バケットソートの活用
バケットは、ソート、またはいわゆるビンソート、あるソートアルゴリズムバケットの限られた数に数字を分割することによって動作します。各バケットを個別に並べ替える
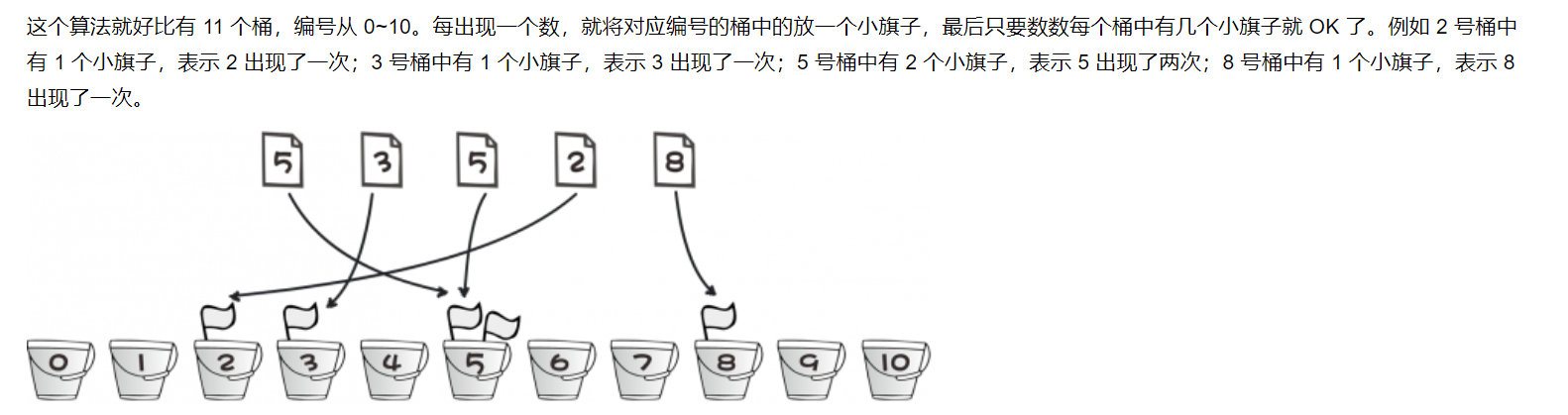
例:
文字列sを指定します。次のアルゴリズムに従って、文字列を再構築してください。
sから最小の文字を選択し、結果文字列の最後に接続します。
sの残りの文字から最小の文字を選択すると、その文字は最後に追加された文字よりも大きくなり、結果の文字列に追加されます。
から文字を選択できなくなるまで、手順2を繰り返します。
sから最大の文字を選択し、結果文字列の最後に接続します。
sの残りの文字から最大の文字を選択すると、その文字は最後に追加された文字よりも小さくなり、結果の文字列に追加されます。
から文字を選択できなくなるまで、手順5を繰り返します。
sのすべての文字が選択されるまで、手順1〜6を繰り返します。
どのステップでも、最小文字または最大文字が複数ある場合は、それらのいずれかを選択して、結果の文字列に追加できます。sの文字を並べ替えた後、結果の文字列を返してください。
例1:
入力:s = "aaaabbbbcccc"
出力: "abccbaabccba"
説明:最初のラウンドのステップ1、2、および3の後、結果文字列はresult = "abc"
です。最初のラウンドのステップ4、5、および6の後、結果文字列result = "abccba"の
最初のラウンドが終了し、s = "aabbcc"になりました。ステップ
1、2、および3の2回目のラウンドの後、ステップ1に戻り、結果文字列はresult = "abccbaabc"になります。
ステップの2番目のラウンド4、5、および6の後、結果の文字列はresult = "abccbaabccba"です。
例2:入力:s = "rat"
出力: "art"
説明:上記のアルゴリズムが並べ替えられた後、単語 "rat"は "art"になります。
例3:入力:s = "leetcode"
出力: "cdelotee"
例4:入力:s = "ggggggg"
出力: "ggggggg"
例5:入力:s = "spo"
出力: "ops"促す:
1 <= s.length <= 500
sには、小文字の英字のみが含まれます。
私のコード
class Solution
{
public:
string sortString(string s)
{
map<char, int> hash;
string ans = "";
for (int i = 0; i < s.size(); i++)
{
hash[s[i]]++;
}
int cnt = hash.size();
while (cnt)
{
// int n = hash.size();
// for(int j=0;j<n;j++)
for (auto it = hash.begin(); it != hash.end(); it++)
{
if (it->second)
{
ans += it->first;
it->second--;
if (it->second == 0)
cnt--;
}
}
// else
for (auto it = hash.rbegin(); it != hash.rend(); it++)
{
if (it->second)
{
ans += it->first;
it->second--;
if (it->second == 0)
cnt--;
}
}
}
return ans;
}
};
上記のコードは正しいです。正しいので、時間とスペースを改善および最適化し続けるために、最適化する方法を検討する必要があります。
- 地図はスペースの無駄です。結局、それは多くのスペースを占有しますが、実際には、地図を使用する必要はありません。配列を使用する代わりに(結局、26文字あります)これはスペースの優れた最適化です; ==>この方法はバケットソートです;(バケットソートは最初に学習されましたが、ほとんど使用されておらず、いつかについてはほとんど考えられていませんでした質問をしていますが、最近やりました。これは質問によく出てくるので、記録してください)
次に、次のコードを見てください
class Solution {
public:
//题目描述的复杂,其实就是不停地按字典序升序追加,降序追加,每次加一个
string sortString(string s) {
vector<int>tmp(26);
for(int i=0;i<s.size();i++)
tmp[s[i]-'a']++;
string ret;
while(ret.size()<s.size())
{
for(int i=0;i<26;i++)
if(tmp[i])
ret+=i+'a',tmp[i]--;
for(int i=25;i>=0;i--)
if(tmp[i])
ret+=i+'a',tmp[i]--;
}
return ret;
}
};
下の写真をご覧ください。時間とスペースが削減されています。

さらに、ハッシュテーブルの概念を以下に示します。
キーがkの場合、その値はf(k)の保存場所に保存されます。その結果、チェックされたレコードを比較せずに直接取得できます。この対応関係を呼び出しFハッシュ関数を、この考え方に基づいて構築されたテーブルは、ハッシュテーブルです。
(私は個人的に常にハッシュテーブルとバケットソートのアイデアを混同しているので、それを記録してください)
総括する
-
バケットソートを使用して、比較的均一な値を持つ要素のグループを格納できます(文字と数字)
-
ただし、値が0から始まるのではなく均一である場合は、ハッシュテーブルとバケットソートを使用できます。
-
比如一群数:1020,1023,1021,1022,1024........ 那么大可以令f(x)=1050-x;等等
結び目
-
バケットソートを使用して、比較的均一な値を持つ要素のグループを格納できます(文字と数字)
-
ただし、値が0から始まるのではなく均一である場合は、ハッシュテーブルとバケットソートを使用できます。
-
比如一群数:1020,1023,1021,1022,1024........ 那么大可以令f(x)=1050-x;等等 -
値が均一でない場合は、マップストレージを使用してください。