zabプロトコルは、Zookeeper用に設計された分散コンセンサスプロトコルです。
1. ZAB契約とは何ですか?ZAB契約の概要
-
ZABプロトコルのフルネーム:Zookeeper Atomic Broadcast(Zookeeper Atomic Broadcast)。
-
Zookeeperは、分散アプリケーション向けの効率的で信頼性の高い分散調整サービスです。分散整合性の解決に関して、ZookeeperはPaxosを使用しませんでしたが、ZABプロトコルを採用しました。
-
ZABプロトコルの定義:ZABプロトコルは、分散調整サービスZookeeper用に特別に設計されたサポートプロトコルです
原子广播和崩溃恢复。以下では、これら2つのことに焦点を当てます。 -
このプロトコルに基づいて、Zookeeperはレプリカをクラスター内に保持するための
主备模式システムアーキテクチャを実装 します数据一致性。詳細を下図に示します。
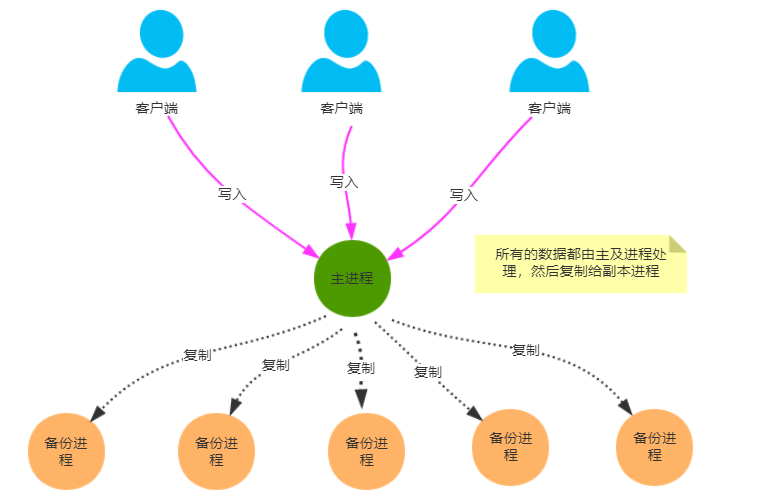
上の図は、Zookeeperがクラスター内のデータを処理する方法を示しています。
すべてのクライアント書き込みデータはメインプロセス(リーダーと呼ばれる)に書き込まれ、リーダーによってバックアッププロセス(フォロワーと呼ばれる)にコピーされます。データの整合性を確保するため。デザインの観点からは、Raftに似ています。
5.では、コピープロセスはどうですか?レプリケーションプロセスは2PCに似ており、ZABは送信を実行するためにAck情報を返すためにフォロワーの半分以上しか必要としないため、同期のブロックが大幅に削減されます。また、使いやすさも向上します。
簡単な紹介の後、消息广播 と に焦点を合わせ始めます 崩溃恢复。Zookeeper全体がこれら2つのモードを切り替えます。 つまり、リーダーサービスが正常に使用できる場合はメッセージブロードキャストモードになり、リーダーが使用できない場合はクラッシュリカバリモードになります。
2.ニュース放送
ZABプロトコルのメッセージブロードキャストプロセスは、2フェーズコミットプロセスと同様に 、アトミックブロードキャストプロトコルを使用します。
クライアントから送信されたすべての書き込みリクエストはリーダーによって受信されます。リーダーはリクエストをトランザクションプロポーザルにカプセル化し、すべてのフォルワーに送信します。その後、すべてのフォルワーのフィードバックに従って、フォルワーの半分以上が正常に応答した場合、コミット操作が実行されます(最初に送信)。自分で、すべてのフォロワーにコミットを送信します)。
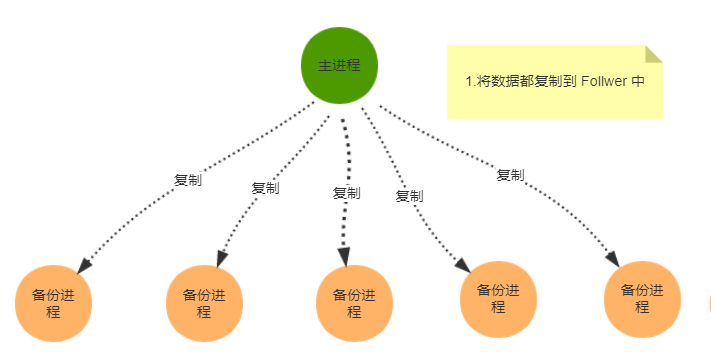
基本的に、ブロードキャストプロセス全体は3つのステップに分かれています。
1.すべてのデータをFollwerにコピーします
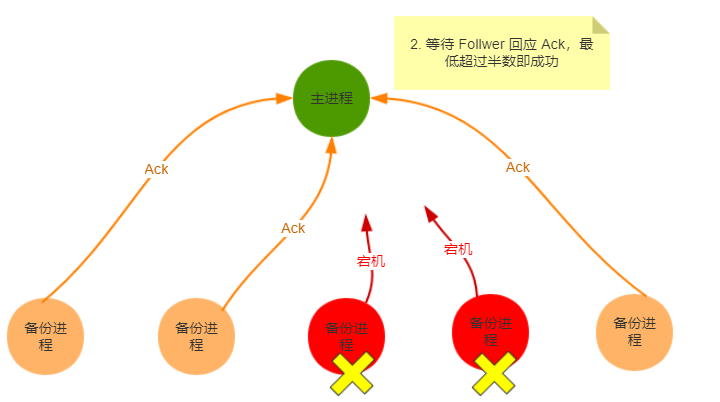
2. FollwerがAckに応答するのを待ちます。成功するには、最小数が半分以上です。
3.応答の半分以上が成功したら、commitを実行し、同時に自分自身を送信します
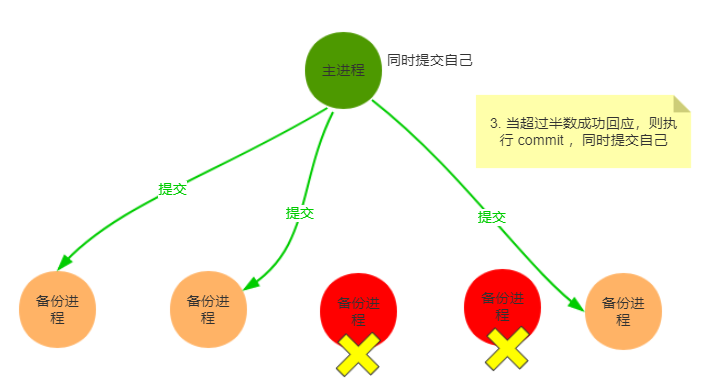
上記の3つの手順により、クラスター間のデータの整合性を維持できます。実際、LeaderとFollwerの間には、それらの間の結合を切り離し、同期を回避し、非同期の切り離しを実現するためのメッセージキューがあります。
いくつかの詳細があります:
-
リーダーはクライアント要求を受信した後、要求をトランザクションにカプセル化し、トランザクションID(ZXID)と呼ばれるグローバルに増加する一意のIDをトランザクションに割り当てます。ZABプロトコルはトランザクションの順序を保証する必要があるため、各トランザクションは、ZXIDに従ってソートおよび処理されます。
-
LeaderとFollwerの間には、それらの間の結合を切り離して同期のブロックを解除するためのメッセージキューもあります。
-
zookeeperクラスターでは、すべてのプロセスを順番に実行できるようにするために、リーダーサーバーのみが書き込み要求を受け入れることができます。フォロワーサーバーがクライアントの要求を受信した場合でも、処理のためにリーダーサーバーに転送されます。
-
実際、これは2PCの簡略版であり、シングルポイントの問題を解決することはできません。後で、ZABがシングルポイントの問題(つまり、リーダーのクラッシュの問題)をどのように解決するかについて説明します。
3.クラッシュリカバリ
メッセージブロードキャストプロセス中にリーダーがクラッシュした場合はどうすればよいですか?データの一貫性を保証できますか?リーダーが最初にローカルに送信し、次にコミット要求が送信されない場合はどうすればよいですか?
実際、リーダーがクラッシュすると、最初に述べたクラッシュリカバリモードになります(クラッシュとは、リーダーがフォルワーの半分以上との接触を失うことを意味します)。以下で詳しくお話ししましょう。
仮定1:すべてのフォロワーにデータをコピーした後にリーダーがクラッシュする場合、どうすればよいですか?
仮説2:Ackを受信して自分自身を送信し、同時にいくつかのコミットを送信した後、リーダーがクラッシュした場合はどうなりますか?
これらの問題に対応して、ZABは2つの原則を定義しました。
- ZABプロトコルは、Leaderでコミットされたトランザクションが最終的にすべてのサーバーによってコミットされることを保証します。
- ZABプロトコルは、リーダーによってのみ提案/複製されたがコミットされていないトランザクションが破棄されることを保証します。
したがって、ZABは、次の選択アルゴリズムを設計
しました。リーダーによって送信されたトランザクションが確実に送信され、スキップされたトランザクションは破棄されます。
この要件に応えて、リーダー選出アルゴリズムが、新しく選出されたリーダーサーバーがクラスター内のすべてのマシン番号のトランザクションを持つことを保証できる場合(つまり、ZXIDが最大)、新しく選出されたことが保証されます。リーダーは提出されたすべての提案を持っている必要があります。
また、これには利点があります。リーダーサーバーを保存して、トランザクションのコミットを確認し、このステップの作業を破棄できます。
このようにして、先ほど想定した2つの問題を解決できます。仮定1は、呼び出しによって送信されなかったデータを最終的に破棄し、仮定2は、最終的にすべてのサーバーのデータを同期します。このとき、どのように同期するのかという疑問が生じます。
4.データの同期
クラッシュが回復した後、正式な作業(クライアント要求の受信)の前に、リーダーサーバーは最初にトランザクションがFollwerの半分以上によって送信されたかどうか、つまりデータ同期が完了したかどうかを確認します。目的は、データの一貫性を保つことです。
すべてのFollwerサーバーが正常に同期されると、Leaderはこれらのサーバーを使用可能なサーバーのリストに追加します。
実際、リーダーサーバーはトランザクションの処理または破棄をZXIDに依存していますが、このZXIDはどのように生成されますか?
回答:ZABプロトコルのトランザクション番号のZXID設計では、ZXIDは64ビットの数値であり、そのうちの下位32ビットは単純なインクリメントカウンターと見なすことができます。クライアントのトランザクション要求ごとに、リーダーは生成します。新しいトランザクション。カウンターでの提案と+1操作。
上位32ビットは、リーダーサーバーから取得したローカルログ内の最大のトランザクションプロポーザルのZXIDを表し、対応するエポック値がZXIDから解析され、この値が1ずつ加算されます。
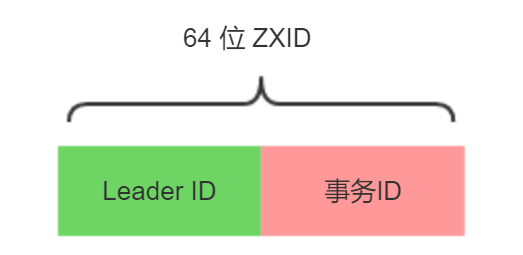
上位32ビットは各世代のリーダーの一意性を表し、下位32ビットは各世代のリーダーのトランザクションの一意性を表します。同時に、Follwerが上位32ビットを介して異なるリーダーを識別できるようにすることもできます。データ復旧プロセスを簡素化しました。
この戦略に基づいて:フォロワーがリーダーにリンクすると、リーダーサーバーは自身のサーバーで最後に送信されたZXIDをフォロワーのZXIDと比較し、比較の結果はロールバックされるか、リーダーと同期されます。
5.まとめ
要約する時が来ました。
以前に見たZABプロトコルとRaftプロトコルは実際には似ています。たとえば、一貫性を確保するためのリーダーがあります(Paxosは一貫性を確保するためにリーダーメカニズムを使用しません)。次に、サービスが利用可能であることを確認するメカニズムがあります(実際、PaxosとRaftの両方がこれを行います)。
ZABを使用すると、Zookeeperクラスター全体でメッセージブロードキャストとクラッシュリカバリの2つのモードを切り替えることができます。メッセージブロードキャストは2PCの簡易バージョンと言えます。クラッシュリカバリによって2PCのシングルポイントの問題を解決し、同期ブロックの問題を解決します。キューを介した2PCの。
クラッシュリカバリ後のデータの正確性は、トランザクションのZXIDの一意性に基づいて保証されるデータ同期によってサポートされます。+ 1操作により、トランザクションの順序を区別できます。
参照:
Zookeeperのソースコード。
「PaxosからZookeeperへ-分散整合性の原則と実践」