記事のディレクトリ
このチュートリアルでは、ヒープソートアルゴリズムがどのように機能するかを学習します。さらに、C言語を使用した例があります。
ヒープソートは、コンピュータプログラミングで人気のある効果的なソートアルゴリズムです。ヒープソートアルゴリズムの記述方法を学ぶには、配列とツリーの2種類のデータ構造を理解する必要があります。
並べ替える数値の初期セットを[10、3、76、34、23、32]などの配列に格納します。並べ替えた後、並べ替えられた配列[3,10,23,32,34、76]を取得します。 ]。ヒープソートの動作原理は、配列の要素をヒープと呼ばれる特別なタイプの完全なバイナリツリーとして視覚化することです。
配列インデックスとツリー要素の関係
完全な二分木には興味深い特性があり、それを使用して任意のノードの子ノードと親ノードを見つけることができます。
配列内の要素のインデックスがiの場合、インデックス2i + 1の要素が左の子になり、インデックス2i +2の要素が右の子になります。さらに、インデックスiの要素の親要素は、(i-1)/ 2の下限によって与えられます。
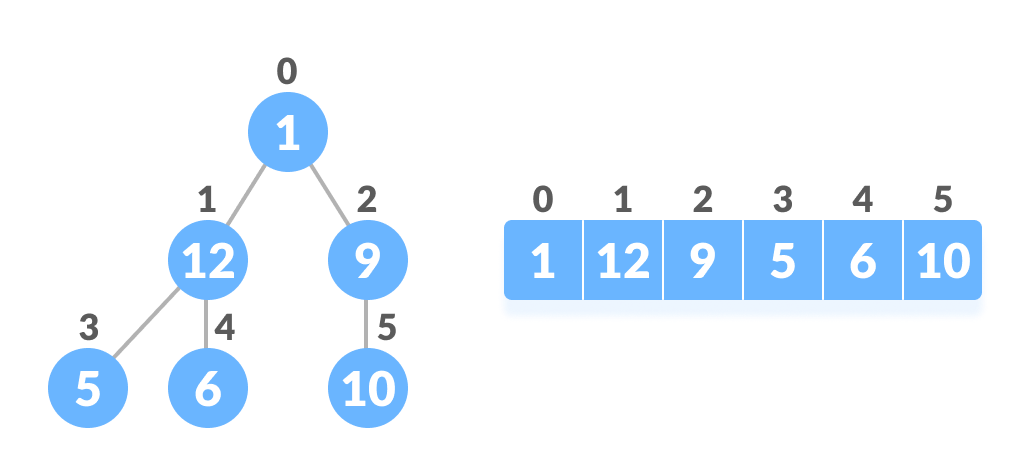
それをテストしてみましょう、
Left child of 1 (index 0)
= element in (2*0+1) index
= element in 1 index
= 12
Right child of 1
= element in (2*0+2) index
= element in 2 index
= 9
Similarly,
Left child of 12 (index 1)
= element in (2*1+1) index
= element in 3 index
= 5
Right child of 12
= element in (2*1+2) index
= element in 4 index
= 6
また、任意のノードの親ノードの検索にルールが適用されることを確認する必要があります
Parent of 9 (position 2)
= (2-1)/2
= ½
= 0.5
~ 0 index
= 1
Parent of 12 (position 1)
= (1-1)/2
= 0 index
= 1
配列インデックスのツリー位置へのこのマッピングを理解することは、ヒープデータ構造がどのように機能するか、およびそれを使用してヒープソートを実装する方法を理解するために重要です。
ヒープデータ構造とは何ですか?
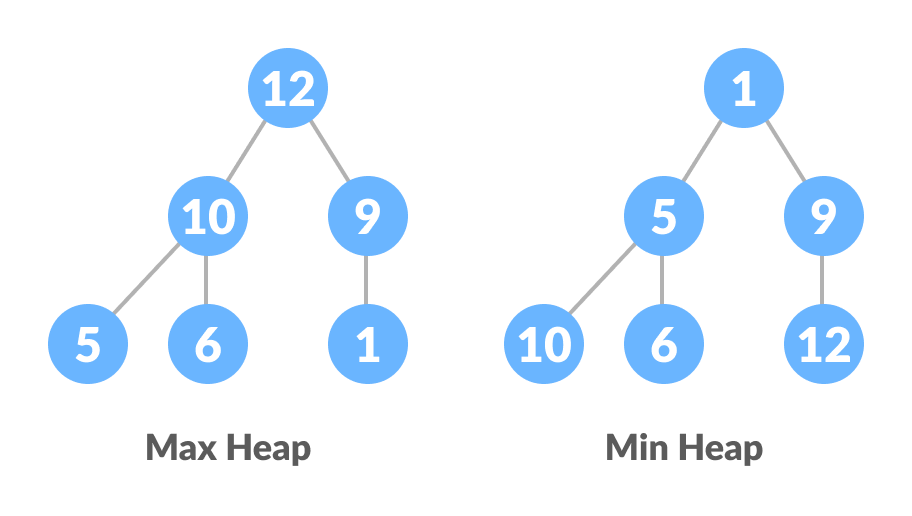
ヒープは、特別なツリーベースのデータ構造です。次の条件が満たされる場合、バイナリツリーはヒープデータ構造に従うと言われます。
- 完全な二分木です
- ツリー内のすべてのノードは、子ノードよりも大きいというプロパティに従います。つまり、最大の要素はルートにあり、すべての子ノードはルートノードよりも小さいというようになります。このようなヒープは、最大ヒープと呼ばれます。逆に、すべてのノードがその子ノードよりも小さい場合、それは最小ヒープと呼ばれます。
以下のサンプルグラフは、最大ヒープと最小ヒープを示しています。
木を「積み重ねる」方法
完全なバイナリツリーから始めて、ヒープのすべての非リーフ要素でheapifyと呼ばれる関数を実行することにより、最大ヒープに変更できます。
heapifyは再帰を使用するため、理解するのは困難です。それでは、最初に3つの要素でツリーを積み上げる方法を考えてみましょう。
heapify(array)
Root = array[0]
Largest = largest( array[0] , array [2*0 + 1]. array[2*0+2])
if(Root != Largest)
Swap(Root, Largest)
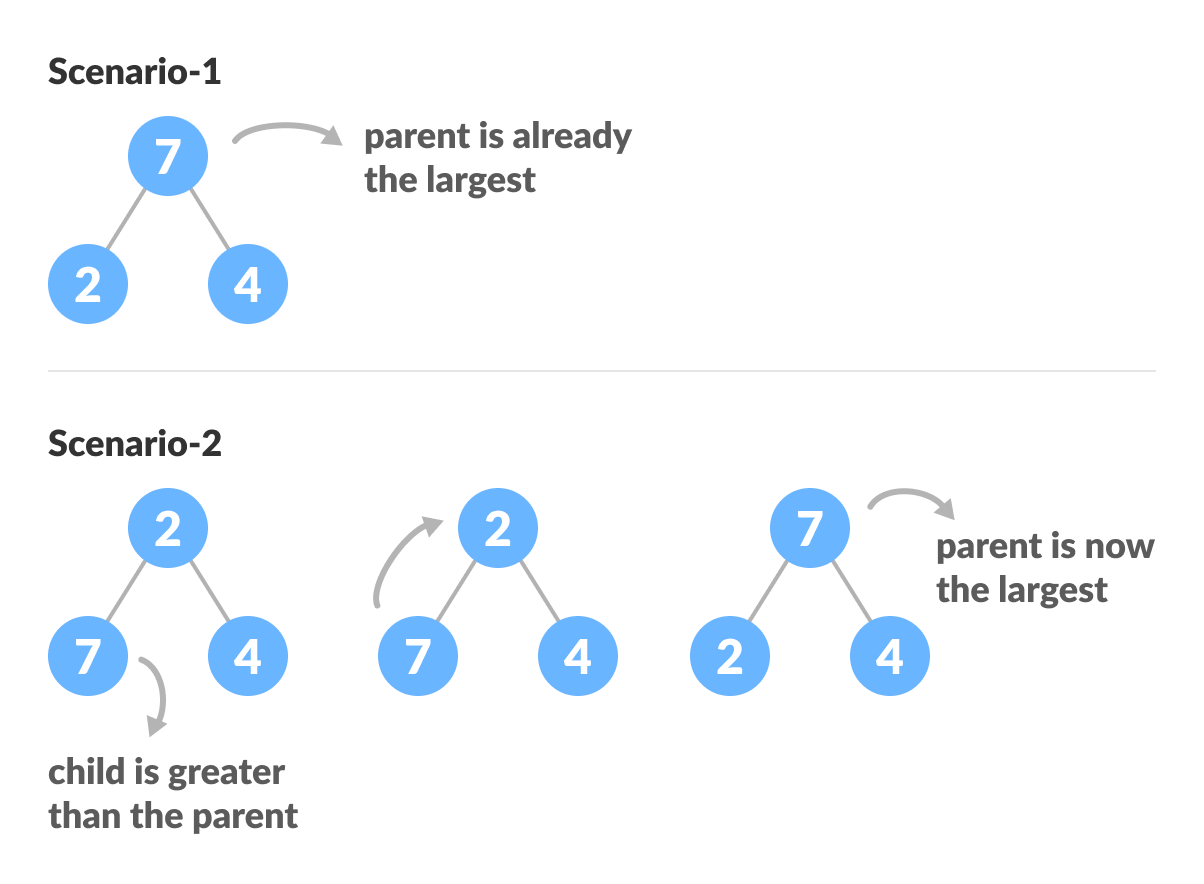
上記の例は、2つの状況を示しています。1つのケースでは、ルートが最大の要素であり、操作を実行する必要はありません。もう1つのケースでは、ルートに大きな子要素があり、にスワップする必要があります。最大ヒープ属性を維持します。
以前に再帰的アルゴリズムを使用したことがある場合は、これが基本的な状況である必要があると判断した可能性があります。
ここで、複数のレベルがある別のシナリオを考えてみましょう。
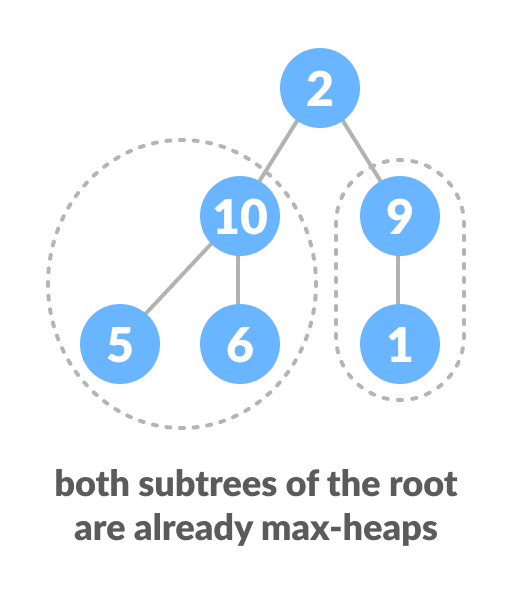
最上位の要素は最大のヒープではありませんが、すべてのサブツリーが最大のヒープです。
ツリー全体の最大ヒーププロパティを維持するには、正しい位置に到達するまで2を押し続ける必要があります。
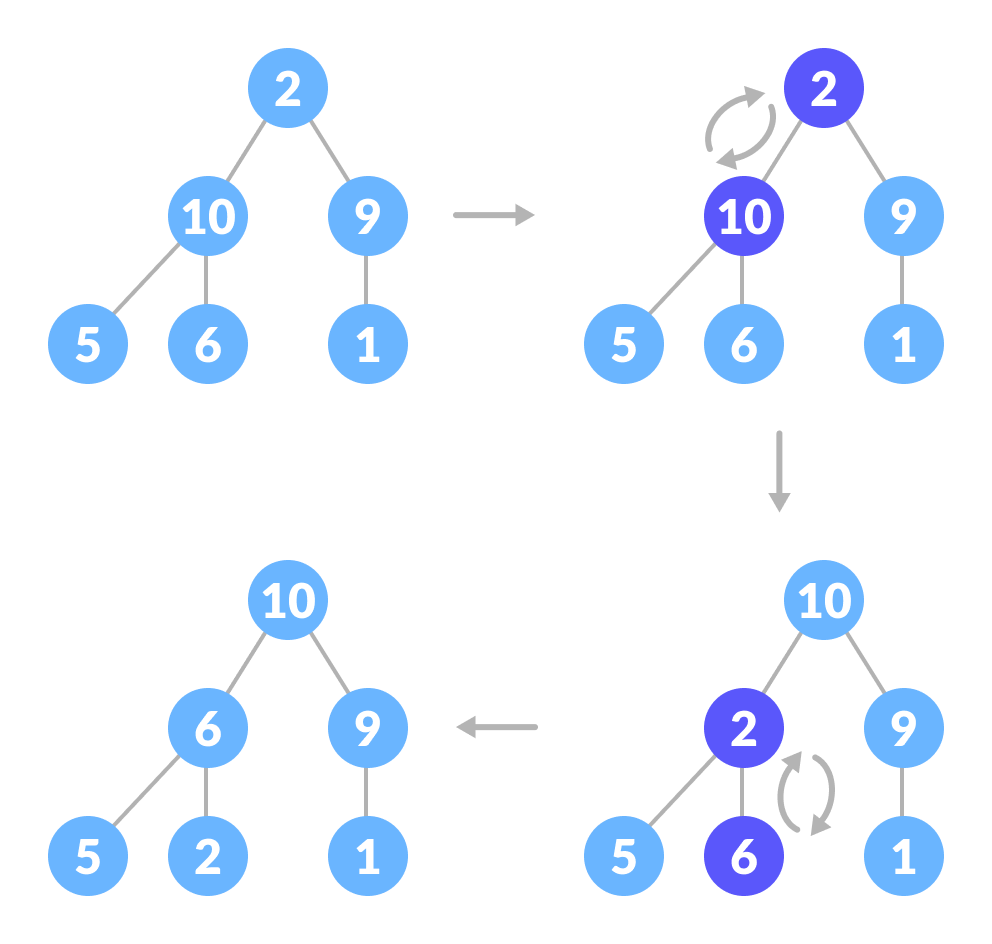
したがって、両方のサブツリーが最大のヒープであるツリーで最大ヒープ属性を維持するには、ルート要素が子要素よりも大きくなるか、リーフノードになるまで、ルート要素でheapifyを繰り返し実行する必要があります。
これらの2つの条件をheapify関数で組み合わせることができます。
void heapify(int arr[], int n, int i) {
// Find largest among root, left child and right child
int largest = i;
int left = 2 * i + 1;
int right = 2 * i + 2;
if (left < n && arr[left] > arr[largest])
largest = left;
if (right < n && arr[right] > arr[largest])
largest = right;
// Swap and continue heapifying if root is not largest
if (largest != i) {
swap(&arr[i], &arr[largest]);
heapify(arr, n, largest);
}
}
この関数は、基本的なケースやあらゆるサイズのツリーに適しています。したがって、サブツリーが最大のヒープである限り、ルート要素を正しい位置に移動して、任意のツリーの最大のヒープ状態を維持できます。
最大ヒープを構築する
任意のツリーから最大ヒープを構築するために、各サブツリーを下から上にヒープし、ルート要素を含むすべての要素に関数を適用した後に最大ヒープを取得できます。
完全なツリーの場合、非リーフノードの最初のインデックスはn / 2-1で与えられます。その後の他のすべてのノードはリーフノードであるため、ヒープする必要はありません。
したがって、最大ヒープを構築できます。
// Build heap (rearrange array)
for (int i = n / 2 - 1; i >= 0; i--)
heapify(arr, n, i);
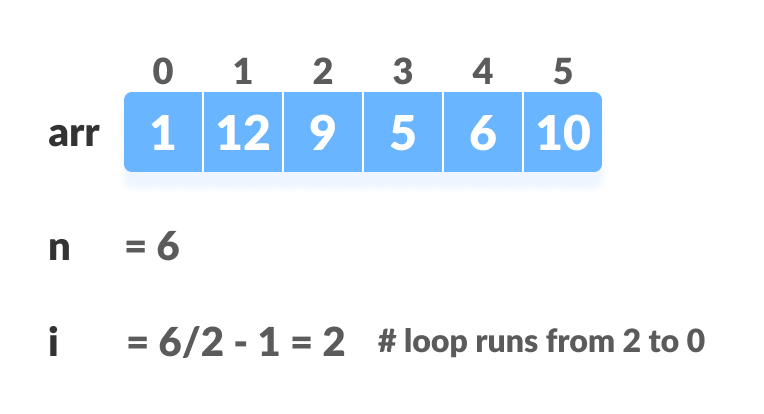
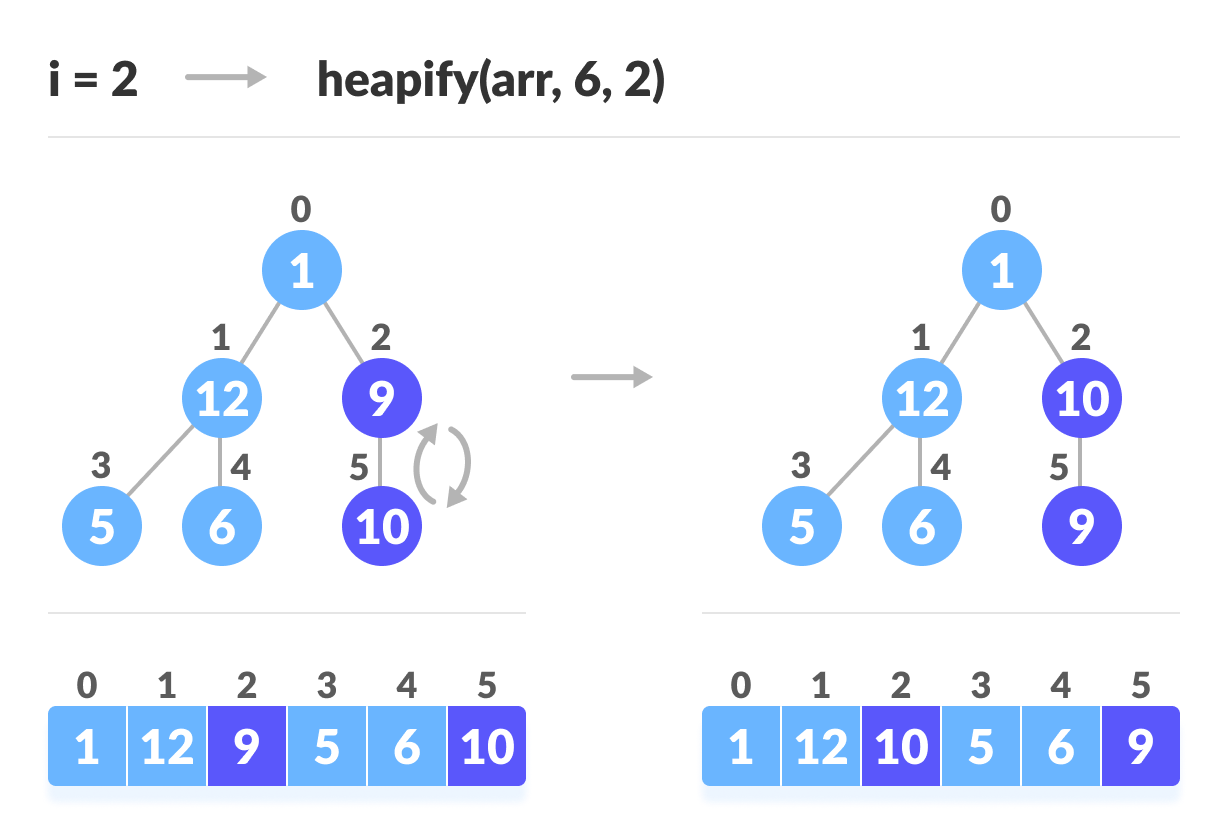
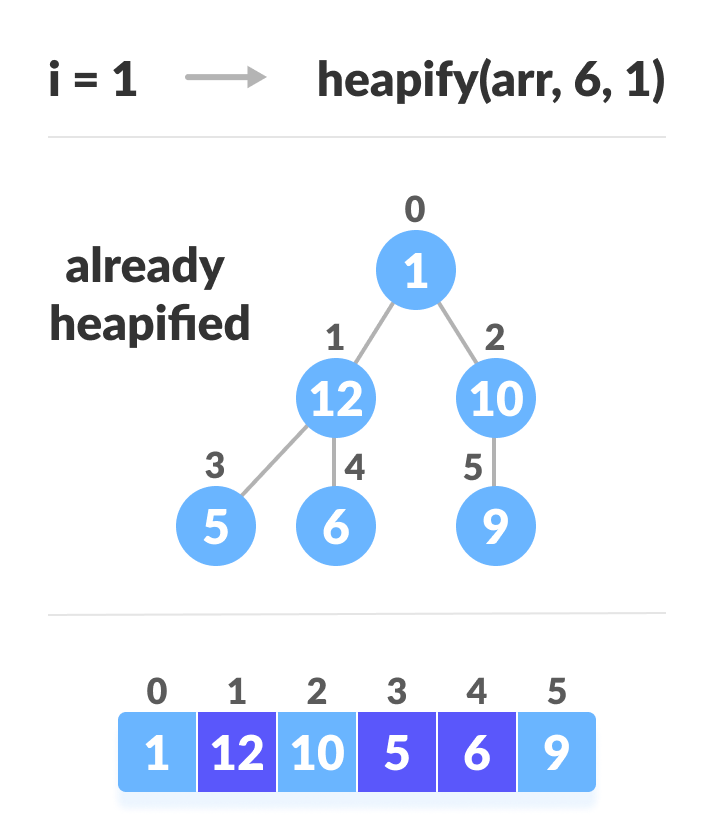
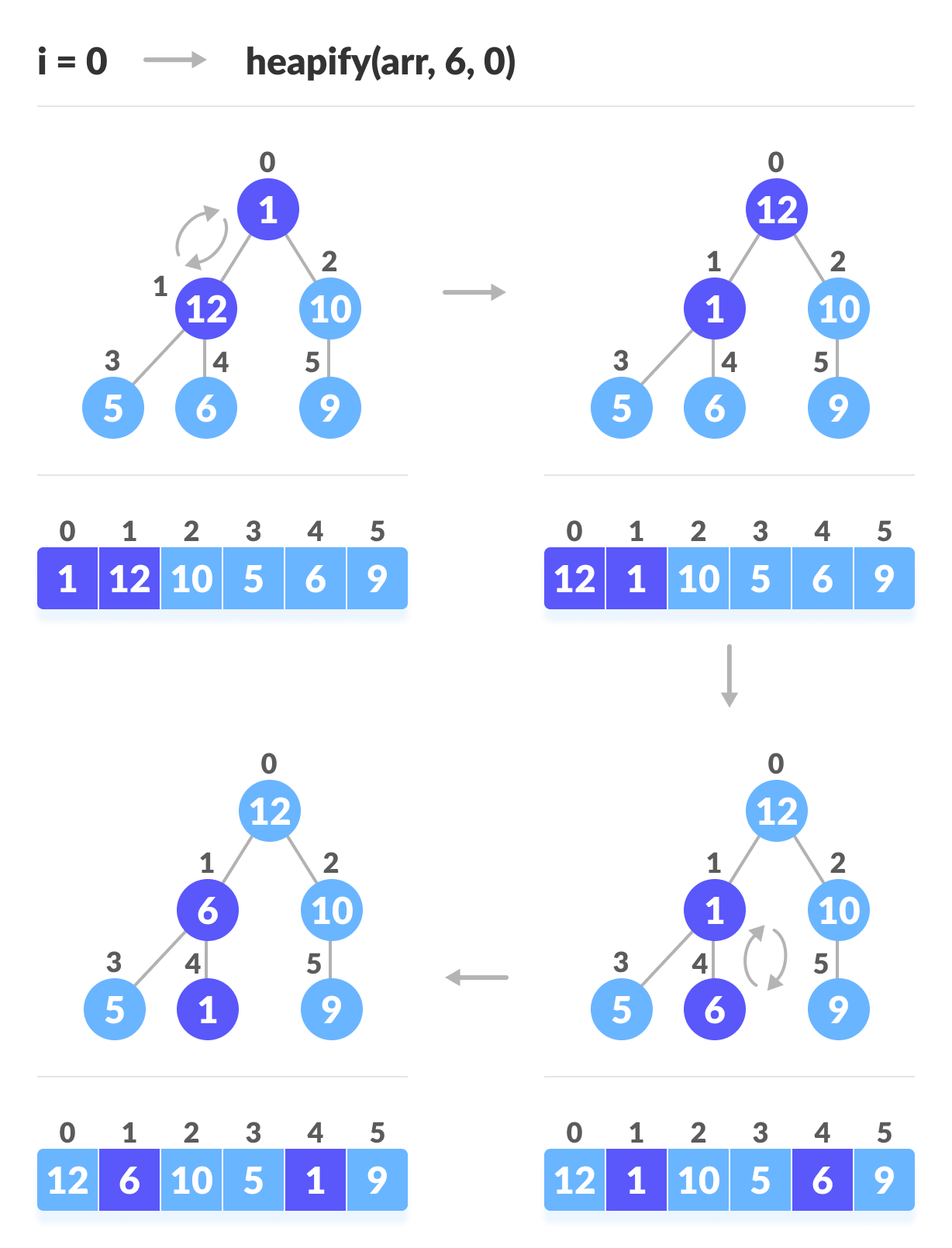
上の図に示すように、最初に最小の木を積み上げてから、ルート要素に到達するまで徐々に上に移動します。
これまでにすべてを学んだら、おめでとうございます。ヒープソートをマスターするための道を進んでいます。
ヒープソートはどのように機能しますか?
- ツリーは最大ヒーププロパティを満たしているため、最大のアイテムがルートノードに格納されます。
- スワップ:ルート要素を削除して配列の最後(n番目の位置)に配置し、ツリーの最後の項目(ヒープ)を空の位置に配置します。
- 削除:ヒープサイズを1つ減らします。
- Heapify:ルート要素が再びヒープ化され、ルートに最も高い要素が含まれるようになります。
- リスト内のすべてのアイテムがソートされるまで、このプロセスを繰り返します。
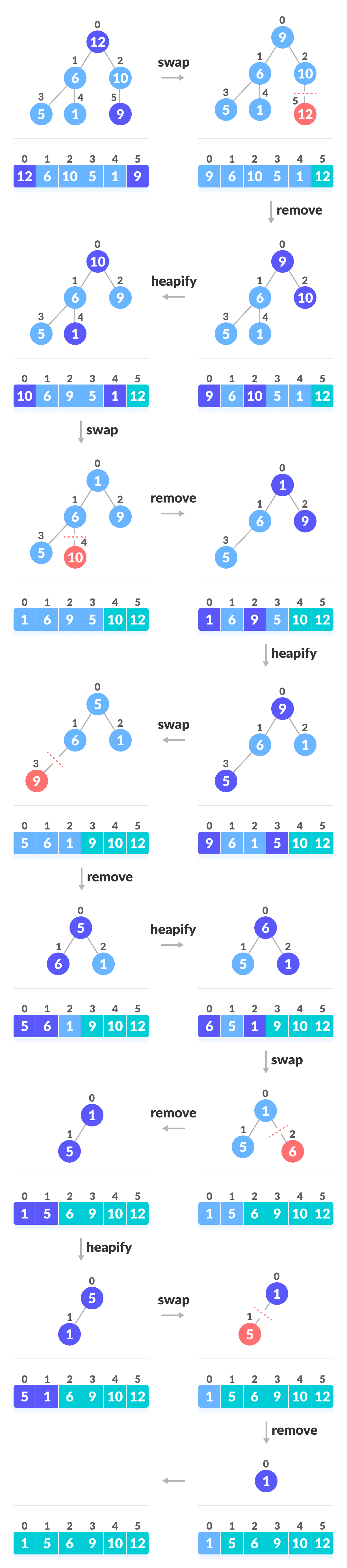
次のコードは操作を示しています。
// Heap sort
for (int i = n - 1; i >= 0; i--) {
swap(&arr[0], &arr[i]);
// Heapify root element to get highest element at root again
heapify(arr, i, 0);
}
Cの例
// Heap Sort in C
#include <stdio.h>
// Function to swap the the position of two elements
void swap(int *a, int *b) {
int temp = *a;
*a = *b;
*b = temp;
}
void heapify(int arr[], int n, int i) {
// Find largest among root, left child and right child
int largest = i;
int left = 2 * i + 1;
int right = 2 * i + 2;
if (left < n && arr[left] > arr[largest])
largest = left;
if (right < n && arr[right] > arr[largest])
largest = right;
// Swap and continue heapifying if root is not largest
if (largest != i) {
swap(&arr[i], &arr[largest]);
heapify(arr, n, largest);
}
}
// Main function to do heap sort
void heapSort(int arr[], int n) {
// Build max heap
for (int i = n / 2 - 1; i >= 0; i--)
heapify(arr, n, i);
// Heap sort
for (int i = n - 1; i >= 0; i--) {
swap(&arr[0], &arr[i]);
// Heapify root element to get highest element at root again
heapify(arr, i, 0);
}
}
// Print an array
void printArray(int arr[], int n) {
for (int i = 0; i < n; ++i)
printf("%d ", arr[i]);
printf("\n");
}
// Driver code
int main() {
int arr[] = {
1, 12, 9, 5, 6, 10};
int n = sizeof(arr) / sizeof(arr[0]);
heapSort(arr, n);
printf("Sorted array is \n");
printArray(arr, n);
}
ヒープソートの複雑さ
ヒープソートは、すべてのケース(最良のケース、平均的なケース、および最悪のケース)でO(nlog n)の時間計算量を持ちます。
その理由を理解しましょう。n個の要素を含む完全な二分木の高さはlognです。
前に見たように、すでに最大のヒープであるサブツリーの要素を完全にスタックするには、要素をその左右の子要素と常に比較し、対応するポイントに到達するまで押し下げる必要があります。両方の子要素はそれよりも小さいです。
最悪の場合、log(n)の倍数を比較して交換するために、要素をルートからリーフノードに移動する必要があります。
最大ヒープを構築する段階では、n / 2要素に対してこの操作を実行するため、ヒープを構築するステップの最悪の場合の複雑さはn / 2 * log n〜nlognです。
並べ替えのステップでは、ルート要素を最後の要素と交換し、ルート要素をスタックします。要素をルートからリーフに交換する必要がある場合があるため、要素ごとに最大でlogn時間かかります。したがって、n回繰り返すと、ヒープソートステップで費やされる時間はnlognになります。
さらに、最大ヒープを構築するステップ(build_max_heap)とヒープソート(heap_sort)が次々に実行されるため、アルゴリズムの複雑さは指数関数的に増加することはありませんが、nlognのレベルのままになります。
ヒープソートのスペースの複雑さはO(1)です。クイックソートと比較すると、最悪の場合はO(nlog n)の方が優れています。クイックソートの最悪のケースはO(n 2 n ^ 2n2)。ただし、その他の場合は、クイックソートの方が高速です。イントロソートはヒープソートの代替手段であり、クイックソートとヒープソートを組み合わせて、最悪の場合のヒープソートの速度とクイックソートの平均速度の両方の利点を保持します。
ヒープソートの適用
ヒープソートの実行時間にはO(nlogn)の上限があり、補助ストレージの上限は一定のO(1)であるため、セーフティ関連システムおよび組み込みシステム(Linuxカーネルなど)はヒープソートを使用します。
ヒープソートは、最悪の場合でもO(nlogn)の時間計算量がありますが、アプリケーションはこれ以上ありません(クイックソートやマージソートなどの他のソートアルゴリズムと比較して)。ただし、残りのアイテムの順序を考慮せずにアイテムのリストから最小(または最大)のデータを抽出する場合は、基本的なデータ構造であるヒープを使用できます。たとえば、優先キュー。
参照文書
[1]パレワラボPvt。Ltd.ヒープソートアルゴリズム[EB / OL] .https://www.programiz.com/dsa/heap-sort,2021-01-01。