ETLの基本
1.基本的な概念
1.1背景
- 企業自身のニーズ:企業の発展に伴い、データ情報化の時代の到来が加速し、各企業のビジネスシステム間のデータフローが遮断され、ビジネス統合が困難になり、データ共有が不便になり、「データアイランド」という現象が発生しています。エンタープライズデータの分析と利用、レポートの開発、分析、マイニングは大きな困難をもたらしました。
- 社会開発の必要性:さまざまな分野の開発に伴い、州は統合プラットフォームの構築を提唱しています。これは主に「データアイランド」によってもたらされるいくつかの問題と欠点を解決します。
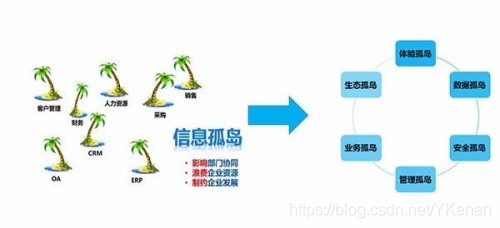
統合プラットフォームを構築するために必要な条件は、データの統合です。エンタープライズグローバルデータ(情報アイランド、データ統計、データ分析、データマイニング)の体系的な運用と管理を実現します。DSS(意思決定支援システム)、BI(ビジネスインテリジェンス)の場合ビジネス分析システムなどの詳細な開発とアプリケーションの基盤を築き、データの価値を掘り起こすために、企業はデータウェアハウスとデータセンターの構築を開始します。個別のビジネスシステムのデータソースを統合して、統合されたデータ収集、処理、およびストレージを確立します。 、配布、共有センター。
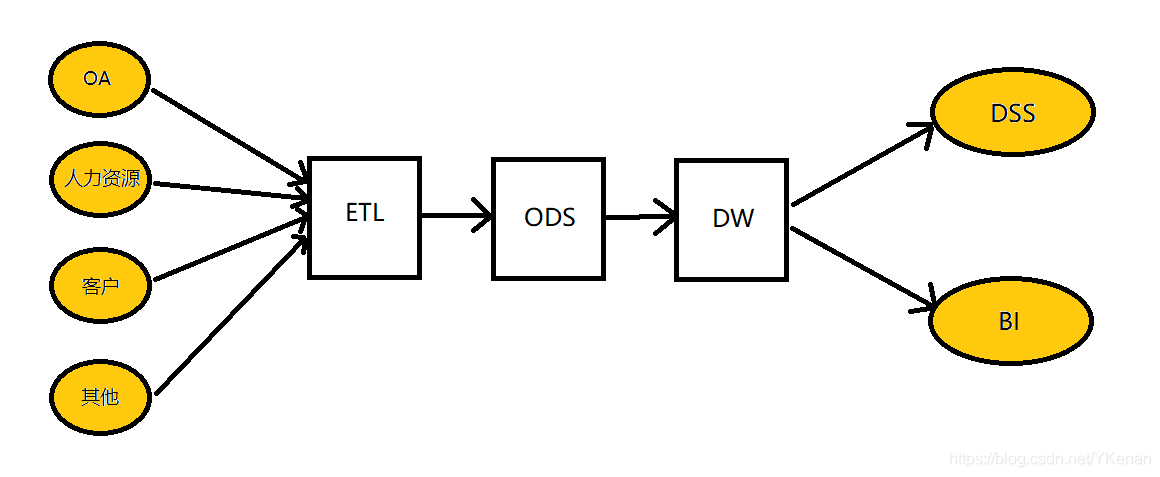
ETLはBIプロジェクトの重要な部分です。通常、BIプロジェクトでは、ETLはプロジェクト全体の少なくとも1/3を費やし、ETL設計の品質はBIプロジェクトの成功または失敗に直接関係します。
1.2定義
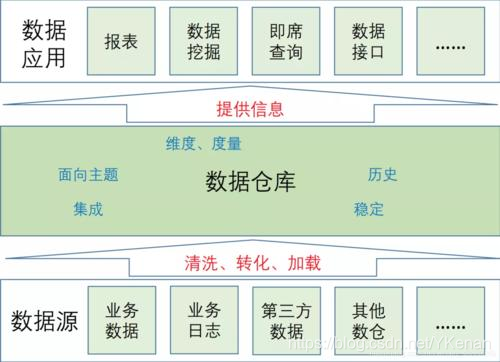
ETLは、ビジネスシステムのデータを抽出、クリーニング、変換(変換)してから、データウェアハウスにロード(ロード)するプロセスです。目的は、散在し、乱雑で、不均一なデータを企業に統合することです。意思決定のための分析基盤を提供します。
ETLの設計は、データ抽出、データのクリーニングと変換、およびデータのロードの3つの部分に分かれています。
ETLの設計は、次の3つの部分から始まります。データの抽出は、さまざまなデータソースからODS(運用データストア、運用データストレージ)に抽出されます。このプロセスでは、抽出時にデータのクリーニングと変換も行うことができます。その過程で、ETLの効率を可能な限り向上させるために、さまざまな抽出方法を選択する必要があります。ETLの3つの部分の中で、最も長い時間は「T」(変換、クリーニング、変換)部分であり、通常は機能します。量はETL全体の2/3です。データのロードは通常、データがクリーンアップされた後、DW(データウェアハウジング、データウェアハウス)に直接書き込まれます。
1.2.1データ抽出(抽出)
1. 确定数据源, 需要确定从哪些源系统进行数据抽取 2. 定义数据接口, 对每个源文件及系统的每个字段进行详细说明 3. 确定数据抽取的方法: 是主动抽取还是由源系统推送? 是增量抽取还是全量抽取? 是按照每日抽取还是按照每月抽取?
1.2.2データのクリーニングと変換(クリーニング、変換)
通常の状況では、データウェアハウスはODSとDWの2つの部分に分かれています。通常は、ビジネスシステムからODSにクリーンアップし、ダーティで不完全なデータを除外し、その過程でODSからDWに変換し、いくつかのビジネスルールを実装します。計算と集計。ODSは
1. 数据清洗:
1.1 不完整的数据
1.2 错误的数据
1.3 重复的数据
2. 数据转换:
2.1 空值处理: 可捕获字段空值, 进行加载或替换为其他含义数据, 或数据分流问题库
2.2 数据标准: 统一元数据、统一标准字段、统一字段类型定义
2.3 数据拆分: 依据业务需求做数据拆分, 如身份证号, 拆分区划、出生日期、性别等
2.4 数据验证: 时间规则、业务规则、自定义规则
2.5 数据替换: 对于因业务因素, 可实现无效数据、缺失数据的替换
2.6 数据关联: 关联其他数据或数学, 保障数据完整性
1.2.3データの読み込み(読み込み)
データバッファ内のデータをデータベースの対応するテーブルに直接ロードします。全額メソッドの場合はLOADメソッドを使用し、増分金額の場合はビジネスルールに従ってデータベースにマージします。
1.3一般的な実装
- ETLツールの助けを借りて。:なOracleのOWB、SQL Server 2000ののDTSなどSQL Server2005のSSISサービス、インフォマティクス、実現などのツールの助けを借りて、ETLプロジェクトはすぐに、その盾複雑なコーディング作業を確立することができ、スピードを向上させ、そして難しさを低減します。しかし、それは柔軟性に欠けています。
- SQLの実装:利点は柔軟性であり、ETL操作の効率が向上しますが、コーディングが複雑で、技術的な要件が比較的高くなります。
- ETLツールとSQLの組み合わせ:前の2つの利点を組み合わせると、ETL開発の速度と効率が大幅に向上します。
2.モードの紹介
ETLには、トリガーモード、インクリメンタルフィールド、完全同期、ログ比較の4つの主要な実装モードがあります。
2.1トリガーモード
トリガー方式は、一般的に採用されているインクリメンタル抽出メカニズムです。この方式では、抽出要件に応じて、抽出するソーステーブルに挿入、変更、削除の3つのトリガーを作成します。ソーステーブルのデータが変更されるたびに、対応するトリガーは、変更されたデータを増分ログテーブルに書き込みます。ETLの増分抽出は、ソーステーブルから直接ではなく、増分ログテーブルからデータを抽出します。同時に、増分ログテーブルが抽出されます。データは時間内にマークまたは削除する必要があります。簡単にするために、増分ログテーブルには通常、増分データのすべてのフィールド情報が格納されるのではなく、ソーステーブル名、更新されたキー値、および更新操作タイプ(挿入、更新、または削除)のみが格納されます。 、ETL増分抽出プロセスは、最初にソーステーブル名と更新されたキーワード値に従ってソーステーブルから対応する完全なレコードを抽出し、次に更新操作のタイプに従ってターゲットテーブルに対して対応する処理を実行します。
利点:高いデータ抽出パフォーマンス、シンプルなETL読み込みルール、高速、ビジネスシステムテーブル構造を変更する必要がなく、データの増分読み込みを実現できます。
短所:トリガーを確立するにはビジネステーブルが必要です。トリガーはビジネスシステムに一定の影響を与え、ソースデータベースに脅威を与える可能性があります。
2.2インクリメントフィールド
インクリメンタルフィールド方式は、変更されたデータをキャプチャするために使用されます。原則は、ソースシステムのビジネステーブルデータテーブルにインクリメンタルフィールドを追加することです。インクリメンタルフィールドは、時間フィールドまたは自己増加フィールド(Oracleシーケンスなど)にすることができます。設計要件はソースです。ビジネスシステムのデータが追加または変更されると、増分フィールドが変更され、タイムスタンプフィールドが対応するシステム時間に変更され、自己増分フィールドが増加します。
ETLツールが増分データ取得を実行する場合は常に、最新のデータ抽出の増分フィールド値を比較するだけで、どちらが新しいデータでどちらが変更されたデータであるかを判断できます。このデータ抽出方法の利点は、抽出パフォーマンスです。比較的高く、判断プロセスも比較的簡単です。最大の制限は、一部のデータベースは設計時にインクリメンタルフィールドを考慮しないため、データベースの他の側面に基づいてビジネスシステムを変更する必要があるため、データ漏洩が発生する可能性があることです。場合。
利点:トリガー方式と同様に、タイムスタンプ方式のパフォーマンスが向上し、ETLシステムの設計が明確になり、ソースデータの抽出が比較的明確で単純になり、データの増分読み込みを実現できます。
短所:タイムスタンプのメンテナンスはビジネスシステムで完了する必要があります。また、特にタイムスタンプの自動更新をサポートしておらず、ビジネスシステムへの追加の更新が必要なデータベースの場合、ビジネスシステムに非常に煩わしい(タイムスタンプフィールドの追加)。タイムスタンプ操作。さらに、タイムスタンプより前のデータの削除および更新操作はキャプチャできません。これは、データの精度に制限があります。
2.3完全同期
完全同期は、完全テーブルの削除と挿入とも呼ばれます。つまり、各抽出の前にターゲットテーブルのデータが削除され、抽出中にデータが新たに読み込まれます。この方法では、実際には、増分抽出と完全抽出が同じです。少量のデータの場合、完全抽出この方法は、時間コストが増分抽出を実行するアルゴリズムおよび条件付きコストよりも小さい場合に使用できます。
同期プロセス:

利点:既存のシステムテーブル構造に影響を与えず、ビジネスの運用手順を変更する必要がなく、すべての抽出ルールがETLによって完了し、管理と保守が統合され、リスクなしでデータの増分ロードを実現できます。
短所:ETL比較がより複雑になり、設計がより複雑になり、速度が遅くなります。トリガーおよびタイムスタンプ方式のアクティブ通知とは異なり、完全なテーブル比較方式では、テーブルデータ全体をパッシブに比較するため、パフォーマンスが低下します。テーブルにプライマリキーまたは一意の列がなく、レコードが重複している場合、テーブル全体の比較方法の精度が低下します。
2.4ログの比較
ログ比較の方法は、データベースレベルでログを取得して変更データを取得する方法です。ソースビジネスシステムデータベースの関連テーブル構造を変更する必要はありません。データ同期の効率は比較的高く、同期の適時性は比較的高速です。最大の問題は前面です。上記の異なるデータベースのデータベースログファイル構造には大きな違いがあり、実装と分析がより困難です。同時に、ソースビジネスデータベースのログテーブルファイルにアクセスするためのアクセス許可が必要です。一定のリスクがあるため、この方法には大きな制限。
ログ比較方法のより成熟したテクノロジーは、OracleのCDC(Changed Data Capture)テクノロジーです。これは、最後の抽出後に生成された関連する変更データをキャプチャすることもできます。CDCがソースビジネステーブルを追加、更新、および削除すると、関連する操作を待つときに、関連する変更データをキャプチャできます。インクリメンタルフィールド方式と比較して、CDC方式では、削除されたデータをより適切にキャプチャし、関連するデータベースログテーブルに書き込んでから、ビューまたはその他の種類のデータを使用できます。操作方法は、キャプチャされた変更をデータウェアハウスに同期します。
利点:ETL同期効率が高く、ビジネスシステムテーブル構造を変更する必要がなく、データの増分ロードを実現できます。
短所:ビジネスシステムデータベースのバージョンと製品が統一されておらず、均一に実装することが困難です。実装プロセスは比較的複雑であり、それを実現するには綿密な調査が必要です。またはサードパーティのツール、一般的には商用ソフトウェアを使用し、コストが高くなります。
2.5モード比較
| インクリメンタルメカニズム | 互換性 | 完全 | 抽出性能 | ソースライブラリの圧力 | ソースライブラリの変更 | 実現の難しさ |
|---|---|---|---|---|---|---|
| 引き金 | リレーショナルデータベース | 高い | 優秀な | 高い | 高い | 簡単 |
| 増分フィールド | リレーショナルデータベース。「フィールド」構造を持つ他のデータ形式 | 低 | より良い | 低 | 高い | 簡単 |
| テーブル全体の同期 | 任意のデータ形式 | 高い | ひどい | に | 番号 | 簡単 |
| ログ比較 | リレーショナルデータベース(oracle / mysql) | 高い | より良い | に | に | もっと強く |
3. ETLログ、警告送信
3.1ETLログ
ETLログは3つのカテゴリに分類されます。
- 実行プロセスログ:ログのこの部分は、ETL実行プロセスの各ステップの記録であり、各実行の各ステップの開始時刻、影響を受けるデータの行数、および実行中のアカウントの形式を記録します。
- エラーログ:モジュールがエラーを起こしたときにエラーログを書き込み、各エラーの時刻、エラーモジュール、およびエラー情報を記録します。
- ログは全体的なログです。ETLの開始時刻と終了時刻が成功したかどうかのみを記録します。ETLツールを使用すると、ETLツールによっていくつかのログが自動的に生成されます。このタイプのログはETLログの一部にすることもできます。
ロギングの目的は、ETLの実行ステータスをいつでも知ることであり、問題が発生した場合は、どこで問題が発生したかを知ることができます。
3.2警告の送信
ETLエラーが発生した場合は、ETLエラーログを作成するだけでなく、システム管理者に警告を送信する必要があります。警告を送信する方法はたくさんありますが、最も一般的な方法は、システム管理者に電子メールを送信し、エラーメッセージを添付して、管理者がエラーのトラブルシューティングを行えるようにすることです。
ETLはBIプロジェクトの重要な部分であり、長期的なプロセスでもあります。問題を継続的に発見して解決することによってのみ、ETLをより効率的に実行し、BIプロジェクトのその後の開発のために正確で効率的なデータを提供できます。
4.ETLツール
4.1ETLツールを使用する理由
データが異なる物理ホストからのものである場合、SQLステートメントを使用して処理するのはより手間とコストがかかります。
データソースは、さまざまなデータベースやファイルにすることができます。現時点では、データを処理する前に、それらを統一された形式に整理する必要があります。このプロセスは、コードで実装するのが明らかに少し面倒です。
もちろん、ストアドプロシージャを使用してデータベース内のデータを処理することもできますが、大量のデータを処理する場合、ストアドプロシージャは明らかに手間がかかり、より多くのデータベースリソースを使用するため、データベースリソースが不足し、データベースのパフォーマンスに影響を与える可能性があります。
4.2ETLツールの選択基準
1. 对平台的支持程度
2. 抽取和装载的性能是不是较高, 且对业务系统的性能影响大不大, 侵入性高不高
3. 对数据源的支持程度
4. 是否具有良好的集成性和开放性
5. 数据转换和加工的功能强不强
6. 是否具有管理和调度的功能
4.3主流のETLツールに関する推奨事項
| PDI(ケトル) | データステージ |
|---|---|
| 自由 | IBMビジネスソフトウェア |
| オープンソース製品、純粋なJAVAコードで記述されたETLツール | 高価なプロのETLツール |
| クロスプラットフォーム | 大規模なETLアプリケーションに適しています |
| 優れたスケーラビリティ |
参照URL:
[1]:https://www.cnblogs.com/yjd_hycf_space/p/7772722.html
[2]:https://blog.csdn.net/jianzhang11/article/details/104240047/