1はじめに
この記事のテキストと写真はインターネットからのものであり、学習とコミュニケーションのみを目的としており、商用目的ではありません。ご不明な点がございましたら、処理についてお問い合わせください。
PS:Pythonの学習教材が必要な場合は、以下のリンクをクリックして自分で入手できます
Pythonの無料の学習資料、コード、交換回答クリックして参加
映画を見る前に「Douban」に行って映画のレビューを見る人が多いので、44130個の「Douban」ユーザー視聴データをクロールして、ユーザーの関係、映画のつながり、ユーザーと映画の隠蔽を分析しました。 。関係。

2.表示データをクロールします
データソース
https://movie.douban.com/

「Douban」プラットフォームでデータを表示しているユーザーをクロールします。
ユーザーリストをクロールする
Web分析
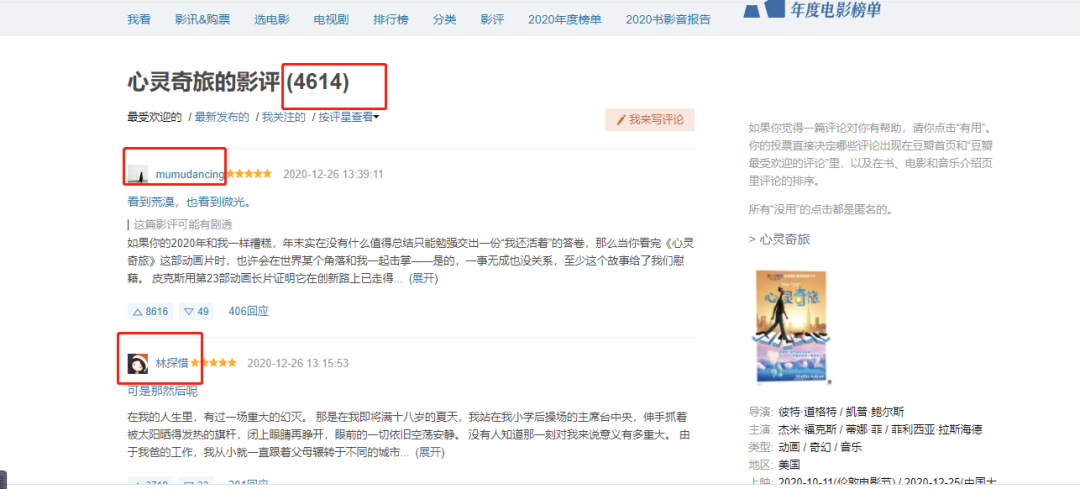
ユーザーを獲得するために、コメントしたユーザーに応じてユーザー名を取得できるように、いずれかの映画の映画レビューを選択しました(ユーザー名は、後でユーザーの視聴記録をクロールするためにのみ必要です)。
https://movie.douban.com/subject/24733428/reviews?start=0
URLの開始パラメーターはページ数(ページ* 20、1ページあたり20データ)であるため、start = 0、20、40 ...は20の倍数であり、これらの4614ユーザーを変更することで取得できます。開始パラメーター値名前。
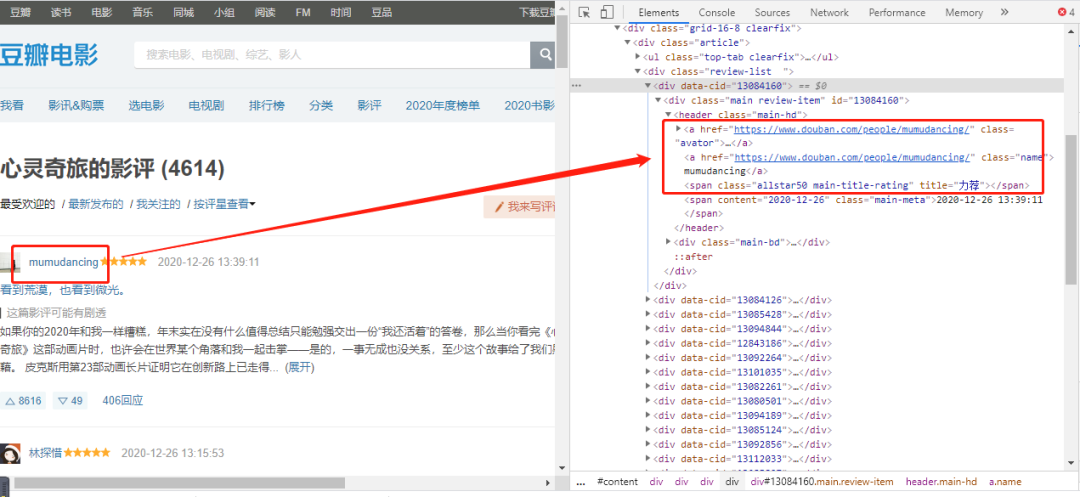
ウェブページのラベルを確認すると、「ユーザー名」の値に対応するラベル属性が見つかります。
プログラミングの実現
i=0
url = "https://movie.douban.com/subject/24733428/reviews?start=" + str(i * 20)
r = requests.get(url, headers=headers)
r.encoding = 'utf8'
s = (r.content)
selector = etree.HTML(s)
for item in selector.xpath('//*[@class="review-list "]/div'):
userid = (item.xpath('.//*[@class="main-hd"]/a[2]/@href'))[0].replace("https://www.douban.com/people/","").replace("/", "")
username = (item.xpath('.//*[@class="main-hd"]/a[2]/text()'))[0]
print(userid)
print(username)
print("-----")

ユーザーの閲覧記録をクロールする
前の手順では、「ユーザー名」がクロールされ、次に「ユーザー名」がユーザーの表示レコードをクロールするために必要になります。
Web分析
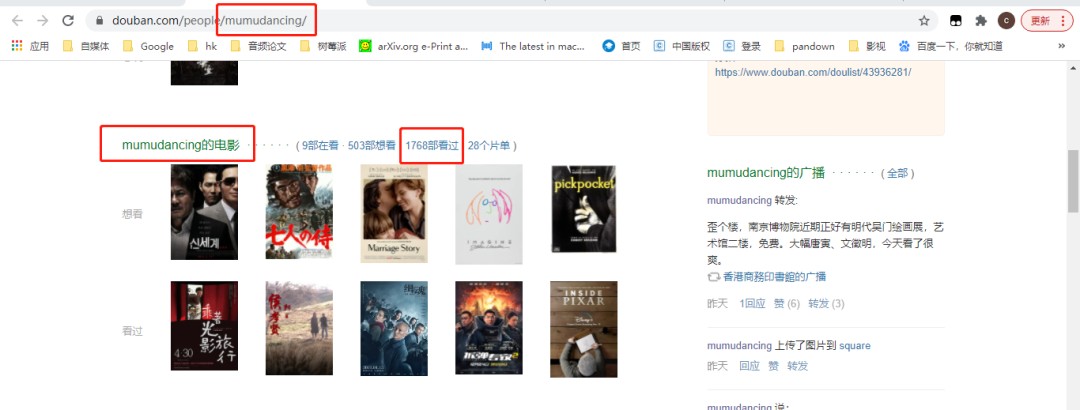

#https://movie.douban.com/people/{用户名称}/collect?start=15&sort=time&rating=all&filter=all&mode=grid
https://movie.douban.com/people/mumudancing/collect?start=15&sort=time&rating=all&filter=all&mode=grid
「ユーザー名」を変更することで、さまざまなユーザーの視聴記録を取得できます。
URLの開始パラメーターはページ数(ページ* 15、1ページあたり15個のデータ)であるため、start = 0、15、30 ...は15の倍数であり、次の方法でこれらの1768ビューを取得できます。開始パラメータの値を変更するフィルムレコードは言った。
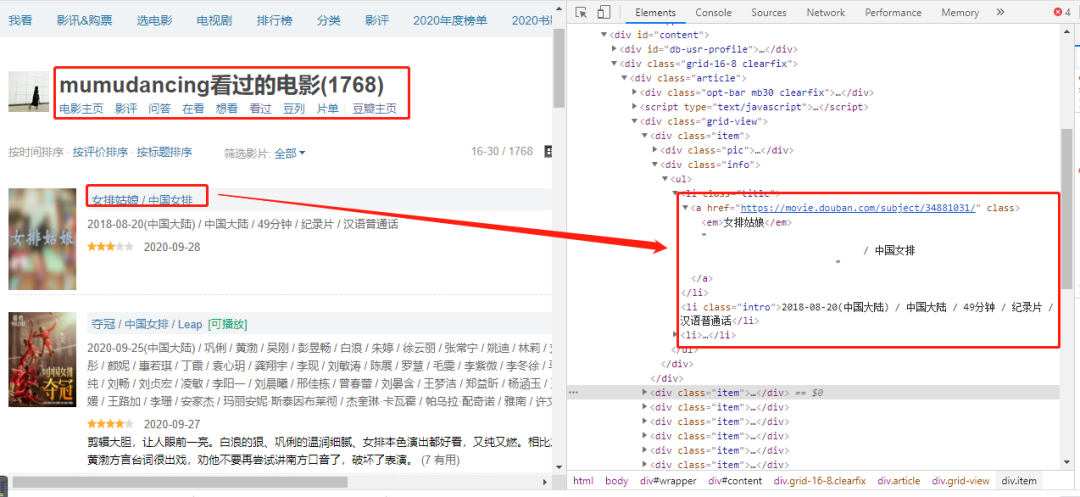
ウェブページのタグを確認すると、「映画名」の値に対応するタグ属性が見つかります。
プログラミングの実現
url = "https://movie.douban.com/people/mumudancing/collect?start=15&sort=time&rating=all&filter=all&mode=grid"
r = requests.get(url, headers=headers)
r.encoding = 'utf8'
s = (r.content)
selector = etree.HTML(s)
for item in selector.xpath('//*[@class="grid-view"]/div[@class="item"]'):
text1 = item.xpath('.//*[@class="title"]/a/em/text()')
text2 = item.xpath('.//*[@class="title"]/a/text()')
text1 = (text1[0]).replace(" ", "")
text2 = (text2[1]).replace(" ", "").replace("\n", "")
print(text1+text1)
print("-----")

優れた保存
ヘッダーを定義する
# 初始化execl表
def initexcel(filename):
# 创建一个workbook 设置编码
workbook = xlwt.Workbook(encoding='utf-8')
# 创建一个worksheet
worksheet = workbook.add_sheet('sheet1')
workbook.save(str(filename)+'.xls')
##写入表头
value1 = [["用户", "影评"]]
book_name_xls = str(filename)+'.xls'
write_excel_xls_append(book_name_xls, value1)
エクセルシートには2つのタイトルがあります(ユーザー、映画レビュー)
卓越するために書く
# 写入execl
def write_excel_xls_append(path, value):
index = len(value) # 获取需要写入数据的行数
workbook = xlrd.open_workbook(path) # 打开工作簿
sheets = workbook.sheet_names() # 获取工作簿中的所有表格
worksheet = workbook.sheet_by_name(sheets[0]) # 获取工作簿中所有表格中的的第一个表格
rows_old = worksheet.nrows # 获取表格中已存在的数据的行数
new_workbook = copy(workbook) # 将xlrd对象拷贝转化为xlwt对象
new_worksheet = new_workbook.get_sheet(0) # 获取转化后工作簿中的第一个表格
for i in range(0, index):
for j in range(0, len(value[i])):
new_worksheet.write(i+rows_old, j, value[i][j]) # 追加写入数据,注意是从i+rows_old行开始写入
new_workbook.save(path) # 保存工作簿
書き込みExcel関数を定義します。これにより、データの各ページが取得されると、書き込み関数が呼び出されてデータがExcelに保存されます。
最後に、44130個のデータが収集されました(元々は4614人のユーザーで、各ユーザーは約500〜1,000個のデータを持っており、推定で400万個のデータがあります)。ただし、分析プロセスを示すために、各ユーザーの最初の30個の表示レコードのみがクロールされます(最初の30個が最新であるため)。
3.データ分析とマイニング
データセットの読み取り
def read_excel():
# 打开workbook
data = xlrd.open_workbook('豆瓣.xls')
# 获取sheet页
table = data.sheet_by_name('sheet1')
# 已有内容的行数和列数
nrows = table.nrows
datalist=[]
for row in range(nrows):
temp_list = table.row_values(row)
if temp_list[0] != "用户" and temp_list[1] != "影评":
data = []
data.append([str(temp_list[0]), str(temp_list[1])])
datalist.append(data)
return datalist

Douban.xlsからすべてのデータを読み取り、データリストコレクションに入れます。
分析1:映画視聴のランキング
###分析1:电影观看次数排行
def analysis1():
dict ={}
###从excel读取数据
movie_data = read_excel()
for i in range(0, len(movie_data)):
key = str(movie_data[i][0][1])
try:
dict[key] = dict[key] +1
except:
dict[key]=1
###从小到大排序
dict = sorted(dict.items(), key=lambda kv: (kv[1], kv[0]))
name=[]
num=[]
for i in range(len(dict)-1,len(dict)-16,-1):
print(dict[i])
name.append(((dict[i][0]).split("/"))[0])
num.append(dict[i][1])
plt.figure(figsize=(16, 9))
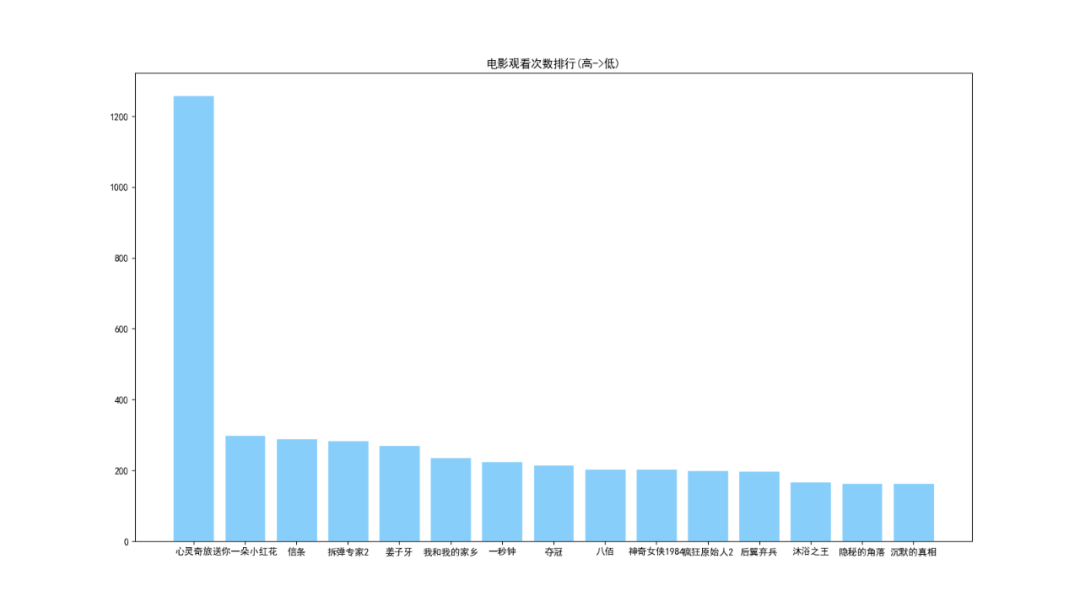
plt.title('电影观看次数排行(高->低)')
plt.bar(name, num, facecolor='lightskyblue', edgecolor='white')
plt.savefig('电影观看次数排行.png')
分析
1.ユーザー情報は「SpiritTravel」のコメントから来ているので、そのユーザーが最も多くのビューを持っています。
2.最新のヒット映画で、2番目に人気のあるのは「SendYou A Little Red Flower」で、次にCreed and Bomb Disposal Expert2が続きます。
分析2:ユーザーのポートレート(映画を見るユーザーの同じ割合が最も高い)
###分析2:用户画像(用户观影相同率最高)
def analysis2():
dict = {}
###从excel读取数据
movie_data = read_excel()
userlist=[]
for i in range(0, len(movie_data)):
user = str(movie_data[i][0][0])
moive = (str(movie_data[i][0][1]).split("/"))[0]
#print(user)
#print(moive)
try:
dict[user] = dict[user]+","+str(moive)
except:
dict[user] =str(moive)
userlist.append(user)
num_dict={}
# 待画像用户(取第一个)
flag_user=userlist[0]
movies = (dict[flag_user]).split(",")
for i in range(0,len(userlist)):
#判断是否是待画像用户
if flag_user != userlist[i]:
num_dict[userlist[i]]=0
#待画像用户的所有电影
for j in range(0,len(movies)):
#判断当前用户与待画像用户共同电影个数
if movies[j] in dict[userlist[i]]:
# 相同加1
num_dict[userlist[i]] = num_dict[userlist[i]]+1
###从小到大排序
num_dict = sorted(num_dict.items(), key=lambda kv: (kv[1], kv[0]))
#用户名称
username = []
#观看相同电影次数
num = []
for i in range(len(num_dict) - 1, len(num_dict) - 9, -1):
username.append(num_dict[i][0])
num.append(num_dict[i][1])
plt.figure(figsize=(25, 9))
plt.title('用户画像(用户观影相同率最高)')
plt.scatter(username, num, color='r')
plt.plot(username, num)
plt.savefig('用户画像(用户观影相同率最高).png')

分析
ユーザーのポートレートを作成する例として、ユーザー「mumudancing」を取り上げ
ます。1。図からわかるように、ユーザー「mumudancing」と同じ映画の視聴率が最も高いのは、「プラハに連れて行ってください」です。 「LiXiaowei」による。
2.ユーザー:「DesperateSolitaire」、「Stupid Kid」、「Private History」、「Wen Heng」、「Shen Tang」、「Xiu Zuo」、同じ割合の映画の視聴。
分析3:ユーザー間の映画の推薦
###分析3:用户之间进行电影推荐(与其他用户同时被观看过)
def analysis3():
dict = {}
###从excel读取数据
movie_data = read_excel()
userlist=[]
for i in range(0, len(movie_data)):
user = str(movie_data[i][0][0])
moive = (str(movie_data[i][0][1]).split("/"))[0]
#print(user)
#print(moive)
try:
dict[user] = dict[user]+","+str(moive)
except:
dict[user] =str(moive)
userlist.append(user)
num_dict={}
# 待画像用户(取第2个)
flag_user=userlist[0]
print(flag_user)
movies = (dict[flag_user]).split(",")
for i in range(0,len(userlist)):
#判断是否是待画像用户
if flag_user != userlist[i]:
num_dict[userlist[i]]=0
#待画像用户的所有电影
for j in range(0,len(movies)):
#判断当前用户与待画像用户共同电影个数
if movies[j] in dict[userlist[i]]:
# 相同加1
num_dict[userlist[i]] = num_dict[userlist[i]]+1
###从小到大排序
num_dict = sorted(num_dict.items(), key=lambda kv: (kv[1], kv[0]))
# 去重(用户与观影率最高的用户两者之间重复的电影去掉)
user_movies = dict[flag_user]
new_movies = dict[num_dict[len(num_dict)-1][0]].split(",")
for i in range(0,len(new_movies)):
if new_movies[i] not in user_movies:
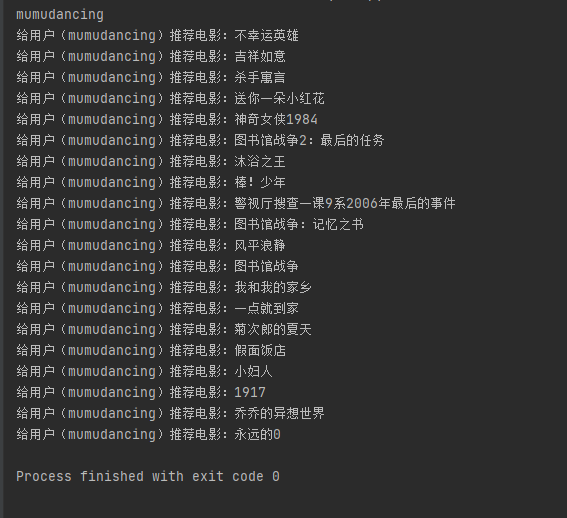
print("给用户("+str(flag_user)+")推荐电影:"+str(new_movies[i]))
分析
たとえば、ユーザー間の「mumudancing」は、映画を推奨し
ます1.ユーザーのmumudancingの視聴率(A)とユーザーの最も高い関連性に従って実施し、次にすべての視聴記録のユーザー(A)を取得します
2.ユーザー(A)の映画視聴記録は、ユーザー「mumudancing」(2つの間で重複する映画の削除)に推奨されます。
分析4:映画間の映画推薦
###分析4:电影之间进行电影推荐(与其他电影同时被观看过)
def analysis4():
dict = {}
###从excel读取数据
movie_data = read_excel()
userlist=[]
for i in range(0, len(movie_data)):
user = str(movie_data[i][0][0])
moive = (str(movie_data[i][0][1]).split("/"))[0]
try:
dict[user] = dict[user]+","+str(moive)
except:
dict[user] =str(moive)
userlist.append(user)
movie_list=[]
# 待获取推荐的电影
flag_movie = "送你一朵小红花"
for i in range(0,len(userlist)):
if flag_movie in dict[userlist[i]]:
moives = dict[userlist[i]].split(",")
for j in range(0,len(moives)):
if moives[j] != flag_movie:
movie_list.append(moives[j])
data_dict = {}
for key in movie_list:
data_dict[key] = data_dict.get(key, 0) + 1
###从小到大排序
data_dict = sorted(data_dict.items(), key=lambda kv: (kv[1], kv[0]))
for i in range(len(data_dict) - 1, len(data_dict) -16, -1):
print("根据电影"+str(flag_movie)+"]推荐:"+str(data_dict[i][0]))

分析
映画「SendYouA Little Red Flower」を例に取って、映画の合間に映画を推薦し
ます1.「SendYou a Little Red Flower」を視聴したすべてのユーザーを取得し、これらのユーザーのそれぞれの視聴記録を取得します。
2.これらの視聴記録を統計的に要約し(「小さな赤い花を送ってください」を削除)、高いものから低いものへと並べ替え、最後に映画「小さな赤い花を送ってください」の並べ替えられたコレクションと最も高い相関関係を取得します。
3.ユーザーとの関連性が最も高い上位15本の映画を推奨します。
4.まとめ
1. Doubanプラットフォームデータをクロールするアイデアを分析し、プログラミングによって実装します。
2.クロールされたデータを分析します(映画の視聴回数のランク付け、ユーザーのポートレート、ユーザー間の映画の推奨、映画間の映画の推奨)