1.インデックスの生成
-键(鍵)
まず、ほとんどの場合、測位操作はデータの行全体と一致する必要がないことがわかりました。代わりに、定期的に1つ
または複数の列値のみに一致します。つまり、特定の値または複数の列値がクエリ条件として使用されます。たとえば、図の最初の列を使用してレコードを識別することができます。データの一部を決定するために使用されるこれらの列は、
まとめてキーと呼ばれます。
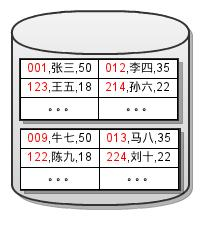
無効なデータアクセスを減らすという原則に従って、キー値を取得して別のブロックに保存します。そして
、元のデータブロックを指すように各キー値へのポインターを追加します。写真が示すように。

これは、「インデックス」の祖先である高密度インデックスです。位置決め操作が実行されると、テーブルスキャンは実行されなくなります。代わりに、
インデックススキャンを実行し、すべてのインデックスブロックを順番に読み取り、キーと値のマッチングを実行します。一致するキー値が見つかると
、対応するデータブロックが行のポインタに従って直接読み取られ、操作が実行されます。
次に、MySQLのインデックスの構文
インデックスを作成する
1.テーブルを作成するときにインデックスを追加します
CREATE TABLE mytable(
ID INT NOT NULL,
username VARCHAR(16) NOT NULL,
INDEX [indexName] (username(length))
);
2.テーブルの作成後にインデックスを追加します
ALTER TABLE my_table ADD [UNIQUE] INDEX index_name(column_name);
或者
CREATE INDEX index_name ON my_table(column_name);
3.インデックスに基づいてクエリを実行します
具体查询:
SELECT * FROM table_name WHERE column_1=column_2;(为column_1建立了索引)
或者模糊查询
SELECT * FROM table_name WHERE column_1 LIKE '%三'
SELECT * FROM table_name WHERE column_1 LIKE '三%'
SELECT * FROM table_name WHERE column_1 LIKE '%三%'
SELECT * FROM table_name WHERE column_1 LIKE '_好_'
如果要表示在字符串中既有A又有B,那么查询语句为:
SELECT * FROM table_name WHERE column_1 LIKE '%A%' AND column_1 LIKE '%B%';
SELECT * FROM table_name WHERE column_1 LIKE '[张李王]三'; //表示column_1中有匹配张三、李三、王三的都可以
SELECT * FROM table_name WHERE column_1 LIKE '[^张李王]三'; //表示column_1中有匹配除了张三、李三、王三的其他三都可以
//在模糊查询中,%表示任意0个或多个字符;_表示任意单个字符(有且仅有),通常用来限制字符串长度;[]表示其中的某一个字符;[^]表示除了其中的字符的所有字符
或者在全文索引中模糊查询
SELECT * FROM table_name WHERE MATCH(content) AGAINST('word1','word2',...);
4.インデックスを削除します
DROP INDEX my_index ON tablename;
或者
ALTER TABLE table_name DROP INDEX index_name;
5.テーブルのインデックスを表示します
SHOW INDEX FROM tablename
6.クエリステートメントでインデックスの使用を表示します
//explain 加查询语句
explain SELECT * FROM table_name WHERE column_1='123';
3つ目は、インデックスの長所と短所です。
利点:高速検索、I / O時間の短縮、検索の高速化、インデックスによるグループ化と並べ替えにより、グループ化と並べ替えを高速化できます。
短所:インデックス自体もテーブルであるため、ストレージスペースを占有します。一般的に、インデックステーブルが占めるスペースはデータテーブルの1.5倍です。インデックステーブルの保守と作成には、時間とコストがかかります。データ量が増えると、このコストも増加します。インデックスを作成すると、データテーブルの変更中にインデックステーブルを変更する必要があるため、データテーブルの変更操作(削除、追加、変更)の効率が低下します。
第四に、インデックスの分類
一般的なインデックスタイプは、主キーインデックス、一意のインデックス、通常のインデックス、フルテキストインデックス、複合インデックスです。
1.主キーインデックス:つまり、主キーpk_clolum(長さ)に従ってインデックスが付けられる主インデックスは、重複を許可せず、null値を許可しません。
ALTER TABLE 'table_name' ADD PRIMARY KEY pk_index('col');
2.一意のインデックス:インデックスの作成に使用される列の値は一意である必要があり、null値が許可されます
ALTER TABLE 'table_name' ADD UNIQUE index_name('col');
3.通常のインデックス:テーブル内の通常の列で構成されたインデックスで、制限はありません。
ALTER TABLE 'table_name' ADD INDEX index_name('col');
4.フルテキストインデックス:大きなテキストオブジェクトの列で構築されたインデックス
ALTER TABLE 'table_name' ADD FULLTEXT INDEX ft_index('col');
5.ジョイントインデックス:複数の列の組み合わせで構築されたインデックス。これらの複数の列の値にnull値を含めることはできません
ALTER TABLE 'table_name' ADD INDEX index_name('col1','col2','col3');
*「左端のプレフィックス」の原則に従い、検索または並べ替えに最も一般的に使用される列を左端に降順で配置します。ジョイントインデックスは、col1、col1col2、col1col2col3、3つのインデックス、およびcol2またはcol3の確立に相当します。インデックスは使用できません。
*複合インデックスを使用する場合、列名の長さが長すぎるためにインデックスのキーが長すぎて効率が低下する可能性があります。許可されている場合は、col1とcol2の最初の数文字のみを使用できます。インデックス
ALTER TABLE'table_name 'ADD INDEX index_name(col1(4)、col2(3));
col1の最初の4文字とcol2の最初の3文字をインデックスとして使用することを示します
5、インデックスの使用戦略
1.インデックスはいつ使用する必要がありますか?
主キーは自動的に一意のインデックスを作成します。
WHEREまたはORDERBYステートメントでクエリ条件としてよく使用される列にはインデックスを付ける必要があります。
インデックス付けされるソートされた列として。
クエリ内の他のテーブルに関連付けられているフィールドをクエリし、外部キー関係のインデックスを作成します
同時実行性が高い条件下では、インデックスが組み合わされる傾向があります。
集計関数に使用される列にはインデックスを付けることができます。たとえば、max(column_1)またはcount(column_1)を使用する場合はcolumn_1にインデックスを付ける必要があります。
2.いつインデックスを使用すべきではありませんか?
頻繁に追加、削除、変更される列のインデックスを作成しないでください。
インデックスを付けずに重複する列が多数あります。
テーブルレコードが少なすぎる場合は、インデックスを作成しないでください。データベースに十分なテストデータがある場合にのみ、そのパフォーマンステスト結果に実際の参照値があります。テストデータベースに数百のデータレコードしかない場合、最初のクエリコマンドの実行後にすべてがメモリに読み込まれることがよくあります。これにより、インデックスが使用されているかどうかに関係なく、後続のクエリコマンドが非常に高速に実行されます。データベース内のレコードが1,000を超え、データの合計量がMySQLサーバーのメモリの合計量を超えた場合にのみ、データベースパフォーマンステストの結果は意味があります。
第六に、インデックスの失敗の状況
複合インデックスに値がNULLの列を含めることはできません。存在する場合、この列は複合インデックスに対して無効です。
SELECTステートメントでは、インデックスは1回しか使用できません。WHEREで使用する場合は、ORDER BYでは使用しないでください
。LIKE操作では、「%aaa%」はインデックスを使用しません。つまり、インデックスはインデックスを使用します。失敗しますが、「aaa%」はインデックスを使用できます。
インデックス付きの列で式または関数を使用すると、インデックスが無効になります。たとえば、次のようになります。select* from users where YEAR(adddate)<2007、操作は各行で実行され、インデックスが失敗し、全表スキャンが実行されます。したがって、次のように変更できます。select* from users where adddate <'2007-01-01'。他のワイルドカードも同じです。つまり、クエリ条件で正規表現を使用する場合、インデックスは、検索テンプレートの最初の文字がワイルドカードでない場合にのみ使用できます。
<symbol、> symbol 、!などのクエリ条件で不等式を使用します。=インデックスが無効になります。特に主キーインデックスに使用する場合は!=インデックスを無効にしません。主キーインデックスまたは整数型インデックスに<記号または>記号を使用した場合、インデックスは無効になりません。(クラスメートerwkjrfhjwkdbが思い出したように、<symbol、>記号と!を含めて等しくありません。レコード全体のわずかな割合を占める場合、無効にはなりません)。
クエリ条件でISNULLまたはISNOT NULLを使用すると、インデックスが無効になります。
一重引用符のない文字列では、インデックスが無効になります。より正確には、一貫性のないタイプは無効になります。たとえば、フィールドemailが文字列タイプの場合、WHERE email = 99999を使用すると失敗します。WHEREemail= '99999'に変更する必要があります。
ORを使用してクエリ条件の複数の条件を接続すると、インデックスが失敗します。ただし、ORリンクの各条件にインデックスが追加されていない場合は、2つのクエリに変更してから、UNIONALLで接続する必要があります。
ソートされたフィールドがインデックスを使用する場合、選択フィールドもインデックスフィールドである必要があります。そうでない場合、インデックスは無効になります。特に、ソートが主キーインデックスである場合、*を選択してもインデックスが無効になることはありません。
複数列の並べ替えを含めないようにしてください。必要な場合は、このキューの複合インデックスを作成するのが最善です。
7、インデックスの最適化
1.左端のプレフィックス
インデックスの左端のプレフィックスは、B + Treeの「左端のプレフィックスの原則」に関連しています。たとえば、結合インデックス<col1、col2、col3>が設定されている場合、インデックスは次の3つの状況で使用できます。col1 、<col1、col2>、<col1、col2、col3>、<col2、col3>、<col1、col3>、col2、col3などの他の列はインデックスを使用できません。
左端のプレフィックスの原則に従って、通常、ソート頻度が最も高い列を左端に配置します。
2.インデックスを使用したファジークエリの最適化
前述のように、ファジークエリにLIKEを使用する場合、「%aaa%」はインデックスを使用しません。つまり、インデックスは無効になります。この場合、最適化にはフルテキストインデックスのみを使用できます(上記を参照)。
3.検索条件の全文索引を作成してから、
SELECT * FROM tablename MATCH(index_colum) ANGAINST(‘word’);
4.短いインデックスを使用する
リストにインデックスを付けるには、可能であればプレフィックスの長さを指定する必要があります。たとえば、CHAR(255)列がある場合、複数値が最初の10文字または20文字内で一意である場合は、列全体にインデックスを付けないでください。インデックスを短くすると、クエリ速度が向上するだけでなく、ディスク領域とI / O操作も節約できます。