Tensorflow2.0トレーニングとFashion-Mnistデータセットのコンパイルの主な手順
- tf.keras.datasets importfashion_mnistデータセット
- tf.keras.Sequential()ビルドモデル
- model.compile()モデルのコンパイル
- model.fitモデルトレーニング、履歴を取得
- 履歴曲線グラフを描く
- model.evaluate()テストセットでモデルをテストします
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
import sklearn
import pandas as pd
import os
import sys
import time
import tensorflow as tf
from tensorflow import keras
print(sys.version_info)
for module in tf, mpl, np, pd, sklearn, tf, keras:
print(module.__name__, module.__version__)
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = '1'
config = tf.compat.v1.ConfigProto()
config.gpu_options.allow_growth = True
sess = tf.compat.v1.Session(config=config)
fashion_mnist = keras.datasets.fashion_mnist
(x_train_all,y_train_all),(x_test_all,y_test_all) = fashion_mnist.load_data()
x_valid , x_train = x_train_all[:5000],x_train_all[5000:]
y_valid , y_train = y_train_all[:5000],y_train_all[5000:]
x_test , y_test = x_test_all,y_test_all
print(x_train.shape,y_train.shape)
print(x_valid.shape,y_valid.shape)
print(x_test.shape,y_test.shape)
def show_single_image(img_arr):
plt.imshow(img_arr,cmap='binary')
plt.show()
show_single_image(x_train[0])
model = tf.keras.Sequential([
keras.layers.Flatten(input_shape=[28,28]),
keras.layers.Dense(300,activation='relu'),
keras.layers.Dense(100,activation='relu'),
keras.layers.Dense(10, activation='softmax')
])
model.compile(loss='sparse_categorical_crossentropy',
optimizer='sgd',
metrics=['accuracy'])
model.layers
model.summary()
history = model.fit(x_train,y_train,
epochs=10,
validation_data=(x_valid,y_valid))
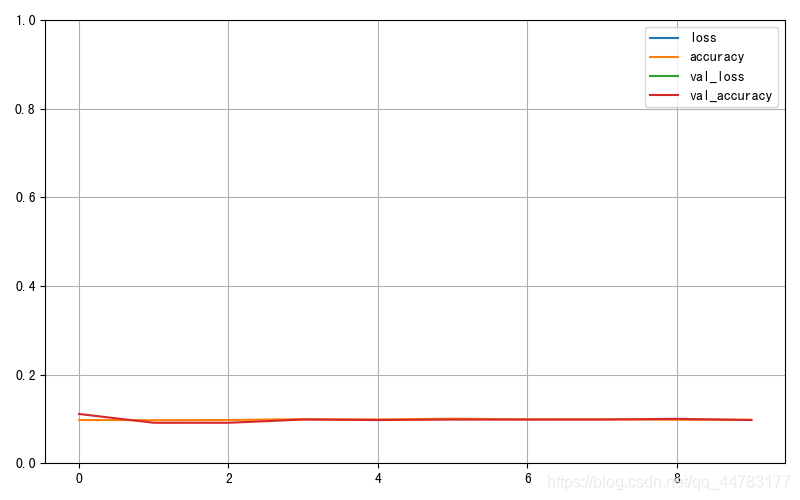
def plot_learning_curves(history):
pd.DataFrame(history.history).plot(figsize=(8,5))
plt.grid(True)
plt.gca().set_ylim(0,1)
plt.show()
plot_learning_curves(history)
model.evaluate(x_test_scaled,y_test)
- 最終的な分類精度の画像は次のとおりです。
- 分類精度が非常に低く、効果が非常に悪いことがわかります。それを改善する方法については、次の記事で説明します。