「以下は、私が遭遇した問題といくつかの簡単なトラブルシューティングのアイデアです。何か問題がある場合は、メッセージを残して話し合ってください。InMemoryReporterMetricsが原因でOOMの問題が発生し、それが解決された場合は、この記事を無視できます。正しい場合CPU100%とオンラインアプリケーションのOOMトラブルシューティングのアイデアは明確ではありません。この記事を閲覧できます。
問題現象
【警報通知・アプリ異常警報】

警告メッセージを見てください。接続が拒否されました。とにかく、サービスに問題があります。モザイクについてはあまり気にしないでください。
環境の説明
Spring Cloud F版。
デフォルトでは、zipkin-reporterに依存するためにプロジェクトでspring-cloud-sleuth-zipkinが使用されます。分析されたバージョンでは、zipkin-reporterのバージョンが2.7.3であることがわかりました。
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin</artifactId>
</dependency>
版本:2.0.0.RELEASE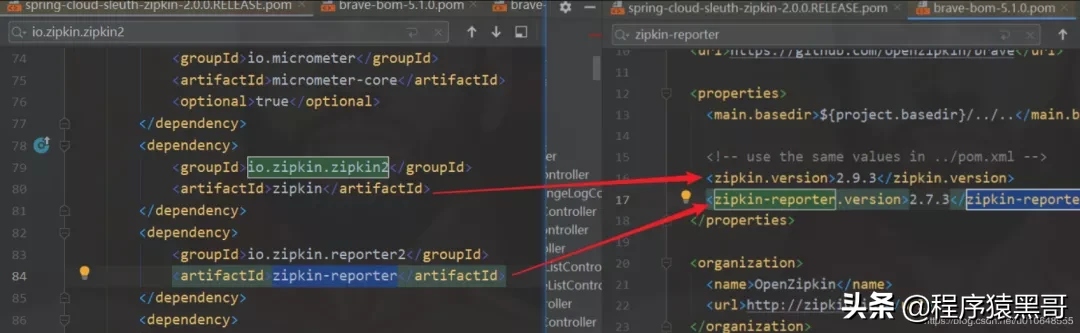
インプリント
トラブルシューティング
アラーム情報により、どのサーバーにどのサービスの問題があるかを知ることができます。最初にサーバーにログインして確認します。
1.サービスのステータスを確認し、ヘルスチェックURLに問題がないかどうかを確認します
「このステップは無視/スキップできます。これは実際の会社のヘルスチェックに関連しており、普遍的なものではありません。
①サービスプロセスが存在するか確認してください。
"Ps -ef | grepサービス名ps -aux | grepサービス名
②該当するサービスヘルスチェックのアドレスが正常か確認し、IPポートが正しいか確認する
「アラートサービスチェック用に構成されたURLは間違っていますか?通常、これは問題を引き起こしません。
③健康診断住所を確認する
「このヘルスチェックアドレスは次のようなものです。http://192.168.1.110:20606 / serviceCheckは、IPとポートが正しいかどうかを確認します。
# 服务正常返回结果
curl http://192.168.1.110:20606/serviceCheck
{"appName":"test-app","status":"UP"}
# 服务异常,服务挂掉
curl http://192.168.1.110:20606/serviceCheck
curl: (7) couldn't connect to host
2.サービスログを表示する
サービスログがまだ印刷されているかどうか、要求が送信されていないかどうかを確認します。検出サービスOOMを確認してください。
OOMエラー
ヒント:java.lang.OutOfMemoryError GCオーバーヘッド制限を超えました
Oracleの官庁は、この発生の原因と解決方法を示します:スレッドthread_nameの例外:java.lang.OutOfMemoryError:GCオーバーヘッド制限を超えました原因:詳細メッセージ「GCオーバーヘッド制限を超えました」は、ガベージコレクターが常に実行されていることを示しますそしてJavaプログラムは非常に遅い進歩を遂げています。ガベージコレクション後、Javaプロセスがガベージコレクションに費やす時間の約98%以上を費やしていて、ヒープの2%未満しか回復せず、これまでに最後の5(コンパイル時定数)ガベージを実行している場合コレクションの場合、java.lang.OutOfMemoryErrorがスローされます。この例外は通常、新しいデータを割り当てるための空き領域がほとんどないJavaヒープにライブデータの量がほとんど収まらないためにスローされます。処置:ヒープ・サイズを増やしてください。java.lang。
理由:これはおそらく、JVMがガベージコレクションに98%の時間を費やしているが、利用可能なメモリの2%しか取得していないことを意味します。頻繁なメモリコレクション(少なくとも5つの連続したガベージコレクションが実行された)、JVMは公開しますAva.lang.OutOfMemoryError:GCオーバーヘッド制限超過エラーが発生しました。

上記のヒントのソース:java.lang.OutOfMemoryError GCオーバーヘッドの制限を超えた原因分析と解決策
3.サーバーリソースの使用状況を確認する
システム内の各プロセスのリソース占有状況を照会するには、topコマンドを使用します。次のスクリーンショットに示すように、CPU使用率が300%に達するプロセスが11441であるプロセスがあることを確認します。

CPUバーストテーブル
次に、このプロセスのすべてのスレッドのCPU使用率をクエリします。
「
top -H -p pidファイルを保存します。top -H -n 1 -p pid> /tmp/pid_top.txt
# top -H -p 11441
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
11447 test 20 0 4776m 1.6g 13m R 92.4 20.3 74:54.19 java
11444 test 20 0 4776m 1.6g 13m R 91.8 20.3 74:52.53 java
11445 test 20 0 4776m 1.6g 13m R 91.8 20.3 74:50.14 java
11446 test 20 0 4776m 1.6g 13m R 91.4 20.3 74:53.97 java
....PID:11441の下のスレッドを確認し、いくつかのスレッドがより高いCPUを使用していることを確認します。
4.スタックデータを保存する
1.システムロードスナップショットを印刷します top -b -n 2> /tmp/top.txt top -H -n 1 -p pid> /tmp/pid_top.txt
2. CPU昇順印刷プロセスに対応するスレッドリストps -mp-o THREAD、tid、time | sort -k2r> / tmp / process number_threads.txt
3. tcp接続の数を確認します(複数回サンプリングすることが望ましい)lsof -pプロセス番号> / tmp /プロセス番号_lsof.txt lsof -pプロセス番号> / tmp /プロセス番号_lsof2.txt
4.スレッド情報を表示する(できれば複数回サンプリングする) jstack -lプロセス番号> / tmp /プロセス番号_jstack.txt jstack -lプロセス番号> / tmp /プロセス番号_jstack2.txt jstack -lプロセス番号> / tmp / process No._jstack3.txt
5.ヒープメモリ使用量の概要を表示する jmap -heap process number> / tmp / process number_jmap_heap.txt
6.ヒープ内のオブジェクトの統計を表示する jmap -histoプロセス番号| head -n 100> / tmp /プロセス番号_jmap_histo.txt
7. GC統計の表示 jstat -gcutilプロセス番号> / tmp /プロセス番号_jstat_gc.txt 8.本番からヒープへのスナップショットヒープダンプjmap -dump:format = b、file = / tmp /プロセス番号_jmap_dump.hprofプロセス番号
「ヒープのすべてのデータ、生成されたファイルはより大きくなります。
jmap -dump:live、format = b、file = / tmp / process number_live_jmap_dump.hprofプロセス番号
「Dump:live、このパラメーターは、現在ライフサイクルにあるメモリオブジェクト、つまり、GCが収集できないオブジェクトを取得する必要があることを意味します。通常、これを使用します。
問題のあるスナップショットデータを取得し、サービスを再起動します。
問題分析
以上の操作により、対象となるサービスのGC情報、スレッドスタック、ヒープスナップショットなどのデータが取得できました。それを分析して、問題がどこにあるかを確認しましょう。
1. CPUによって占有されているスレッドの100%を分析する
変換スレッドID
jstackから生成されたスレッドスタックプロセスの分析。
上記のスレッドIDを11447に変換します:0x2cb711444:0x2cb411445:0x2cb511446:0x2cb6を16進数に変換します(jstackコマンドの出力ファイルに記録されるスレッドIDは16進数です)。最初の変換方法:
$ printf “0x%x” 11447
“0x2cb7”2番目の変換方法:変換結果に0xを追加します。
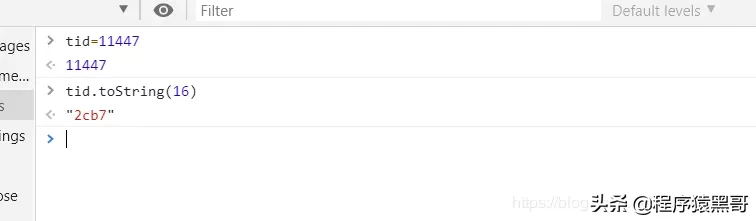
スレッドスタックを見つける
$ cat 11441_jstack.txt | grep "GC task thread"
"GC task thread#0 (ParallelGC)" os_prio=0 tid=0x00007f971401e000 nid=0x2cb4 runnable
"GC task thread#1 (ParallelGC)" os_prio=0 tid=0x00007f9714020000 nid=0x2cb5 runnable
"GC task thread#2 (ParallelGC)" os_prio=0 tid=0x00007f9714022000 nid=0x2cb6 runnable
"GC task thread#3 (ParallelGC)" os_prio=0 tid=0x00007f9714023800 nid=0x2cb7 runnableこれらのスレッドがGC操作を実行していることがわかりました。
2.生成されたGCファイルを分析する
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
0.00 0.00 100.00 99.94 90.56 87.86 875 9.307 3223 5313.139 5322.446- S0:生存ゾーン1の現在の比率
- S1:生存ゾーン2の現在の比率
- E:エデンスペース(エデンガーデン)面積使用率
- O:旧世代(旧世代)の使用率
- M:メタデータ領域の使用率
- CCS:圧縮比
- YGC:若い世代のガベージコレクションの数
- FGC:古い時代のガベージコレクションの数
- FGCT:古い時代のガベージコレクションには時間がかかる
- GCT:ガベージコレクションによって消費された合計時間
FGCは非常に頻繁です。
3.生成されたヒープスナップショットを分析する
Eclipse Memory Analyzerツールを使用します。ダウンロードリンク:https://www.eclipse.org/mat/downloads.php
分析の結果:
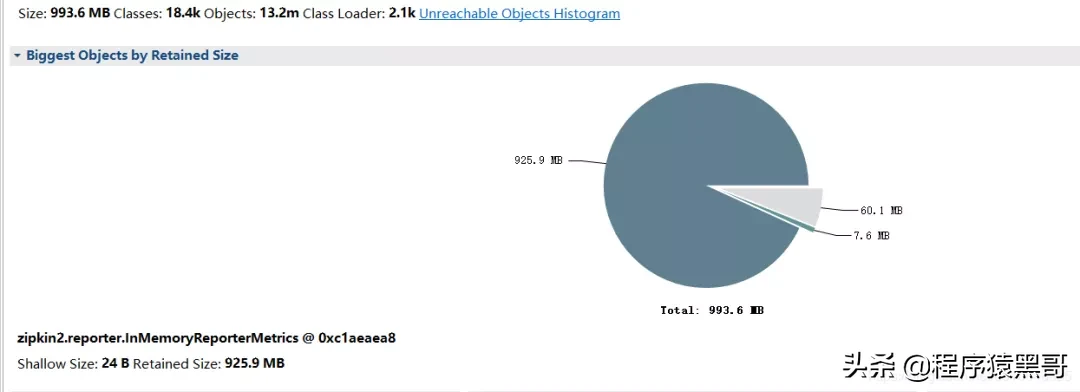
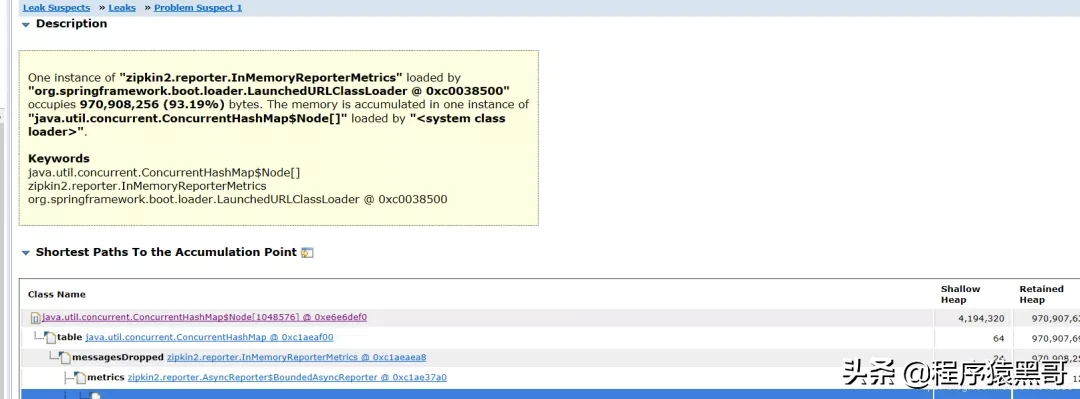
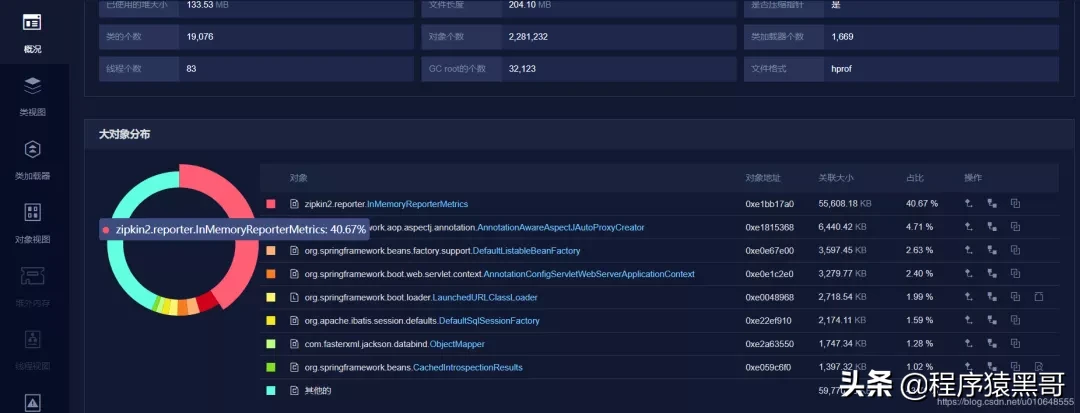
積み重ねられたラージオブジェクトの特定のコンテンツを表示します。

問題の大まかな原因は、InMemoryReporterMetricsが原因のOOMです。zipkin2.reporter.InMemoryReporterMetrics @ 0xc1aeaea8浅いサイズ:24 B保持サイズ:925.9 MB
以下も使用できます:分析用のJavaメモリダンプ(https://www.perfma.com/docs/memory/memory-start)、以下のスクリーンショット、関数はMATほど強力ではなく、一部の関数は有料です。
4.理由の分析と検証
この問題のため、問題のあるzipkinサービスの構成を確認 します。他のサービスとの違いはありません。構成が同じであることがわかりました。
次に、対応するzipkin jarパッケージを試したところ、問題のサービスがzipkinの下位バージョンに依存していることが わかりました。
問題のサービスの zipkin-reporter-2.7.3.jar
およびサービスが依存する他のパッケージ:zipkin-reporter-2.8.4.jar

問題のサービスが依存しているパッケージバージョンをアップグレードし、テスト環境で確認し、スタックスナップショットを確認して、そのような問題がないことを確認します。
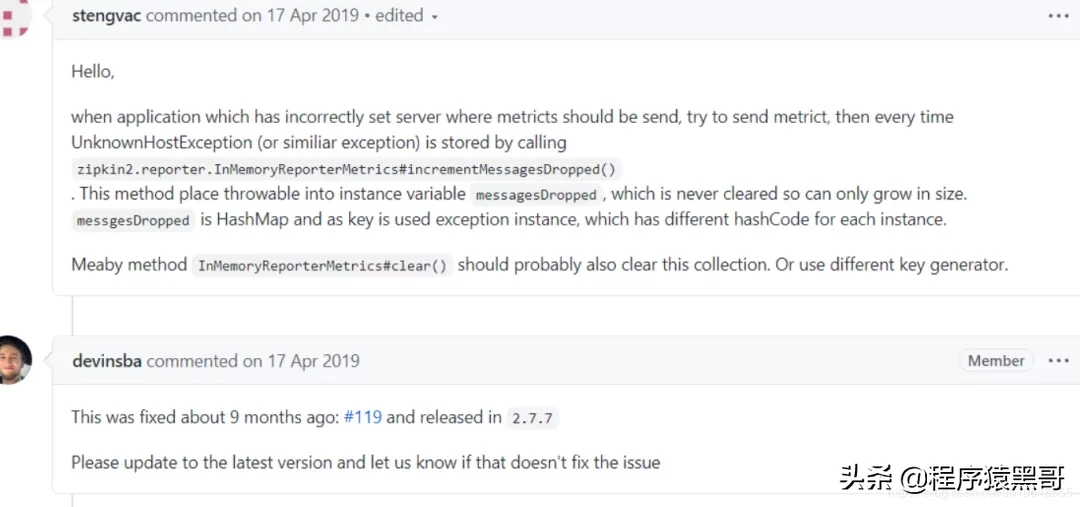
理由探査
zipkin-reporterのgithubを確認します。対応する情報を検索しますhttps://github.com/openzipkin/zipkin-reporter-java/issues?q=InMemoryReporterMetricsと、次の問題を見つけます:https://github.com/openzipkin/zipkin- reporter-java / issues / 139
修復コードと検証コード:https://github.com/openzipkin/zipkin-reporter-java/pull/119/filesコードの2つのバージョンの違いを比較します。

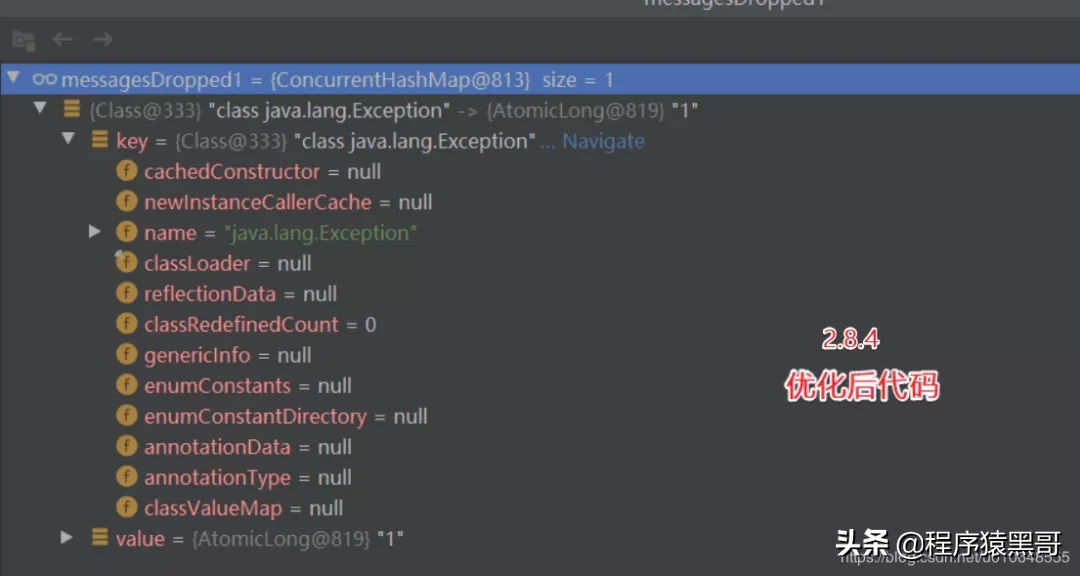
簡単なデモ検証:
// 修复前的代码:
private final ConcurrentHashMap<Throwable, AtomicLong> messagesDropped = new ConcurrentHashMap<Throwable, AtomicLong>();
// 修复后的代码:
private final ConcurrentHashMap<Class<? extends Throwable>, AtomicLong> messagesDropped = new ConcurrentHashMap<>();修復後にこのキーを使用:Class <?extends Throwable>をThrowableに置き換えます。
簡単な検証:

解決
zipkin-reporterのバージョンをアップグレードするだけです。次の依存関係構成を使用します。インポートされた zipkin-reporterのバージョンは2.8.4です。
<!-- zipkin 依赖包 -->
<dependency>
<groupId>io.zipkin.brave</groupId>
<artifactId>brave</artifactId>
<version>5.6.4</version>
</dependency>
ヒント:JVMパラメーターを構成するときに以下のパラメーターを追加し、メモリーがオーバーフローしたときにスタックのスナップショットを出力します。
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=path/filename.hprof