機械学習に基づくテキスト分類
機械学習モデル
機械学習は、経験を通じて自動的に改善できるコンピューターアルゴリズムの研究です。機械学習は、履歴データを使用して、経験を要約する人間のプロセスに対応するモデルをトレーニングします。機械学習は、モデルを使用して新しいデータを予測し、要約されたルールを使用して新しい問題を予測する人間のプロセスに対応します。
機械学習には多くの分野があります。学習者は、最初に機械学習アルゴリズムの分類を習得してから、機械学習アルゴリズムの1つを学習する必要があります。機械学習アルゴリズムの分岐や詳細が多すぎるため、最初の詳細に魅了された場合、全体的な状況を知ることは困難です。
機械学習の初心者の場合は、次のことを知っておく必要があります。
- 機械学習は特定の問題を解決できますが、機械学習が全能であるとは期待できません。
- 特定の問題に必要なものに応じて、多くの種類の機械学習アルゴリズムがあり、選択します。
- 各機械学習アルゴリズムには特定の設定があり、特定の問題の特定の分析が必要です。
テキスト表現方法Part1
機械学習アルゴリズムのトレーニングプロセスで、与えられたNNを想定します。N個のサンプル、各サンプルにはMMがありますN×MN×Mを形成するM個の特徴N××Mサンプル行列を作成し、アルゴリズムのトレーニングと予測を完了します。同様に、コンピュータービジョンでは、画像のピクセルは特徴と見なすことができ、各画像は高さ×幅×3の特徴マップと見なされ、3次元行列が計算のためにコンピューターに入力されます。
しかし、自然言語の分野では、上記の方法は実行できません。テキストは可変長です。コンピュータが操作できる数またはベクトルとしてテキストを表現する方法は、一般に単語埋め込み方法と呼ばれます。単語の埋め込みは、可変長のテキストを固定長のスペースに変換します。これは、テキスト分類の最初のステップです。
ワンホット
ここでのワンホットは、データマイニングタスクの操作と一致しています。つまり、各単語は離散ベクトルで表されます。具体的には、各単語/単語をインデックスにエンコードし、インデックスに従って値を割り当てます。
ワンホット表現方法の例は次のとおりです。
句子1:我 爱 北 京 天 安 门
句子2:我 喜 欢 上 海
まず、すべての文の単語にインデックスを付けます。つまり、各単語の番号を決定します。
{
'我': 1, '爱': 2, '北': 3, '京': 4, '天': 5,
'安': 6, '门': 7, '喜': 8, '欢': 9, '上': 10, '海': 11
}
ここには合計11の単語が含まれているため、各単語を11次元のスパースベクトルに変換できます。
我:[1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
爱:[0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
...
海:[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1]
言葉の袋
Bag of Words(Bag of Words)は、カウントベクトルとも呼ばれ、各ドキュメントの単語/単語は出現回数で表すことができます。
各単語の出現回数を直接カウントし、値を割り当てます。
句子1:我 爱 北 京 天 安 门
转换为 [1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0]
句子2:我 喜 欢 上 海
转换为 [1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1]
CountVectorizerをsklearnで直接使用して、次の手順を実行できます。
from sklearn.feature_extraction.text import CountVectorizer
corpus = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?',
]
vectorizer = CountVectorizer()
vectorizer.fit_transform(corpus).toarray()
Nグラム
N-gramは、隣接する単語を組み合わせて新しい単語を形成してカウントすることを除いて、CountVectorsに似ています。
Nの値が2の場合、文1と文2は次のようになります。
句子1:我爱 爱北 北京 京天 天安 安门
句子2:我喜 喜欢 欢上 上海
TF-IDF
TF-IDFスコアは2つの部分で構成されます。最初の部分は用語頻度(用語頻度)であり、2番目の部分は逆文書頻度(逆文書頻度)です。その中で、コーパス内のドキュメントの総数を単語を含むドキュメントの数で割って計算し、対数を取ることは、ドキュメントの逆頻度です。
TF(t)= 该词语在当前文档出现的次数 / 当前文档中词语的总数
IDF(t)= log_e(文档总数 / 出现该词语的文档总数)
機械学習に基づくテキスト分類
次に、さまざまなテキスト表現アルゴリズムの精度を比較し、検証セットをローカルで構築してF1スコアを計算します。
カウントベクトル+ RidgeClassifier
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.linear_model import RidgeClassifier
from sklearn.metrics import f1_score
train_df = pd.read_csv('train_set.csv', sep='\t', nrows=15000)
vectorizer = CountVectorizer(max_features=3000)
train_test = vectorizer.fit_transform(train_df['text'])
clf = RidgeClassifier()
clf.fit(train_test[:10000], train_df['label'].values[:10000])
val_pred = clf.predict(train_test[10000:])
print(f1_score(train_df['label'].values[10000:], val_pred, average='macro'))

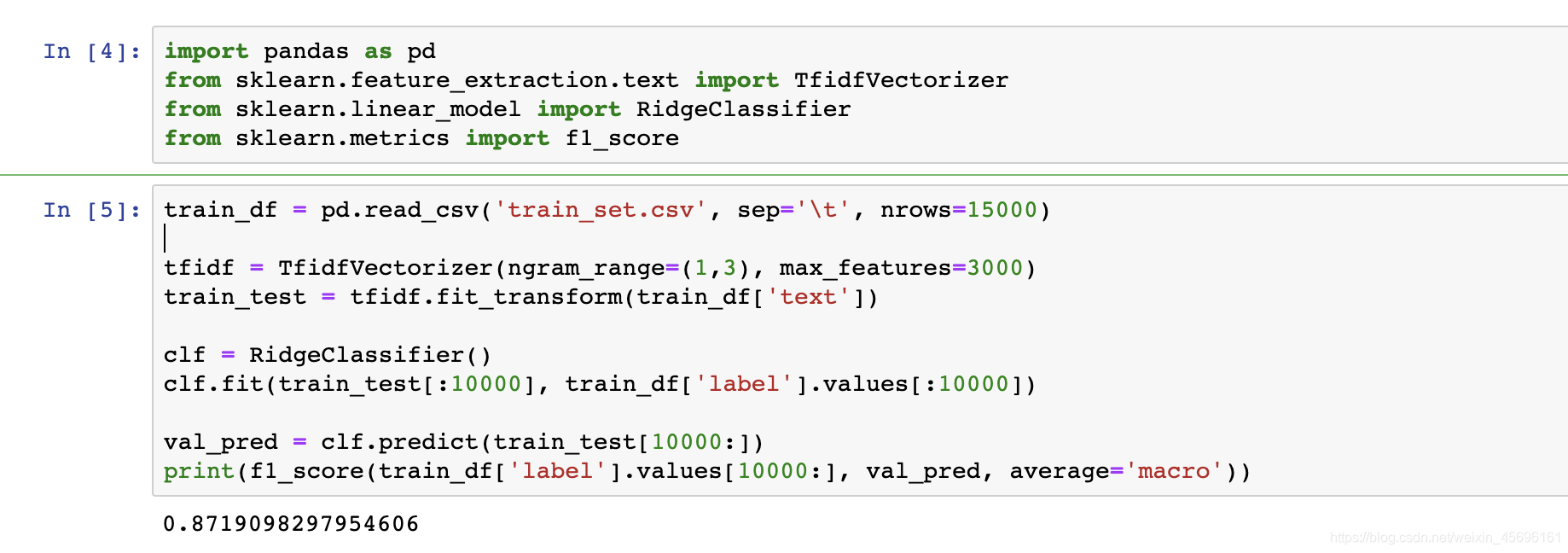
TF-IDF + RidgeClassifier
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import RidgeClassifier
from sklearn.metrics import f1_score
train_df = pd.read_csv('train_set.csv', sep='\t', nrows=15000)
tfidf = TfidfVectorizer(ngram_range=(1,3), max_features=3000)
train_test = tfidf.fit_transform(train_df['text'])
clf = RidgeClassifier()
clf.fit(train_test[:10000], train_df['label'].values[:10000])
val_pred = clf.predict(train_test[10000:])
print(f1_score(train_df['label'].values[10000:], val_pred, average='macro'))