1.機械/システム関連
1.名前テーブル
8ビット(ビット、ビット)= 2バイト(バイト)= 1ワード(WORD)[バスが言う「ワード」はシステムによって異なります]
1.ビット(ビット)
ビットは、コンピューターストレージの最小単位であり、bと略され、ビット(ビット)とも呼ばれます。コンピューターは、バイナリで0と1を使用してデータを表し、0または1はビットを表します。ビットも2進数のビットです。これは、情報量の測定単位であり、情報量の最小単位です
。2。バイト
バイト(英語バイト)は、コンピューターがストレージを測定するために使用する測定単位です。容量。バイトは8に等しいが、コンピュータープログラミング言語のバイト数、および言語文字のタイプを示すデータでも、最近のコンピューターでは、バイトは8に等しい
。3、ワード
ワードは自然な用語のコンピューターであるのデータの単位特定のコンピューターでは、ワードはトランザクションを一度に処理するために使用される固定長のビットグループです。最近のコンピューターでは、ワードは2バイトに相当します。
さらに、ダブルワードDWORD、4ワードQWORDがあります
2.アドレス指定とワード長
1.マシンワード長とは、CPUが一度にデータを処理できるビット数を指し、通常はCPUのレジスタ数に関連します。
2.命令ワードの長さ、コンピューター命令ワードの数。命令ワードの長さは、スレーブオペコードの長さ、オペランドアドレスの長さ、およびオペランドアドレスの数によって異なります。異なる命令の語長は異なります。
3.ストレージワード長は、バイナリコードの文字列(ストレージワード)を格納するストレージユニットです。このバイナリコードの文字列のビット数は、ストレージワード長と呼ばれます。
4.データワード長:コンピュータデータストレージが占めるビット数。
通常、初期のコンピューター:ストレージワード長=命令ワード長=データワード長。したがって、一度に1つの命令または1つのデータをフェッチできます。コンピュータアプリケーションの範囲が継続的に拡大すると、3つは異なる場合がありますが、バイトの整数倍である必要があります。
CPUは、処理する情報のワード長に応じて、8ビットマイクロプロセッサ、16ビットマイクロプロセッサ、32ビットマイクロプロセッサ、64ビットマイクロプロセッサなどに分けることができます。
CPUが検出できるアドレスの最大範囲は、アドレス指定機能と呼ばれます。CPUのアドレス指定機能はバイト単位です。たとえば
、32ビットアドレス指定CPUは、アドレスの2の32乗(4G)をアドレス指定できます。これが32ビットである理由CPUが最大4Gメモリと一致できる理由であり、CPUの量が見つかりません。
--in原理は、32ビットCPUは、64ビットシステム(コンピュータは非常に少数の32ビットCPUを持っている)と一緒にインストールすることができない。でサポートされているメモリ
によれば、オペレーティングシステム
32ビットオペレーティングシステムは、第32のパワーに2 、4GBのメモリです。
64ビットオペレーティングシステムの理論上のアドレス空間は2〜64乗ビットであり、変換単位は2147483648GBです。
3.エンコード方法(文字が文字化けする理由)
ASCIIコード:英語の文字(大文字と小文字は区別されません)は1バイトのスペースを占有します。コンピュータのデジタル単位としての2進数のシーケンスは、通常8ビットの2進数です。10進数に変換すると、最小値は-128、最大値は127です。たとえば、ASCIIコードはバイトです。
UTF-8エンコーディング:1つの英語文字は1バイトに相当し、1つの中国語(従来の文字を含む)は3バイトに相当します。中国語の句読点は3バイトを占め、英語の句読点は1バイトを占めます
。Unicodeエンコーディング:1つの英語は2バイトに等しく、1つの中国語(従来の句読点を含む)は2バイトに相当します。中国語の句読点は2バイトを占め、英語の句読点は2バイトを占めます
エンコーディングを理解するための鍵は、文字の概念とバイトの概念を正確に理解することです。これらの2つの概念は混同しやすいので、区別してみましょう。
概念の説明の例、
人々が使用する記号、および抽象的な意味での記号です。'1'、 'medium'、 'a'、 '$'、 'JPY' ......
バイトコンピュータにデータを格納する単位である8ビットの2進数は、非常に特殊な格納スペースです。0x01、0x45、0xFA ..
単語
コンピュータでは、全体として処理または計算される一連の数値は、コンピュータ単語、または略して単語と呼ばれます。ワードは通常、いくつかのバイトに分割されます(各バイトは通常8ビットです)。メモリでは、通常、各セルにワードが格納されているため、各ワードはアドレス可能です。ワードの長さはビットで表されます。
コンピュータの算術ユニットとコントローラでは、通常、単語単位で送信されます。異なるアドレスに現れる単語の意味は異なります。たとえば、コントローラに送信されるワードは命令であり、算術ユニットに送信されるワードは数値です。メモリ内の
文字列。
「文字」がANSIコード形式で存在する場合、文字は1バイト以上で表される可能性があるため、この種の文字列をANSI文字列またはマルチバイト文字列と呼びます。たとえば、「Chinese123」(非表示の\ 0を含めて8バイトを占有します)。
文字セット
ANSIエンコーディングには、さまざまな文字セット(文字セット)があります。同じバイトシーケンスは、異なる文字セットの異なる文字を表します。ANSI文字列を正しく解析するには、正しい文字セットを選択する必要があります。そうしないと、いわゆる文字化け現象が発生する可能性があります。オペレーティングシステムの異なる言語バージョンには、デフォルトの文字セットがあります。文字セットが指定されていない場合、システムはこの文字セットを使用してANSI文字列を解析します。つまり、日本語のオペレーティングシステムで保存されたANSIテキストファイル(ANSI文字列のみを含むテキストファイル)を、簡略化された中国語版のWindowsで開くと、文字が文字化けします。ただし、このファイルをVisual Studioなどのエンコードを選択したテキストエディターで開き、正しい文字セットを選択すると、元の外観を確認できます。注:簡略化された漢字セットの繁体字と繁体字中国語の文字セットの繁体字は、同じエンコーディングを持たない場合があります。
各文字セットには、コードページ(コードページ)と呼ばれる特定の番号があります。簡体字中国語(GB2312)のコードページは936であり、システムのデフォルトの文字セットのコードページは0です。これは、システムの言語設定に従って適切な文字セットが選択されることを意味します。
Unicode
文字列はメモリに保存されます。「文字」がUnicodeのシリアル番号として存在する場合、この文字列をUnicode文字列またはワイドバイト文字列と呼びます。Unicodeでは、各文字は2バイトを占めます。たとえば、「Chinese123」(10バイトを占有)。UnicodeとANSIの違いは、入力方式の「全角」と「半値」の違いに相当します。
異なるANSIコードで規定されている標準が異なる(文字セットが異なる)ため、特定のマルチバイト文字列について、使用されている「文字」が含まれていることを知るには、使用されている文字セットを知る必要があります。Unicode文字列の場合、環境に関係なく、それが表す「文字」の内容は常に同じです。Unicodeには統一された標準があり、世界中のほとんどの文字のエンコーディングを定義しているため、ラテン語、数字、簡体字中国語、繁体字中国語、および日本語を同じエンコーディングで格納できます。
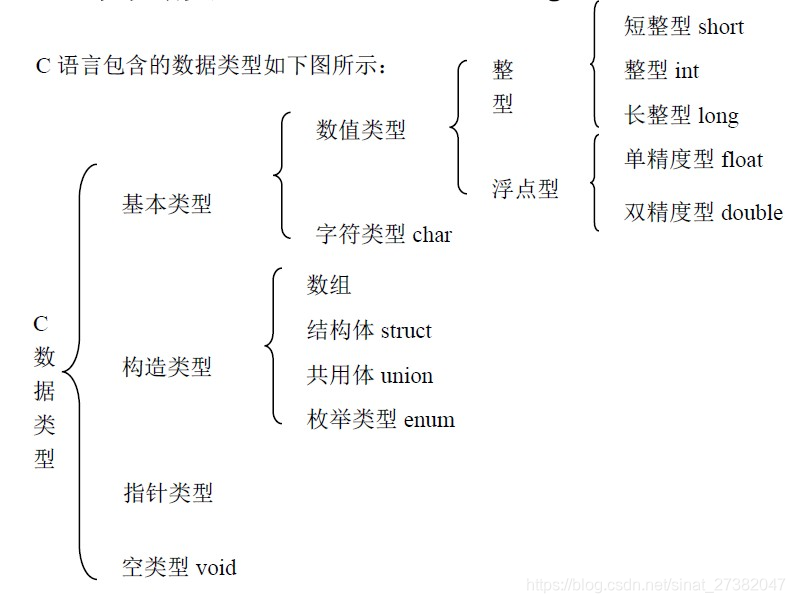
2.練習:C言語プログラム。
1.ストレージタイプ
マイクロコンピュータでは、メモリの記憶容量を表すために通常何バイトが使用されます。
システムが異なれば、これらの型が占めるバイト長は異なります
。short、int、long、char、float、doubleこれらの6つのキーワードは、C言語の6つの基本データ型を表します。
32ビットシステムで
charが占めるメモリサイズは1バイトです。
shortが占めるメモリサイズは2バイト、
intが占めるメモリサイズは4バイト、
floatが占めるメモリサイズは4バイト、
doubleが占めるメモリサイズは8バイト、
longintが占めるメモリサイズは4バイトです。 ;
* C言語のキーワードsizeof()を使用して、現在占有されているバイト数を取得できます。
整数int、浮動小数点float、およびunsigned unsigned
はバイト長が同じですが、格納方法と読み取り方法が異なります。
詳細については、他のブログを参照してください。C言語は0.000000または文字化けした文字を出力し、それを掘り下げます。
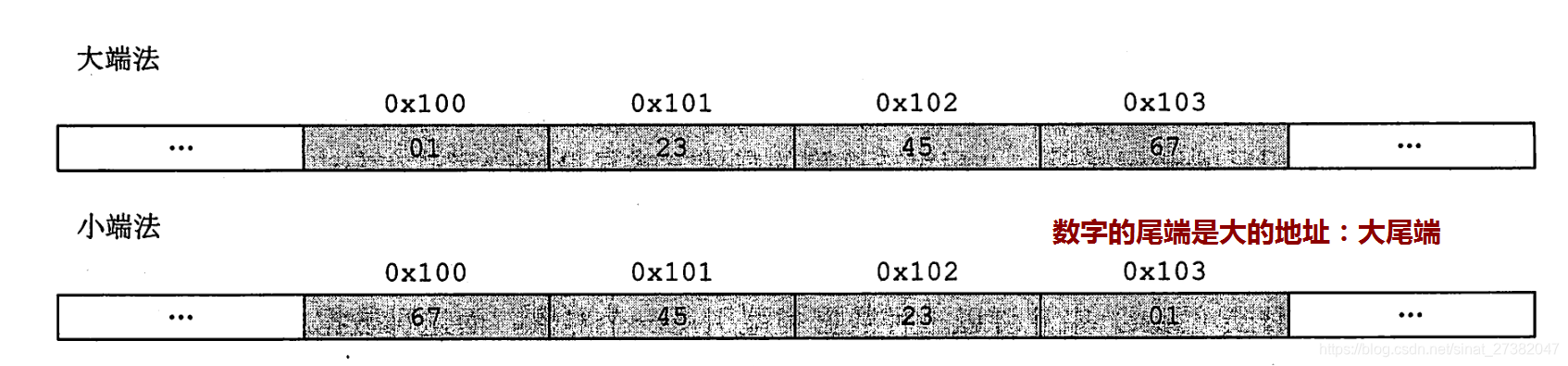
2.ビッグエンディアン、リトルエンディアン(バイトオーダー)
ビッグエンディアンモードとは、データの上位バイトがメモリの下位アドレスに格納され、データの下位バイトがメモリの上位アドレスに格納されることを意味します。このストレージモードは、データを文字列として扱うのと少し似ています。シーケンス処理:アドレスは小さいものから大きいものへと増加し、データは高いものから低いものへと配置されます。これは、私たちの読み取り習慣と一致しています。
リトルエンディアンモードとは、データの上位バイトがメモリの上位アドレスに格納され、データの下位バイトがメモリの下位アドレスに格納されることを意味します。このストレージモードは、アドレスの上位と下位を効果的に組み合わせます。データビットの重みアップすると、アドレスの高い部分の重みが大きくなり、アドレスの低い部分の重みが小さくなります。
*注
この画像のメモリブロックは8ビットのバイトであるため、2 F(16進数、4ビット、1111)を入力
します。この画像を見るときは、「01」、「23」、「45」を入力する必要があります。 、「67」は「1ワード、左右の構造」と見なされる
ため、
1。「76 54 32 10」はリトルエンディアンに表示されません
。2。ネットワークバイトオーダーは、short、int、doubleなどに複数表示されます。バイト、エンディアンネスの問題。
ビッグエンディアンかどうかを判断する
bool IsBig_Endian()
//如果字节序为big-endian,返回true;
//反之为little-endian,返回false
{
unsigned short test = 0x1122;
if (*((unsigned char*)&test) == 0x11)
return 1;
else
return 0;
}//IsBig_Endian()
3.異なるシステム/マシン/コンパイラのワードは異なるバイトを占有します
バスは通常、固定サイズのデータを送信するように設計されています。このデータはワードと呼ばれます。ワードに含まれるバイト数(つまり、ワードのサイズ)は、さまざまなコンピュータの基本的なパラメータです。通常、システムによって異なります。最近のほとんどのコンピュータシステムでは、ワードは4バイトまたは8バイトのいずれかです。
これから、ワードのサイズはワードに依存するため、ワードが何バイトを占めるかを尋ねるだけでは意味がないことがわかります。特定のシステムのバス幅、32ビットシステム(X86)の場合、ワードは4バイト、64ビット(X64)の場合、8バイトです。
4.ビットエンド(ビットフィールド)、ビット演算、構造
ビット演算を実行する場合、現在の最大ビットが使用されるいくつかの状況も知る必要があります
#include<stdio.h>
#define WORDSIZE 32 //我现在是X86模式编译,占32位,4字节(32位=4字节)
int main()
{
unsigned a, b, c;
int n;
printf("请输入a和n \n");
scanf("%x,%d", &a, &n);
b = a << (WORDSIZE - n);//书中源码这里是16(字节),我运行发现总是不对,发现我现在是X86模式编译,占32位
c = a >> n;
c = c ^ b;
printf("a:%x \nc:%x", a, c);
printf("%d", IsBig_Endian());
return 0;
}
3.スケール単位(国際単位系の接頭辞)
異なる桁間の国際単位系(SI):
1KB = 1024B; 1MB = 1024KB = 1024×1024B。
電気技術の文字記号に関する国際電気標準会議の規格は、IEC60027-2およびIEC80000-13です。
データストレージは10進法で表され、データ送信は2進法で表されるため、1KBは1000Bに等しくありません。
1B(バイト、バイト)= 8ビット(以下を参照);
1KB(キロバイト、キロバイト)= 1024B = 2 ^ 10 B;
1MB(メガバイト、メガバイト、ミリオンバイト、「メガ」と呼ばれる)= 1024KB = 2 ^ 20 B;
1GB(ギガバイト、ギガバイト、10億バイト、「ギガバイト」とも呼ばれる)= 1024MB = 2 ^ 30 B;
1TB(テラバイト、兆バイト、テラバイト)= 1024GB = 2 ^ 40 B;
1PB(ペタバイト、ペタバイト、ペタバイト)= 1024TB = 2 ^ 50 B;
1EB(Exabyte、数十exabytes 、exabytes)= 1024PB = 2 ^ 60 B;
1ZB(Zettabyte、10兆バイト、zettabytes)= 1024EB = 2 ^ 70 B;
1YB(Yottabyte、1 1億バイト、八尾バイト)= 1024ZB = 2 ^ 80 B;
1BB(Brontobyte、1000億バイト)= 1024YB = 2 ^ 90 B;
1NB(NonaByte、1兆兆バイト)= 1024BB = 2 ^ 100 B ;
1DB(DoggaByte、10億バイト)= 1024 NB = 2 ^ 110 B;
yotta Y 10008 10^24 1000000000000000000000000 Septillion Quadrillion 1991
zetta Z 10007 10^21 1000000000000000000000 Sextillion Trilliard 1991
exa E 10006 10^18 1000000000000000000 Quintillion Trillion 1975
peta P 10005 10^15 1000000000000000 Quadrillion Billiard 1975
tera T 10004 10^12 1000000000000 Trillion Billion 1960
giga G 10003 10^9 1000000000 Billion Milliard 1960
mega M 10002 10^6 1000000 Million 1960
kilo k 10001 10^3 1000 Thousand 1795
hecto h 10002⁄3 10^2 100 Hundred 1795
deca da 10001⁄3 10^1 10 Ten 1795
10000 10^0 1 One
deci d 1000−1⁄3 10^−1 0.1 Tenth 1795
centi c 1000−2⁄3 10^−2 0.01 Hundredth 1795
milli m 1000−1 10^−3 0.001 Thousandth 1795
micro µ 1000−2 10^−6 0.000001 Millionth 1960[2]
nano n 1000−3 10^−9 0.000000001 Billionth Milliardth 1960
pico p 1000−4 10^−12 0.000000000001 Trillionth Billionth 1960
femto f 1000−5 10^−15 0.000000000000001 Quadrillionth Billiardth 1964
atto a 1000−6 10^−18 0.000000000000000001 Quintillionth Trillionth 1964
zepto z 1000−7 10^−21 0.000000000000000000001 Sextillionth Trilliardth 1991
yocto y 1000−8 10^−24 0.000000000000000000000001 Septillionth Quadrillionth
漢王朝の徐悦による修州書には、量を示す漢数字が小から大まで完全に記録されており、1、10、100、1000、兆、10億(10 8)、趙(10・12)、北京(10・16)、ガイ(10・20)、ジ(10・24)、ラン(10・28)、ゴウ(10・32)、ジアン(10・36)、チェン(10・10・40)とセット(10・44)。それ以来、仏教と文化交流の導入により、極(10・48)、ガンジス砂(10・52)、僧侶(10・56)が追加されました。)、Nayuta (10・60)、信じられない(10・64)、計り知れない(10・68)、大きな数字(10・72)など。そのうち1万以下は小数で、1万以上は1万です。
参照引用:
https ://baike.baidu.com/item/byte
https://blog.csdn.net/weixin_34082177/article/details/86135393
http://bbs.gongkong.com/d/201504/613475_1。shtml
https://blog.csdn.net/guosir_/article/details/78346472
https://blog.csdn.net/hammer_xie/article/details/52301243
https://www.crifan.com/big_endian_big_endian_and_small_end_little_endian_detailed/
https:/ / zhidao.baidu.com/question/1308113215598827339.html
https://www.cnblogs.com/ricksteves/p/9899893.html