バックグラウンド
利用索引避免排序代价
フロントリンクに書き込む
本文来自以下链接的摘录,https://www.cnblogs.com/cchust/p/5304594.html,5.7.26下场景不会重现,原作者可能使用的是5.6.16。
Order byステートメント、Group byステートメント、Distinctステートメントは暗黙的にソートを使用します
インデックスの使用法
假设t1表存在索引key1(key_part1,key_part2),key2(key2)
インデックスを使用してソートを回避できるSQL
SELECT * FROM t1 ORDER BY key_part1,key_part2;
SELECT * FROM t1 WHERE key_part1 = constant ORDER BY key_part2;
SELECT * FROM t1 WHERE key_part1 > constant ORDER BY key_part1 ASC;
SELECT * FROM t1 WHERE key_part1 = constant1 AND key_part2 > constant2
ORDER BY key_part2;
SQLのソートを回避するためにインデックスを使用することはできません
排序字段在多个索引中,无法使用索引排序
SELECT * FROM t1 ORDER BY key_part1,key_part2, key2;
排序键顺序与索引中列顺序不一致,无法使用索引排序
SELECT * FROM t1 ORDER BY key_part2, key_part1;
升降序不一致,无法使用索引排序
SELECT * FROM t1 ORDER BY key_part1 DESC, key_part2 ASC;
key_part1是范围查询,key_part2无法使用索引排序
SELECT * FROM t1 WHERE key_part1> constant ORDER BY key_part2;
ソートアルゴリズム
不能利用索引避免排序的SQL,此时SQL的执行计划中会出现“Using filesort”
filesortは、ファイルの並べ替えだけでなく、メモリの並べ替えも意味することに注意してください。これは主に、sort_buffer_sizeパラメータと結果セットのサイズによって決定されます。

MySQL内部实现排序主要有3种方式,常规排序,优化排序和优先队列排序,主要涉及3种排序算法:快速排序、归并排序和堆排序。
假设表结构和SQL语句如下:
CREATE TABLE t1(id int, col1 varchar(64), col2 varchar(64), col3 varchar(64),
PRIMARY KEY(id),key(col1,col2));
SELECT col1,col2,col3 FROM t1 WHERE col1>100 ORDER BY col2;
(补充,where条件和order by 列名不一致,属于无法使用联合索引的情况)
従来のソート
(1).从表t1中获取满足WHERE条件的记录
(2).对于每条记录,将记录的主键+排序键(id,col2)取出放入`sort buffer`
(3).如果sort buffer可以存放所有满足条件的(id,col2)对,则进行排序;否则sort buffer满后,
进行排序并固化到临时文件中。(排序算法采用的是'快速排序算法')
(4).若排序中产生了临时文件,需要利用'归并排序算法',保证临时文件中记录是有序的
(5).循环执行上述过程,直到所有满足条件的记录全部参与排序
(6).扫描排好序的(id,col2)对,并`利用id去捞取SELECT需要返回的列`(col1,col2,col3)
(7).将获取的结果集返回给用户。
上記のプロセスから、ファイルソートを使用するかどうかは、主に、ソートバッファーが、ソートする必要のある(id、col2)ペアに対応できるかどうかによって異なります。
このバッファーのサイズは、sort_buffer_sizeパラメーターによって制御されます。
此外一次排序需要两次IO,一次是捞(id,col2),第二次是捞(col1,col2,col3),返される結果セットはcol2でソートされているため、IDの順序が正しくありません通过乱序的id去捞(col1,col2,col3)时会产生大量的随机IO。2回目MySQL本身一个优化、つまり、IDはソートされ、フィッシングの前にバッファに入れられます。バッファのサイズが変更され参数read_rnd_buffer_size控制、ランダムIOをシーケンシャルIOに変換するためにレコードが並べ替えられます。

並べ替えを最適化
ソート自体に加えて、従来のソート方法では2つの追加IOが必要です。従来のソートと比較して、最適化されたソート方法は2番目のIOを削減します。
主要区别在于,放入sort buffer不是(id,col2),而是(col1,col2,col3)。並べ替えバッファにはクエリに必要なすべてのフィールドが含まれているため、並べ替えが完了した直後に返すことができます无需二次捞数据。このアプローチの代償はそれ同样大小的sort buffer,能存放的(col1,col2,col3)数目要小于(id,col2),如果sort buffer不够大,可能导致需要写临时文件であり、追加のIOが発生します。もちろん、MySQLは参数max_length_for_sort_data、ソートタプルがmax_length_for_sort_data未満の場合にのみ、最適化されたソート方法を使用できると規定しています。それ以外の場合は、従来のソート方法のみを使用できます。

優先キューの並べ替え
を取得するには
最终的排序结果、何があっても、戻る前に条件を満たすすべてのレコードを並べ替える必要があります。最適化されたソート方法と比較して、まだ最適化の余地はありますか?5.6版本针对Order by limit M,N语句,在空间层面做了优化、この方法で、新しい並べ替え方法-優先度付きキューを追加しました采用堆排序实现。ヒープソートアルゴリズムの特性は適切解limit M,N 这类排序的问题ですが、すべての要素をソートする必要があります但是只需要M+N个元组的sort buffer空间即可。MとNが小さいシーンでは、ソートバッファが不十分なため、基本的に一時ファイルをマージしてソートする必要はありません。昇順の場合は大きいトップヒープが使用され、最後のヒープの要素が最小のN要素を形成します。降順の場合は小さいトップヒープが使用され、最後のヒープの要素が最大のN要素を形成します。
一貫性のない順序
案例1 Mysql从5.5迁移到5.6以后,发现分页出现了重复值。
测试表与数据:
create table t1(id int primary key, c1 int, c2 varchar(128));
insert into t1 values(1,1,'a');
insert into t1 values(2,2,'b');
insert into t1 values(3,2,'c');
insert into t1 values(4,2,'d');
insert into t1 values(5,3,'e');
insert into t1 values(6,4,'f');
insert into t1 values(7,5,'g');
只有5.6版本会出现以下情况。假设每页3条记录,第一页limit 0,3和第二页limit 3,3查询结果如下:
select * from t1 order by c1 asc limit 0,3;
select * from t1 order by c1 asc limit 3,3;

ID 4のレコードは、実際には2つのクエリに同時に表示されますが、これは明らかに期待どおりではなく、バージョン5.5ではそのような問題はありません。
产生这个现象的原因就是5.6针对limit M,N的语句采用了优先队列、および優先度キューはヒープを使用して実装されます。たとえば、上記の例では、c1 asc制限0、3による順序付けには、サイズ3の大きなトップヒープが必要です。制限3、3には、サイズ6の大きなトップヒープが必要です。c1が2である3つのレコードがある而堆排序是非稳定的(对于相同的key值,无法保证排序后与排序前的位置一致),所以导致分页重复的现象。ため、この問題を回避するために我们可以在排序中加上唯一值,比如主键id、IDは一意であるため、並べ替えに含まれるキー値が同じでないことを確認してください。次のようにSQLを記述します。
select * from t1 order by c1,id asc limit 0,3;
select * from t1 order by c1,id asc limit 3,3;
案例2 两个类似的查询语句,除了返回列不同,其它都相同,但排序的结果不一致。
测试表与数据:
create table t2(id int primary key, status int, c1 varchar(255),c2 varchar(255),c3 varchar(255),key(c1));
insert into t2 values(7,1,'a',repeat('a',255),repeat('a',255));
insert into t2 values(6,2,'b',repeat('a',255),repeat('a',255));
insert into t2 values(5,2,'c',repeat('a',255),repeat('a',255));
insert into t2 values(4,2,'a',repeat('a',255),repeat('a',255));
insert into t2 values(3,3,'b',repeat('a',255),repeat('a',255));
insert into t2 values(2,4,'c',repeat('a',255),repeat('a',255));
insert into t2 values(1,5,'a',repeat('a',255),repeat('a',255));
分别执行SQL语句:
select id,status,c1,c2 from t2 force index(c1) where c1>='b' order by status;
select id,status from t2 force index(c1) where c1>='b' order by status;
执行结果如下:5.7.26是查询结果是一样的,原作者可能使用的是5.6.16

看看两者的执行计划是否相同
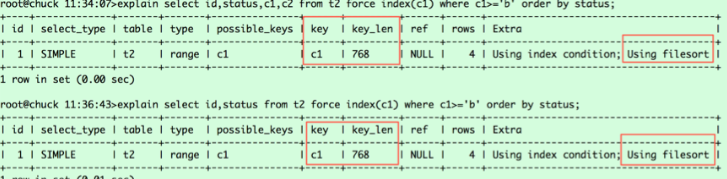
5.7.26的测试环境下数据

問題を説明するために、ステートメントにforceインデックスのヒントを追加して、c1列インデックスに移動できるようにしました。このステートメントは、c1列インデックスを介してIDを取得してから、返された列をテーブルから取得します。c1列の値によると、c1インデックスに記録される相対位置は次のとおりです。
(c1、id)===(b、6)、(b、3)、(5、c)、(c、 2)、対応するステータス値は2 3 24です。テーブルからデータを取得し、ステータスで並べ替えると、相対位置は(6,2、b)、(5,2、c)、(3,3、c)、(2,4、c)になります。これは、最初の2ステートメントのクエリによって返される結果では、なぜ最初のクエリステートメント(6,2、b)、(5,2、c)が逆になるのでしょうか。これは、前述のa。従来の並べ替えとb。最適化された並べ替えで赤でマークされた部分によって異なりますが、その理由は理解できます。最初のクエリによって返される列のバイト数がmax_length_for_sort_dataを超えるため、ソートは従来のソートになります。この場合、MYSQLはROWIDをソートし、ランダムIOをシーケンシャルIOに変換します。したがって、戻り値は最初に5、6が戻る; 2番目のクエリは最適化された並べ替えを使用します。2回目にデータをフェッチするプロセスはなく、並べ替え後のレコードの相対位置が維持されます。最初のステートメントで、最適化された並べ替えを使用する場合は、我们将max_length_for_sort_data设置调大即可,比如2048。

以上原文链接https://www.cnblogs.com/cchust/p/5304594.html
リンク
この記事では、主な技術コンテンツは、インターネットテクノロジーの巨人の共有と、一部の自己処理(注釈の役割のみ)に由来することを説明しています。関連する質問がある場合は、確認後にメッセージを残してください。侵害の実装は削除されます