MySQLの高レベルのステートメント
高度なSQLステートメントに進む前に、2つのテーブルを作成します
use edg;
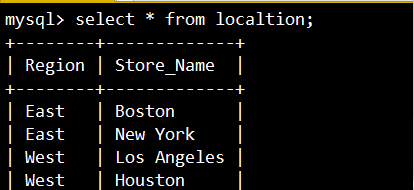
create table localtion (Region char(20),Store_Name char(20));
insert into localtion values('East','Boston');
insert into localtion values('East','New York');
insert into localtion values('West','Los Angeles');
insert into localtion values('West','Houston');
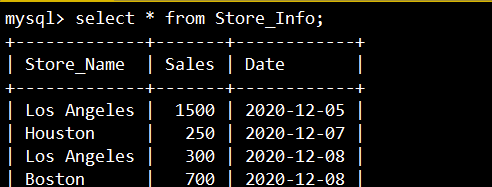
create table Store_Info (Store_Name char(20),Sales int(10),Date char(10));
insert into Store_Info values('Los Angeles','1500','2020-12-05');
insert into Store_Info values('Houston','250','2020-12-07');
insert into Store_Info values('Los Angeles','300','2020-12-08');
insert into Store_Info values('Boston','700','2020-12-08');
1. MySQL AdvancedStatementの概要
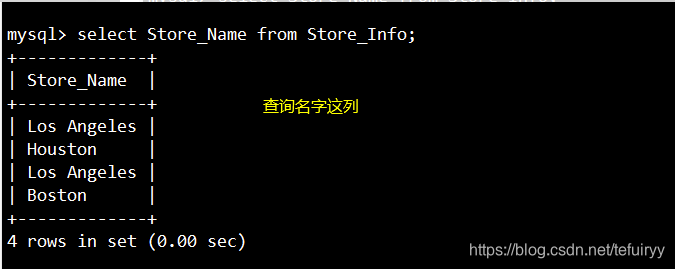
1. SELECT:テーブルの1つまたは複数のフィールドにすべてのデータを表示します
语法:SELECT "栏位" FROM "表名";
SELECT Store_Name FROM Store_Info;
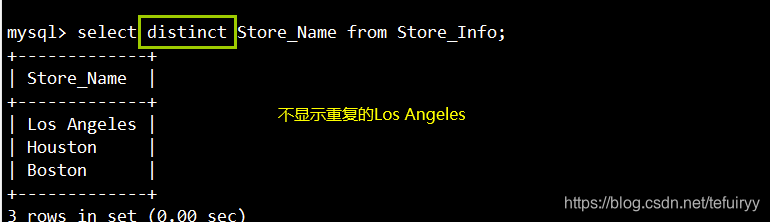
2. DISTINCT:重複データを表示しない
语法:SELECT DISTINCT "栏位" FROM "表名";
SELECT DISTINCT Store_Name FROM Store_Info;
3. WHERE:条件付きクエリ
语法:SELECT "栏位" FROM "表名" WHERE "条件";
SELECT Store_Name FROM Store_Info WHERE Sales > 1000;
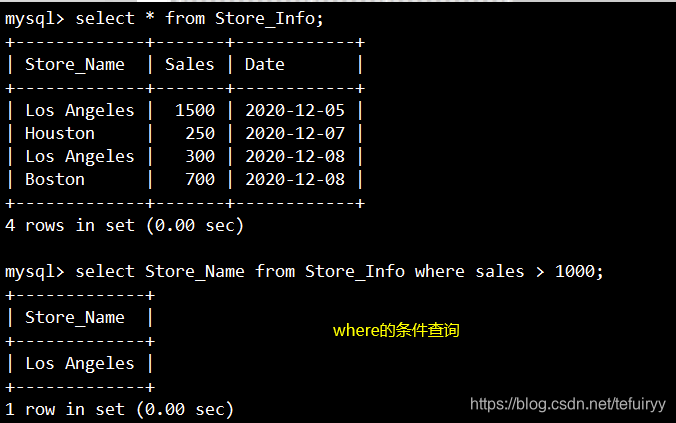
4. AND OR:and or
语法:SELECT "栏位" FROM "表名" WHERE "条件1" {[AND|OR] "条件2"}+ ;
SELECT Store_Name FROM Store_Info WHERE Sales > 1000 OR (Sales < 500 AND Sales > 200);
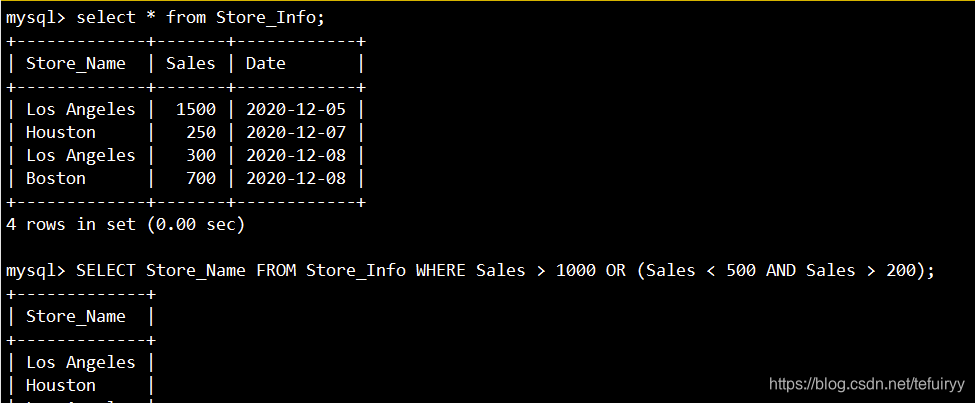
5. IN:既知の値のデータを表示します
语法:SELECT "栏位" FROM "表名" WHERE "栏位" IN ('值1', '值2', ...);
SELECT * FROM Store_Info WHERE Store_Name IN ('Los Angeles', 'Houston');
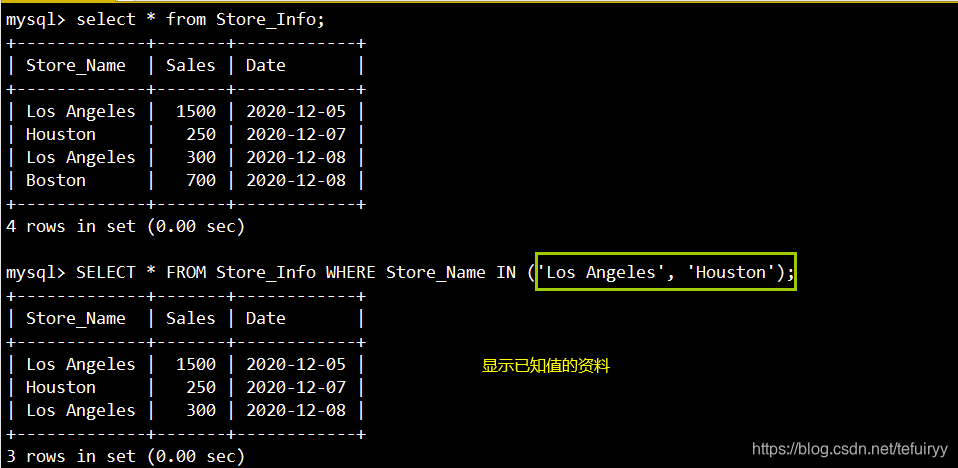
6. BETWEEN:2つの値の範囲内のデータを表示します
语法:SELECT "栏位" FROM "表名" WHERE "栏位" BETWEEN '值1' AND '值2';
SELECT * FROM Store_Info WHERE Sales BETWEEN '250' AND '700';
7.ワイルドカード:通常、ワイルドカードはLIKEと一緒に使用されます
% :百分号表示零个、一个或多个字符
_ :下划线表示单个字符
'A_Z':所有以 'A' 起头,另一个任何值的字符,且以 'Z' 为结尾的字符串。例如,'ABZ' 和 'A2Z' 都符合这一个模式,而 'AKKZ' 并不符合 (因为在 A 和 Z 之间有两个字符,而不是一个字符)。
'ABC%': 所有以 'ABC' 起头的字符串。例如,'ABCD' 和 'ABCABC' 都符合这个模式。
'%XYZ': 所有以 'XYZ' 结尾的字符串。例如,'WXYZ' 和 'ZZXYZ' 都符合这个模式。
'%AN%': 所有含有 'AN'这个模式的字符串。例如,'LOS ANGELES' 和 'SAN FRANCISCO' 都符合这个模式。
'_AN%':所有第二个字母为 'A' 和第三个字母为 'N' 的字符串。例如,'SAN FRANCISCO' 符合这个模式,而 'LOS ANGELES' 则不符合这个模式。
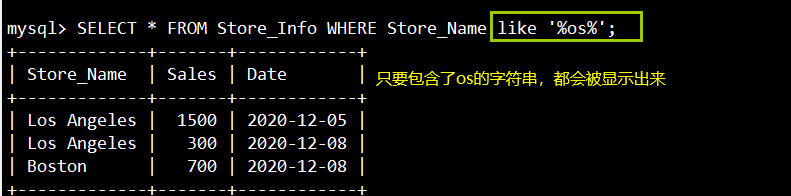
8.いいね:パターンを一致させて、必要な情報を見つけます
语法:SELECT "栏位" FROM "表名" WHERE "栏位" LIKE {模式};
SELECT * FROM Store_Info WHERE Store_Name like '%os%';
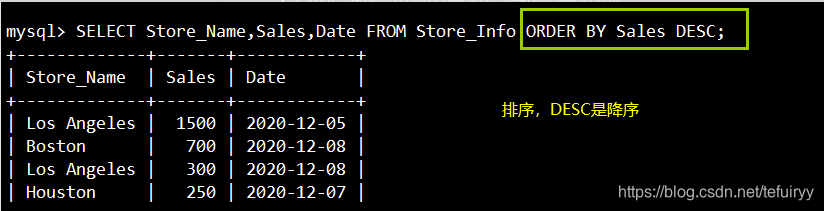
9. ORDER BY:キーワードで並べ替え
语法:SELECT "栏位" FROM "表名" [WHERE "条件"] ORDER BY "栏位" [ASC, DESC];
#ASC 是按照升序进行排序的,是默认的排序方式。
#DESC 是按降序方式进行排序。
SELECT Store_Name,Sales,Date FROM Store_Info ORDER BY Sales DESC;
10.関数
数学関数:
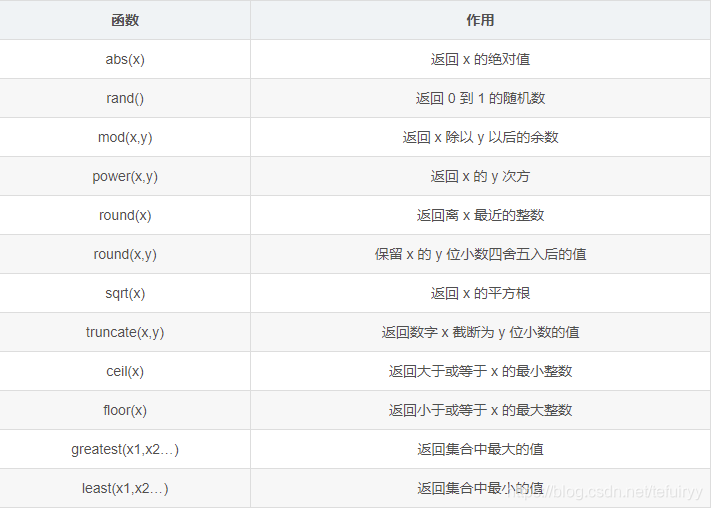
SELECT abs(-1), rand(), mod(5,3), power(2,3), round(1.89);
SELECT round(1.8937,3), truncate(1.235,2), ceil(5.2), floor(2.1), least(1.89,3,6.1,2.1);
11.集計関数
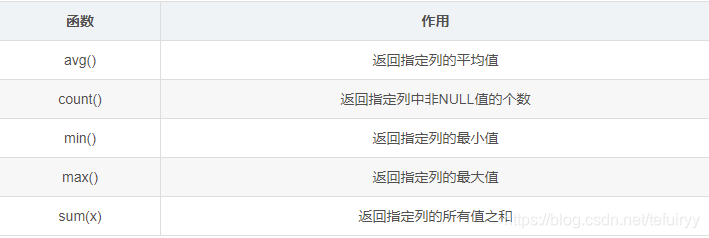
SELECT avg(Sales) FROM Store_Info;
SELECT count(Store_Name) FROM Store_Info;
SELECT count(DISTINCT Store_Name) FROM Store_Info;
SELECT max(Sales) FROM Store_Info;
SELECT min(Sales) FROM Store_Info;
SELECT sum(Sales) FROM Store_Info;
12.文字列関数
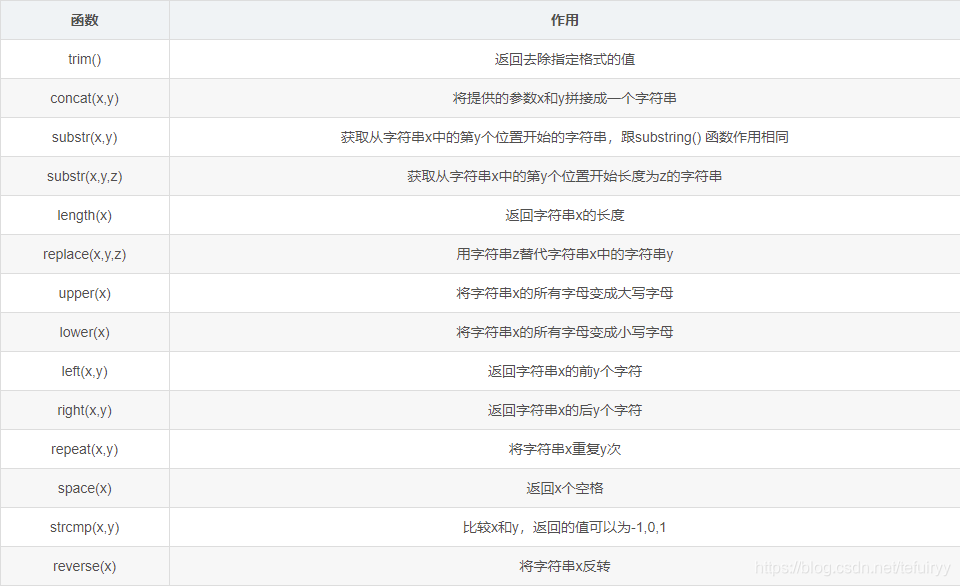
SELECT concat(Region, Store_Name) FROM localtion WHERE Store_Name = 'Boston';
#如sql_mode开启开启了PIPES_AS_CONCAT,"||"视为字符串的连接操作符而非或运算符,和字符串的拼接函数Concat相类似,这和Oracle数据库使用方法一样的
SELECT Region || ' ' || Store_Name FROM localtion WHERE Store_Name = 'Boston';
SELECT substr(Store_Name,3) FROM localtion WHERE Store_Name = 'Los Angeles';
SELECT substr(Store_Name,2,4) FROM localtion WHERE Store_Name = 'New York';
SELECT TRIM ([ [位置] [要移除的字符串] FROM ] 字符串);
#[位置]:的值可以为 LEADING (起头), TRAILING (结尾), BOTH (起头及结尾)。
#[要移除的字符串]:从字串的起头、结尾,或起头及结尾移除的字符串。缺省时为空格。
SELECT TRIM(LEADING 'Ne' FROM 'New York');
SELECT Region,length(Store_Name) FROM localtion;
SELECT REPLACE(Region,'ast','astern')FROM localtion;
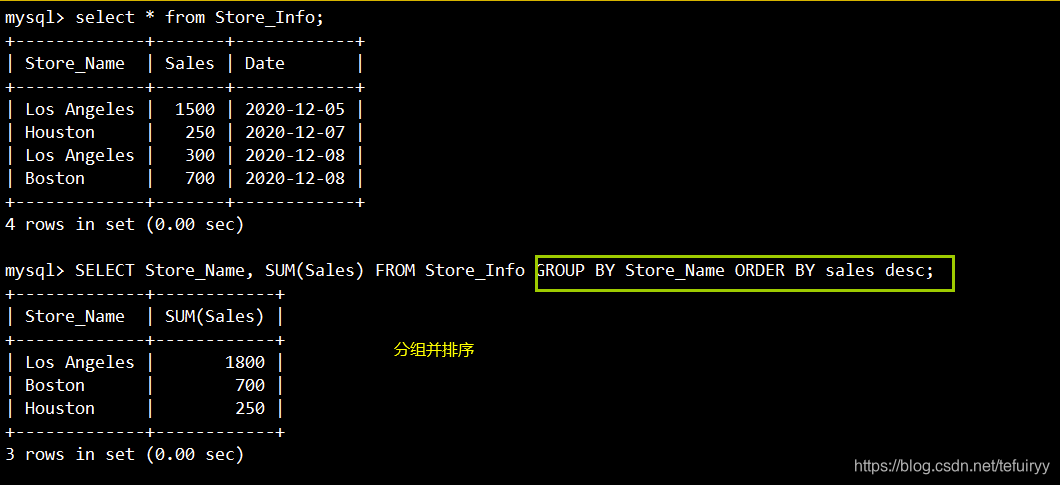
13. GROUP BY:GROUP BYの背後にある列のクエリ結果を集計してグループ化します。GROUPBYは通常、集計関数と組み合わせて使用され
ます。SELECTの後のすべての列で、集計関数を使用しない列は後に表示される必要があるという原則があります。GROUPBY。
语法:SELECT "栏位1", SUM("栏位2") FROM "表名" GROUP BY "栏位1";
SELECT Store_Name, SUM(Sales) FROM Store_Info GROUP BY Store_Name ORDER BY sales desc;
14. HAVING:GROUP BYステートメントによって返されるレコードテーブルをフィルタリングするために使用されます
。HAVINGステートメントは通常、GROUP BYステートメントと組み合わせて使用され、WHEREキーワードの不足を補うために集計関数と組み合わせて使用することはできません。関数列のみが選択されている場合、GROUPBY句は必要ありません。
语法:SELECT "栏位1", SUM("栏位2") FROM "表格名" GROUP BY "栏位1" HAVING (函数条件);
SELECT Store_Name, SUM(Sales) FROM Store_Info GROUP BY Store_Name HAVING SUM(Sales) > 1500;

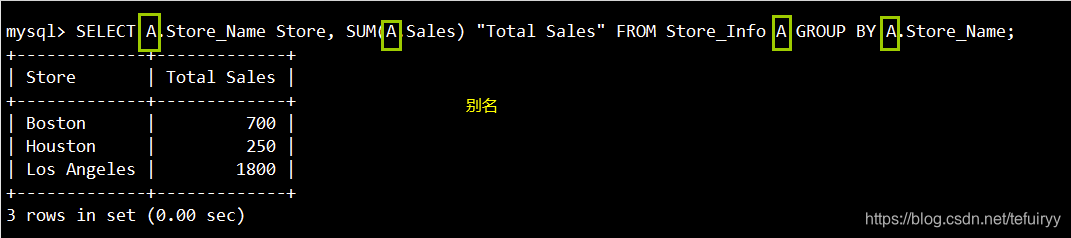
15.エイリアス:フィールドエイリアステーブルエイリアス
语法:SELECT "表格別名"."栏位1" [AS] "栏位別名" FROM "表格名" [AS] "表格別名";
SELECT A.Store_Name Store, SUM(A.Sales) "Total Sales" FROM Store_Info A GROUP BY A.Store_Name;
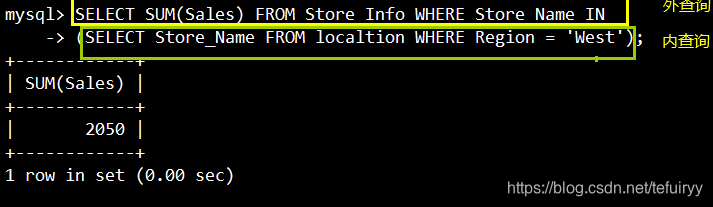
16.サブクエリ:テーブルを結合し、サブWHERE句またはHAVING句に別のSQLステートメントを挿入します
语法:SELECT "栏位1" FROM "表格1" WHERE "栏位2" [比较运算符] #外查询
(SELECT "栏位1" FROM "表格2" WHERE "条件"); #内查询
#可以是符号的运算符,例如:=、>、<、>=、<= ;也可以是文字的运算符,例如 LIKE、IN、BETWEEN
SELECT SUM(Sales) FROM Store_Info WHERE Store_Name IN
(SELECT Store_Name FROM localtion WHERE Region = 'West');
SELECT SUM(Sales) FROM Store_Info WHERE Store_Name IN ('Los Angeles','Houston');
SELECT SUM(A.Sales) FROM Store_Info A WHERE A.Store_Name IN
(SELECT Store_Name FROM localtion B WHERE B.Store_Name = A.Store_Name);

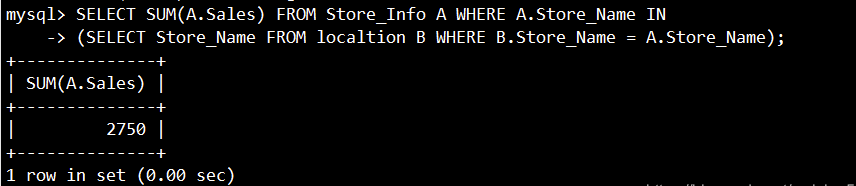
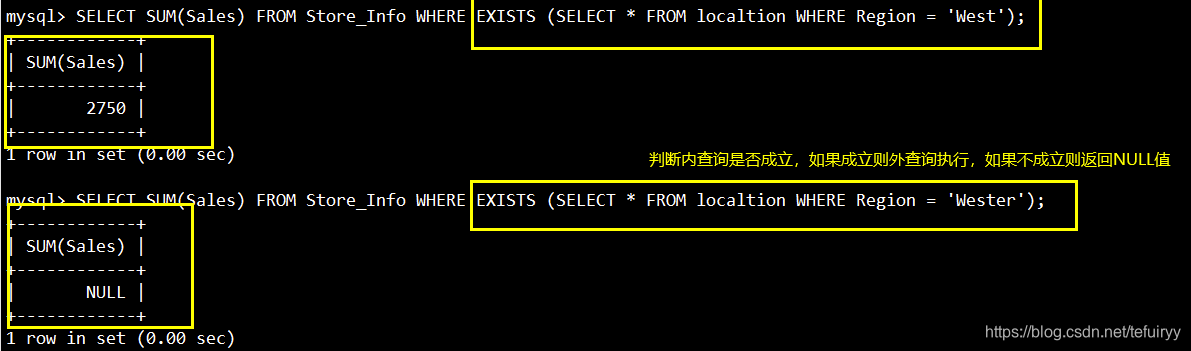
17. EXISTS:ブール値がtrueであるかどうかと同様に、内部クエリが結果を生成するかどうかをテストするために使用されます。生成される
場合、システムは外部クエリでSQLステートメントを実行します。そうでない場合、SQLステートメント全体は結果を生成しません。
语法:SELECT "栏位1" FROM "表格1" WHERE EXISTS (SELECT * FROM "表格2" WHERE "条件");
SELECT SUM(Sales) FROM Store_Info WHERE EXISTS (SELECT * FROM localtion WHERE Region = 'West');
2、接続クエリ
ロケーションテーブルは変更されません。Store_Infoテーブルを変更してください
UPDATE Store_Info SET store_name='Washington' WHERE sales=300;
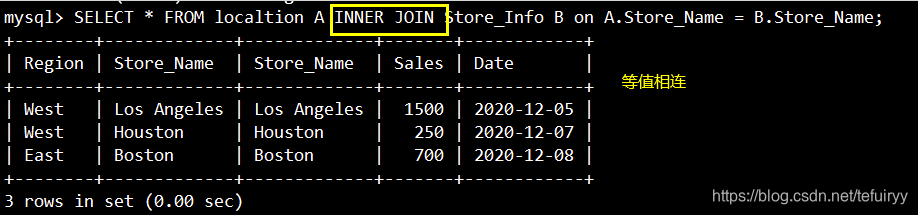
1、内部結合(等しい値の接続):2つのテーブルで等しい結合フィールドを持つ行のみを返します
SELECT * FROM localtion A INNER JOIN Store_Info B on A.Store_Name = B.Store_Name;
2、左結合(左結合):左テーブルのすべてのレコードを含む戻り値であり、右テーブルの結合フィールドはレコードと同じです
SELECT * FROM localtion A left JOIN Store_Info B on A.Store_Name = B.Store_Name;
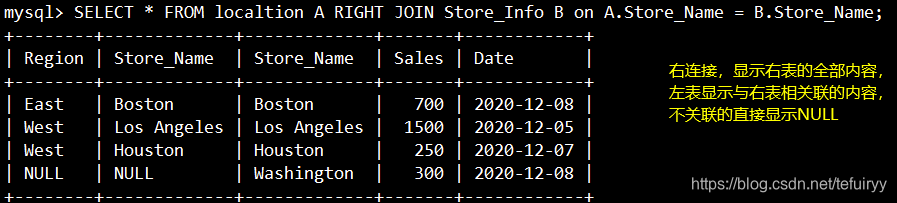
 3、右結合(右結合):右のテーブルのすべてのレコードを含み、左のテーブルの結合フィールドがレコードと等しい場合の戻り値
3、右結合(右結合):右のテーブルのすべてのレコードを含み、左のテーブルの結合フィールドがレコードと等しい場合の戻り値
SELECT * FROM localtion A RIGHT JOIN Store_Info B on A.Store_Name = B.Store_Name;
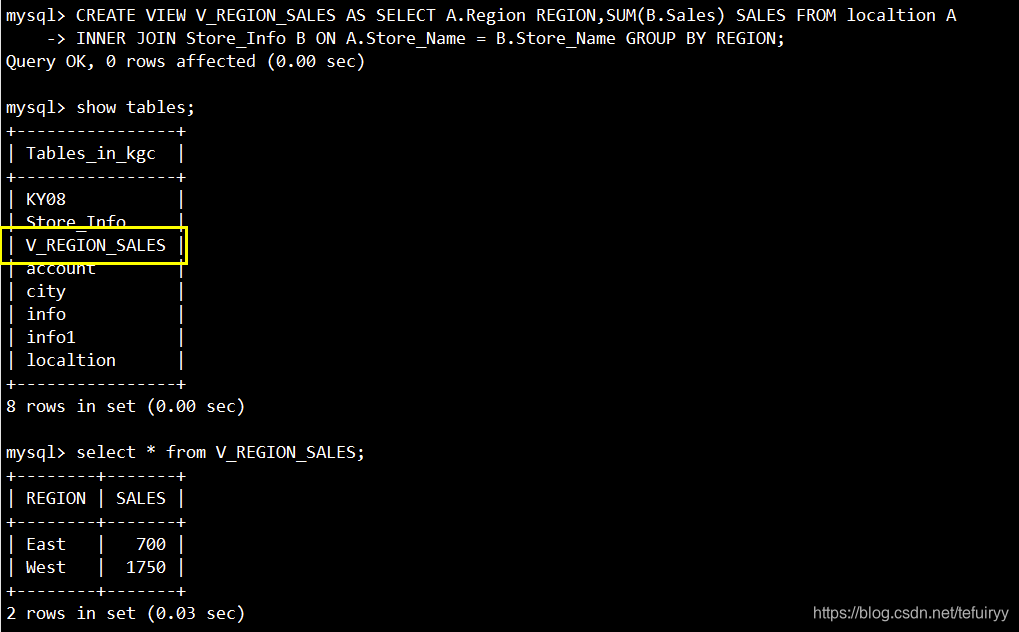
3、CREATEVIEWビュー
注:ビューとテーブルの違いは、テーブルには実際に保存されたデータがあり、ビューはテーブル上に構築された構造であり、実際にはデータを保存しないことです。
ユーザーが終了するか、データベースとの接続が切断されると、一時テーブルは自動的に消え、ビューは消えません。
ビューにはデータが含まれず、その定義のみが保存されます。その目的は通常、複雑なクエリを単純化することです。たとえば、複数のテーブルを接続してクエリを実行するだけでなく、統計的な並べ替えやその他の操作も実行する場合、SQLステートメントを作成するのは非常に面倒です。ビューで複数のテーブルを接続してから、このビューでクエリ操作を実行するだけです。テーブルのようにクエリを実行すると非常に便利です。
语法:CREATE VIEW "视图表名" AS "SELECT 语句";
CREATE VIEW V_REGION_SALES AS SELECT A.Region REGION,SUM(B.Sales) SALES FROM localtion A
INNER JOIN Store_Info B ON A.Store_Name = B.Store_Name GROUP BY REGION;
SELECT * FROM V_REGION_SALES;
DROP VIEW V_REGION_SALES;
第4に、MySQLの和集合、共通部分の値、非共通部分の値、ケース
1. 2つのSQLステートメントの結果を結合するUnion。2つのSQLステートメントによって生成されるフィールドは、同じデータ型である必要があります
(1)UNION:
UNION :生成结果的资料值将没有重复,且按照字段的顺序进行排序
语法:[SELECT 语句 1] UNION [SELECT 语句 2];
SELECT Store_Name FROM localtion UNION SELECT Store_Name FROM Store_Info;
(2)ユニオンオール
UNION ALL :将生成结果的资料值都列出来,无论有无重复
语法:[SELECT 语句 1] UNION ALL [SELECT 语句 2];
SELECT Store_Name FROM localtion UNION ALL SELECT Store_Name FROM Store_Info;
2.交差値:2つのSQLステートメントの結果の交差を取ります
SELECT A.Store_Name FROM localtion A INNER JOIN Store_Info B ON A.Store_Name = B.Store_Name;
SELECT A.Store_Name FROM localtion A INNER JOIN Store_Info B USING(Store_Name);
两表没用重复的行,并且确实有交集的时候用
SELECT A.Store_Name FROM
(SELECT Store_Name FROM localtion UNION ALL SELECT Store_Name FROM Store_Info) A
GROUP BY A.Store_Name HAVING COUNT(*) > 1;
取两个SQL语句结果的交集,且没有重复
SELECT A.Store_Name FROM (SELECT B.Store_Name FROM localtion B INNER JOIN Store_Info C ON B.Store_Name = C.Store_Name) A
GROUP BY A.Store_Name;
SELECT DISTINCT A.Store_Name FROM localtion A INNER JOIN Store_Info B USING(Store_Name);
SELECT DISTINCT Store_Name FROM localtion WHERE (Store_Name) IN (SELECT Store_Name FROM Store_Info);
SELECT DISTINCT A.Store_Name FROM localtion A
LEFT JOIN Store_Info B USING(Store_Name) WHERE B.Store_Name IS NOT NULL;
3.共通部分の値なし:最初のSQLステートメントの結果を表示し、2番目のSQLステートメントとの共通部分の結果はなく、重複もありません。
SELECT DISTINCT Store_Name FROM localtion WHERE (Store_Name) NOT IN (SELECT Store_Name FROM Store_Info);
SELECT DISTINCT A.Store_Name FROM localtion A
LEFT JOIN Store_Info B USING(Store_Name) WHERE B.Store_Name IS NULL;
4.ケース:SQLは、IF-THEN-ELSEなどのロジックのキーワードとして使用されます。
構文:
SELECT CASE ("栏位名")
WHEN "条件1" THEN "结果1"
WHEN "条件2" THEN "结果2"
...
[ELSE "结果N"]
END
FROM "表名";
# "条件" 可以是一个数值或是公式。 ELSE 子句则并不是必须的。
ファイブ、ソート
ソート前の準備:
CREATE TABLE Total_Sales (Name char(10),Sales int(5));
INSERT INTO Total_Sales VALUES ('zhangsan',10);
INSERT INTO Total_Sales VALUES ('lisi',15);
INSERT INTO Total_Sales VALUES ('wangwu',20);
INSERT INTO Total_Sales VALUES ('zhaoliu',40);
INSERT INTO Total_Sales VALUES ('sunqi',50);
INSERT INTO Total_Sales VALUES ('zhouba',20);
INSERT INTO Total_Sales VALUES ('wujiu',30);
1.ランキングテーブルの自己結合(自己結合)を計算し、結果を順番に一覧表示して、各行(行自体を含む)の前にある行数を計算します。
SELECT A1.Name, A1.Sales, COUNT(A2.Sales) Rank FROM Total_Sales A1, Total_Sales A2
WHERE A1.Sales < A2.Sales OR (A1.Sales=A2.Sales AND A1.Name = A2.Name)
GROUP BY A1.Name, A1.Sales ORDER BY A1.Sales DESC;
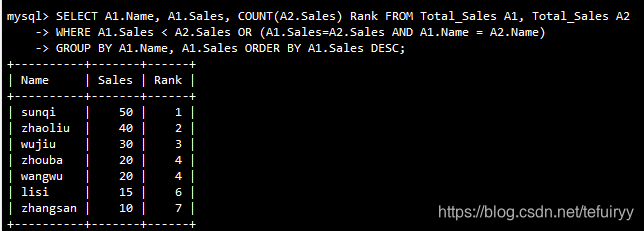
Salesフィールドの値がそれ自体の値よりも小さく、SalesフィールドとNameフィールドの数が同じ
2、中央値であることを数えます。
SELECT Sales Middle FROM (SELECT A1.Name,A1.Sales,COUNT(A2.Sales) Rank FROM Total_Sales A1,Total_Sales A2
WHERE A1.Sales < A2.Sales OR (A1.Sales=A2.Sales AND A1.Name <= A2.Name)
GROUP BY A1.Name, A1.Sales ORDER BY A1.Sales DESC) A3
WHERE A3.Rank = (SELECT (COUNT(*)+1) DIV 2 FROM Total_Sales);
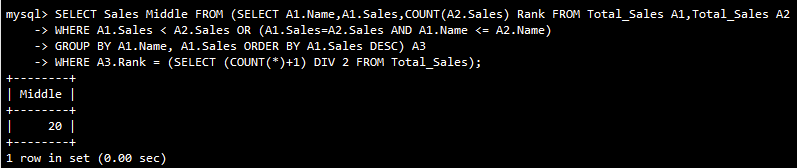
派生テーブルにはそれぞれ独自のエイリアスが必要です。3
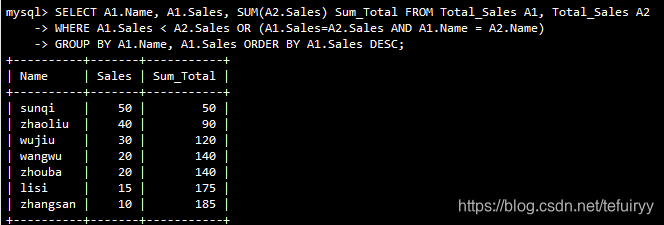
。累積合計テーブルの自己結合(自己結合)を計算し、結果をシーケンス処理して、各行(行自体を含む)の前の合計を計算します。
SELECT A1.Name, A1.Sales, SUM(A2.Sales) Sum_Total FROM Total_Sales A1, Total_Sales A2
WHERE A1.Sales < A2.Sales OR (A1.Sales=A2.Sales AND A1.Name = A2.Name)
GROUP BY A1.Name, A1.Sales ORDER BY A1.Sales DESC;
4.合計パーセンテージ
SELECT A1.Name, A1.Sales, A1.Sales/(SELECT SUM(Sales) FROM Total_Sales) Per_Total
FROM Total_Sales A1, Total_Sales A2
WHERE A1.Sales < A2.Sales OR (A1.Sales=A2.Sales AND A1.Name = A2.Name)
GROUP BY A1.Name, A1.Sales ORDER BY A1.Sales DESC;
#SELECT SUM(Sales) FROM Total_Sales 这一段子查询是用来算出总合
#总合算出后,我们就能够将每一行一一除以总合来求出每一行的总合百分比
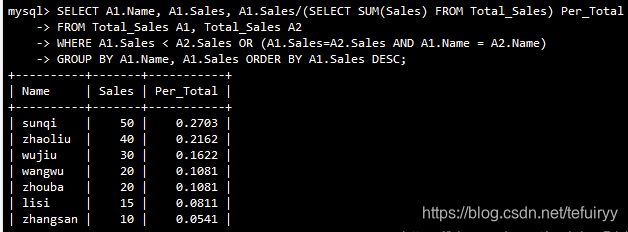
5.累積合計のパーセンテージ
SELECT A1.Name, A1.Sales, SUM(A2.Sales)/(SELECT SUM(Sales) FROM Total_Sales) Per_Total
FROM Total_Sales A1, Total_Sales A2
WHERE A1.Sales < A2.Sales OR (A1.Sales=A2.Sales and A1.Name = A2.Name)
GROUP BY A1.Name, A1.Sales ORDER BY A1.Sales DESC;
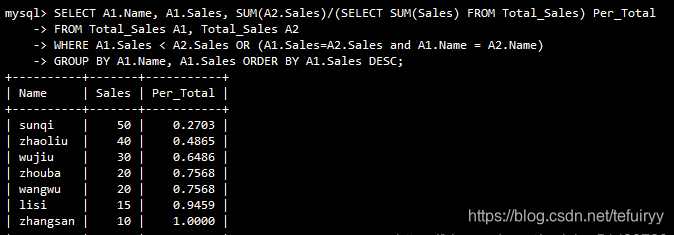
累積合計SUM(a2.Sales)を合計で除算して、各行の累積合計パーセンテージを求めます。
SELECT A1.Name, A1.Sales, TRUNCATE(ROUND(SUM(A2.Sales)/(SELECT SUM(Sales) FROM Total_Sales),4)*100,2) || '%' Per_Total
FROM Total_Sales A1, Total_Sales A2
WHERE A1.Sales < A2.Sales OR (A1.Sales=A2.Sales and A1.Name = A2.Name)
GROUP BY A1.Name, A1.Sales ORDER BY A1.Sales DESC;
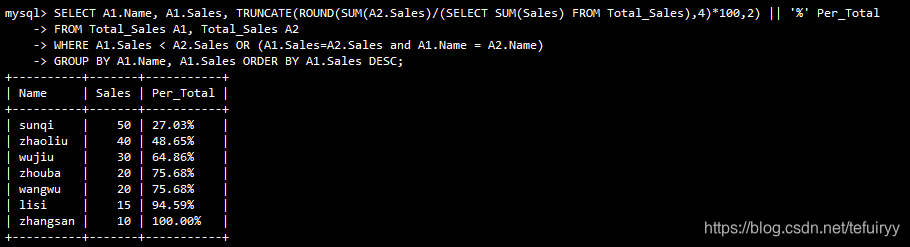
6、nullと値なしの違い
1.无值的长度为 0,不占用空间的;而 NULL 值的长度是 NULL,是占用空间的。
2.IS NULL 或者 IS NOT NULL,是用来判断字段是不是为 NULL 或者不是 NULL,不能查出是不是无值的。
3.无值的判断使用=''或者<>''来处理。<> 代表不等于。
4.在通过 count()指定字段统计有多少行数时,如果遇到 NULL 值会自动忽略掉,遇到无值会加入到记录中进行计算。
SELECT length(NULL), length(''), length('1');
SELECT * FROM city WHERE name IS NULL;
SELECT * FROM city WHERE name IS NOT NULL;
SELECT * FROM city WHERE name = '';
SELECT * FROM city WHERE name <> '';
SELECT COUNT(*) FROM city;
SELECT COUNT(name) FROM city;
7つの正規表現
匹配模式 描述 实例
^ 匹配文本的开始字符 ‘^bd’ 匹配以 bd 开头的字符串
$ 匹配文本的结束字符 ‘qn$’ 匹配以 qn 结尾的字符串
. 匹配任何单个字符 ‘s.t’ 匹配任何 s 和 t 之间有一个字符的字符串
* 匹配零个或多个在它前面的字符 ‘fo*t’ 匹配 t 前面有任意个 o
+ 匹配前面的字符 1 次或多次 ‘hom+’ 匹配以 ho 开头,后面至少一个m 的字符串
字符串 匹配包含指定的字符串 ‘clo’ 匹配含有 clo 的字符串
p1|p2 匹配 p1 或 p2 ‘bg|fg’ 匹配 bg 或者 fg
[...] 匹配字符集合中的任意一个字符 ‘[abc]’ 匹配 a 或者 b 或者 c
[^...] 匹配不在括号中的任何字符 ‘[^ab]’ 匹配不包含 a 或者 b 的字符串
{n} 匹配前面的字符串 n 次 ‘g{2}’ 匹配含有 2 个 g 的字符串
{n,m} 匹配前面的字符串至少 n 次,至多m 次 ‘f{1,3}’ 匹配 f 最少 1 次,最多 3 次
構文形式:
语法:SELECT "栏位" FROM "表名" WHERE "栏位" REGEXP {模式};
SELECT * FROM Store_Info WHERE Store_Name REGEXP 'os';
SELECT * FROM Store_Info WHERE Store_Name REGEXP '^[A-G]';
SELECT * FROM Store_Info WHERE Store_Name REGEXP 'Ho|Bo';
8.保管プロセス
1.ストアドプロシージャは、特定の機能を完了するためのSQLステートメントのセットです。
2.ストアドプロシージャを使用するプロセスでは、一般的なタスクまたは複雑なタスクがSQLステートメントを使用して事前に記述され、指定された名前で格納されます。このプロセスはコンパイルおよび最適化され、データベースサーバーに格納されます。ストアドプロシージャを使用する必要がある場合は、呼び出すだけです。ストアドプロシージャは、従来のSQLよりも高速で効率的に実行できます。
3.ストアドプロシージャの利点:
(1)一度実行すると、生成されたバイナリコードがバッファに常駐し、実行効率が向上します
(2)SQLステートメントと制御ステートメントのコレクション、高い柔軟性
(3)サーバー側に格納されます。クライアントが呼び出されたときのネットワーク負荷を軽減します
(4)繰り返し呼び出すことができ、クライアントの呼び出しに影響を与えることなくいつでも変更できます
(5)すべてのデータベース操作を完了でき、データベースの情報アクセス権限は
4.ストレージプロセスを作成します。
DELIMITER $$ #将语句的结束符号从分号;临时改为两个$$(可以是自定义)
CREATE PROCEDURE Proc() #创建存储过程,过程名为Proc,不带参数
-> BEGIN #过程体以关键字 BEGIN 开始
-> select * from Store_Info; #过程体语句
-> END $$ #过程体以关键字 END 结束
DELIMITER ; #将语句的结束符号恢复为分号
5.ストアドプロシージャを呼び出します:CALL Proc;
6。ストアドプロシージャを表示します
SHOW CREATE PROCEDURE [数据库.]存储过程名; #查看某个存储过程的具体信息
SHOW CREATE PROCEDURE Proc;
SHOW PROCEDURE STATUS [LIKE '%Proc%'] \G
7.ストアドプロシージャのパラメータ
IN 。入力パラメータ:呼び出し元がプロシージャに値を渡すことを示します(入力値はリテラルまたは変数にすることができます)
OUT出力パラメータ:プロセスが呼び出し元に値を渡すことを示します(複数の値を返すことができます)(pass値は変数のみにすることができます)
INOUT入力および出力パラメーター:呼び出し元がプロセスに値を渡すことを意味しますが、プロセスが呼び出し元に値を渡すことも意味します(値は変数のみ)
8。ストアード・プロシージャーの
内容を変更してストアード・プロシージャーを削除する方法は、元のストアード・プロシージャーを削除してから、同じ名前で新しいストアード・プロシージャーを作成することです。
DROP PROCEDURE IF EXISTS Proc;
9、ストアドプロシージャの制御ステートメント
create table t (id int(10));
insert into t values(10);
(1)条件文if-then-else-end if if
DELIMITER $$
CREATE PROCEDURE proc2(IN parameter int)
-> begin
-> declare var int;
-> set var=parameter*2;
-> if var>=10 then
-> update t set id=id+1;
-> else
-> update t set id=id-1;
-> end if;
-> end $$
DELIMITER ;
CALL Proc2(6);
(2)ループステートメントwhile····end while
DELIMITER $$
CREATE PROCEDURE proc3()
-> begin
-> declare var int(10);
-> set var=0;
-> while var<6 do
-> insert into t values(var);
-> set var=var+1;
-> end while;
-> end $$
DELIMITER ;
CALL Proc3;