく、クラスター容量が上限に達するとオンライン拡張は非常に複雑になります。
次に、センチネルモード
最初のマスター/スレーブ同期/レプリケーションモードでは、マスターサーバーがダウンしたときに、スレーブサーバーを手動でマスターサーバーに切り替える必要があります。これには、手動による介入が必要であり、面倒で面倒であり、サービスが利用できなくなります。期間。これは推奨される方法ではありません。多くの場合、センチネルモードを優先します。
歩哨モードは特別なモードです。まず、Redisは歩哨のコマンドを提供します。歩哨は独立したプロセスです。プロセスとして、独立して実行されます。原則として、センチネルはコマンドを送信し、Redisサーバーからの応答を待つことで、実行中の複数のRedisインスタンスを監視できます。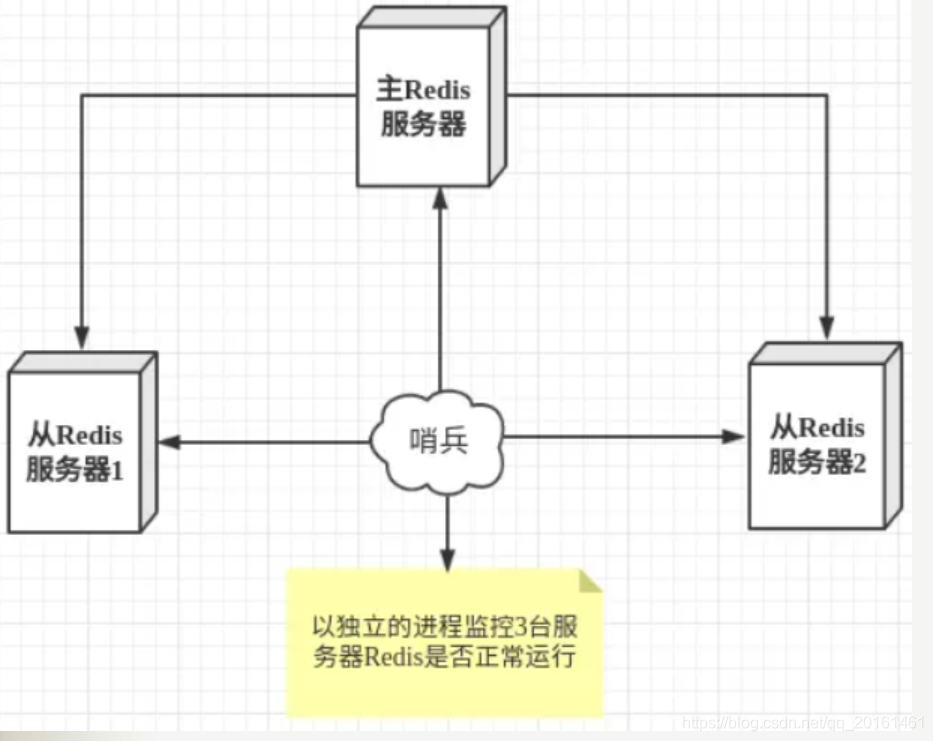
センチネルモードの役割:
コマンドを送信して、Redisサーバーに戻り、マスターサーバーとスレーブサーバーを含む実行ステータスを監視します。
センチネルは、マスターがダウンしていることを検出すると、自動的にスレーブをマスターに切り替えてから、他のスレーブサーバーに通知します。パブリッシュ/サブスクライブモードを使用して、構成ファイルを変更し、ホストを切り替えます。
ただし、Redisサーバーを監視するセンチネルプロセスにも問題がある可能性があります。このため、複数のセンチネルを使用して監視できます。各センチネル間でも監視が行われるため、マルチセンチネルモードが形成されます。
フェイルオーバーのプロセス:
メインサーバーがダウンしていると仮定すると、Sentinel 1は最初にこの結果を検出し、システムはフェイルオーバープロセスをすぐには実行しません。Sentinel1が主観的にメインサーバーが利用できないと信じているだけで、この現象は主観的にオフラインになります。次の歩哨もメインサーバーが利用できないことを検出し、その数が特定の値に達すると、歩哨の間で投票が行われ、投票の結果が歩哨によって開始されてフェイルオーバー操作が実行されます。切り替えが成功すると、各センチネルはパブリッシュ/サブスクライブモードを使用して、監視しているスレーブサーバーのホストを切り替えます。このプロセスは、目的オフラインと呼ばれます。このようにして、すべてがクライアントに対して透過的です。
センチネルモードの仕組み:
各Sentinelプロセスは、1秒に1回の頻度で、クラスター全体のマスターマスターサーバー、スレーブサーバー、およびその他のSentinelプロセスにPINGコマンドを送信します。
インスタンスが、PINGコマンドへの最後の有効な応答からのdown-after-millisecondsオプションで指定された値より大きい
場合、マスターサーバーが主観的としてマークされていると、インスタンスはSentinelプロセスによって主観的ダウン(SDOWN)としてマークされます。オフライン(SDOWN)の場合、このマスターマスターサーバーを監視しているすべてのSentinelプロセスは、マスターマスターサーバーが実際に主観的なオフライン状態になったことを1秒に1回確認する必要があります。
十分な数のSentinel(センチネル)がある場合)プロセス(構成ファイルで指定された値以上)は、マスターマスターサーバーが指定された時間範囲内に主観的なオフライン状態(SDOWN)に入ったことを確認し、マスターマスターサーバーは客観的なオフライン(ODOWN)としてマークされます。 。
一般に、各Sentinelプロセスは、10秒に1回の頻度で、クラスター内のすべてのマスターサーバーとスレーブサーバーにINFOコマンドを送信します。
マスターマスターサーバーがSentinelプロセスによって客観的にオフライン(ODOWN)としてマークされている場合、SentinelプロセスがオフラインになるマスターマスターサーバーのすべてのスレーブサーバーからINFOコマンドを送信する頻度は、10秒ごとから毎回に変更されます。 2番目。
マスターマスターサーバーのオフラインに同意するのに十分なSentinelプロセスがない場合、マスターマスターサーバーの目的のオフラインステータスは削除されます。マスターマスターサーバーがSentinelプロセスにPINGコマンドを再度送信し、有効な応答を返すと、マスターマスターサーバーの主観的なオフラインステータスが削除されます。
利点:
歩哨モードはマスタースレーブモードに基づいており、マスタースレーブのすべての利点である歩哨モードが持っています。
マスターとスレーブは自動的に切り替わることができ、システムはより堅牢になり、使いやすさが向上します。
短所:
Redisはオンライン拡張をサポートするのが難しく、クラスター容量が上限に達するとオンライン拡張は非常に複雑になります。
スプリットブレイン現象:
スプリットブレインとは何ですか?
いわゆるスプリットブレイン問題(統合失調症と同様)は、同じクラスター内の異なるノードがクラスターの状態について異なる理解を持っていることです。
センチネルモードが原因でredisスプリットブレインが発生するのはなぜですか?
たとえば(1マスター、1スレーブ、2歩哨)、ネットワーク上の理由またはいくつかの特別な理由により、歩哨はマスターノードデバイスの認識を失い、選挙を通じてフェイルオーバーしてスレーブノードをマスターノードに昇格させます。現在のクラスターには2つのマスターがあります。これは、スプリットブレイン現象の兆候です。異なるクライアントが読み取りと書き込みのために異なるredisにリンクされている場合、2台のマシンのredisデータは不整合になります。歩哨が古いマスターノードの認識を回復すると、それはスレーブノードに降格され、新しいマストからのデータを同期します(完全な再同期)。その結果、スプリットブレイン中に古いマスターによって書き込まれたデータが失われます。限目。
解決
Redis.confは属性を変更して、アクティブなスレーブノードの数とデータ同期の遅延時間を通じてマスターノードの書き込み操作を制限します。
#master少なくともx個のレプリカが接続されています。
min-slaves-to-write x
#データの複製と同期の遅延はx秒を超えることはできません。
最小-スレーブ-最大-ラグx
バレル効果
3.クラスタークラスター
Redisのセンチネルモードは基本的に高可用性と読み取り/書き込み分離を実現できますが、このモードでは、各Redisサーバーが同じデータを格納するため、メモリの浪費となるため、クラスタークラスターモードがredis3に追加されます。 0、Redisの分散ストレージを実現します。つまり、各Redisノードに異なるコンテンツが保存されます。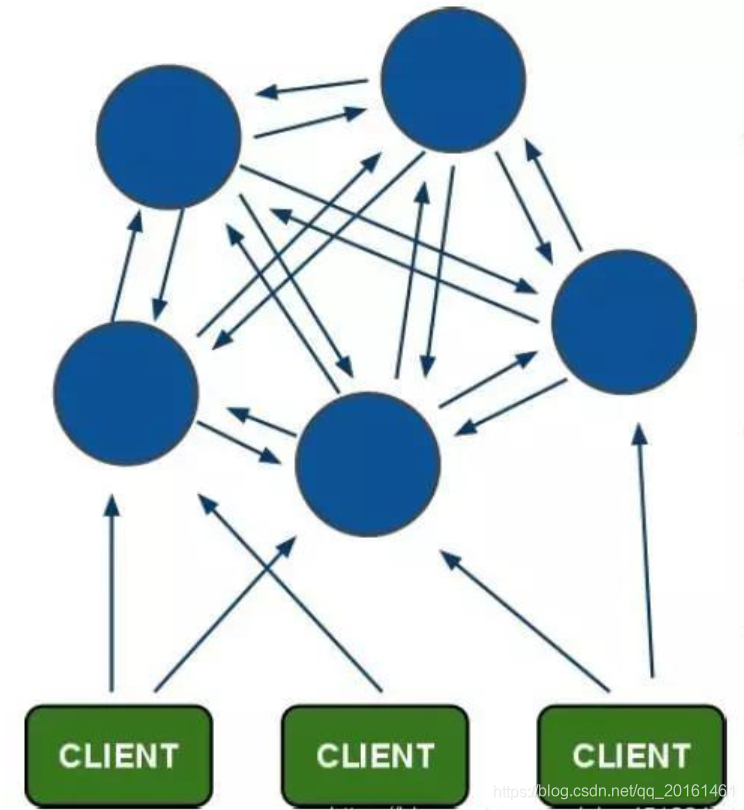
クラスター構成
公式の推奨によれば、クラスター展開には少なくとも3つのマスターノードが必要であり、3マスター3スレーブ6ノードモデルを使用するのが最適です。テスト環境では、シミュレートするために1台のマシンで6つのサービスインスタンスのみを開くことができます。
クラスターの特徴
すべてのredisノードは相互に接続され(PING-PONGメカニズム)、バイナリプロトコルが内部で使用されて伝送速度と帯域幅が最適化されます。
ノードの障害は、クラスター内のノードの半分以上が障害を検出した場合にのみ有効になります。
クライアントはRedisノードに直接接続されており、中間プロキシレイヤーは必要ありません。クライアントはクラスター内のすべてのノードに接続する必要はなく、クラスター内の使用可能なノードに接続するだけです。
すべてのノードは1つのマスターと1つのスレーブ(または1つのマスターと複数のスレーブ)であり、サービスを提供することはなく、バックアップとしてのみ機能します
ノードのオンライン追加と削除をサポート
クライアントは、読み取りと書き込みのために任意のマスターノードに接続できます
クラスターのしくみ
Redisの各ノードには、2つのものがあります。1つはスロットであり、その値の範囲は0〜16383です。クラスターもあります。これは、クラスター管理プラグインとして理解できます。アクセスキーが到着すると、Redisはcrc16のアルゴリズムに従って結果を取得し、結果の残りを16384に計算します。これにより、各キーは0〜16383の番号のハッシュスロットに対応し、この値を渡します。対応するスロットに対応するノードを見つけるために使用され、アクセス操作のために対応するノードに自動的にジャンプします。
Redisクラスターはコンシステントハッシュの代わりにデータシャーディングを使用して次のことを実現します。Redisクラスターには16384ハッシュスロットが含まれ、データベース内の各キーはこれらの16384ハッシュスロットに属します。そのうちの1つで、クラスターは式CRC16(key)%16384を使用してどれを計算しますかキーが属するスロットであり、CRC16(key)ステートメントを使用してキーのCRC16チェックサムが計算されます。
クラスタ内の各ノードは、ハッシュスロットの一部を処理する責任があります。たとえば、クラスターには3つのハッシュスロットを含めることができます。そのうちの1つは次のとおりです。
ノードAは、ハッシュスロット0〜5500の処理を担当します。
ノードBは、ハッシュスロット5501〜11000の処理を担当します。
ノードCは、ハッシュスロット11001から16384の処理を担当します。
ハッシュスロットを異なるノードに分散するこの方法により、ユーザーはクラスターからノードを簡単に追加または削除できます。
高可用性を確保するために、redis-clusterクラスターはマスタースレーブモードを導入します。マスターノードは1つ以上のスレーブノードに対応します。マスターノードがダウンすると、スレーブノードが有効になります。他のマスターノードがマスターノードAにpingを実行するときに、マスターノードの半分以上が時間外にAと通信する場合、マスターノードAがダウンしていると見なされます。マスターノードAとそのスレーブノードA1がダウンしている場合、クラスターはサービスを提供できなくなります。
歩哨と群れの違い
歩哨
番兵の役割は、Redisシステムの実行ステータスを監視することです。その機能は次の2つです。
プライマリデータベースとセカンダリデータベースが正常に動作しているかどうかを監視します。
プライマリデータベースに障害が発生すると、セカンダリデータベースは自動的にプライマリデータベースに変換されます。
センチネルは、マスターがダウンしていることを検出すると、スレーブからマスターを再選します。
センチネルモードは、高可用性
Sentinelシステムを使用して複数のRedisサーバー(インスタンス)を管理することを強調します。システムは次の3つのタスクを実行します。
監視:Sentinelは、マスターサーバーとスレーブサーバーが正常に動作しているかどうかを常にチェックします。
通知:監視対象のRedisサーバーに問題がある場合、SentinelはAPIを介して管理者または他のアプリケーションに通知を送信できます。
自動フェイルオーバー:マスターサーバーが正常に機能しない場合、Sentinelは自動フェイルオーバー操作を開始します。故障したマスターサーバーのスレーブサーバーの1つを新しいマスターサーバーにアップグレードし、マスターサーバーを故障させます。他のスレーブサーバーは変更されます。新しいマスターサーバーを複製します。クライアントが障害のあるマスターサーバーに接続しようとすると、クラスターは新しいマスターサーバーのアドレスもクライアントに返すため、クラスターは新しいマスターサーバーを使用して障害のあるサーバーを置き換えることができます。 。
クライアントはredisのアドレス(特定のIP)を記録しませんが、センチネルのアドレスを記録します。これにより、センチネルはすべてのマスターとスレーブを監視し、誰が正確に誰であるかを認識しているため、センチネルから直接redisアドレスを取得できます。マスター。たとえば、フェイルオーバーします。このとき、センチネルのマスターが変更され、クライアントに通知されます。クライアントは、誰が本当のマスターであるかをまったく気にする必要はなく、番兵から通知されたマスターだけを気にする必要があります。
集まる
センチネルが使用されている場合でも、redisの各インスタンスは完全に保存され、各redisに保存されるコンテンツは完全なデータであるため、メモリが浪費され、バレル効果があります。メモリを最大限に活用するために、分散ストレージであるクラスターを使用できます。つまり、各redisは、合計16384スロットの異なるコンテンツを格納します。各redisにはいくつかのスロットが割り当てられます。hash_slot= crc16(key)mod 16384は、対応するスロットを検索します。キーは使用可能なキーです。{}がある場合は、{}を使用可能なキーとします。それ以外の場合は、キー全体が使用可能です。キー
クラスターには少なくとも3つのマスターと3つのスレーブが必要であり、各インスタンスは異なる構成ファイルを使用します。マスターとスレーブを構成する必要はありません。クラスターはそれ自体で選択します。
クラスターは、単一のRedisの容量が限られているという問題を解決するためのものであり、データは特定のルールに従って複数のマシンに分散されます。
クラスターモードでは、同時実行の量が増加します。