推奨読書:
-
インタビューの質問72件、合計3170ページをまとめ、30以上のインターネット企業のオファー(BATJMを含む)を獲得しました
-
私は2020年に最初の戦いで勝利しました。このJavaインタビューマジックプラスバージョンを使用すると、Ali、JD.com、Bytedanceなどの主要メーカーからオファーを得ることができました。
ローカルキャッシュに関しては、誰もがGuava Cacheを考えることができます。その利点は、取得と書き込み操作のカプセル化、スレッドセーフなキャッシュ操作の提供、有効期限戦略の提供、リサイクル戦略の提供、キャッシュの監視です。キャッシュされたデータが最大値を超えると、LRUアルゴリズムを使用してデータが置き換えられます。この記事では、新しいローカルキャッシュフレームワーク、Caffeine Cacheについて説明します。また、彼のアイデアに基づいてアルゴリズム開発を最適化する巨人であるグアバキャッシュの肩にも立っています。
この記事では主に、SpringBootでのCaffine Cacheの使用とCaffine Cacheの使用について紹介します。
Caffine Cacheアルゴリズムの利点-W-TinyLFU
最適化と言えば、Caffine Cacheは正確には何を最適化しているのですか?先ほどLRUについて説明しましたが、一般的なキャッシュ除去アルゴリズムにはFIFO、LFUが含まれます。
- FIFO:先入れ先出しこの排除アルゴリズムでは、最初にキャッシュに入ったアルゴリズムが最初に排除され、ヒット率が非常に低くなります。
- LRU:最も使用頻度の低いアルゴリズムです。データにアクセスするたびに、チームの最後に配置します。データを削除する必要がある場合は、チームのトップを削除するだけで済みます。それでも問題があります。1分間に1,000回アクセスされたデータが、その後1分間アクセスされず、他のデータアクセスがある場合、ホットデータは削除されます。
- LFU:最近の使用頻度が最も低い、余分なスペースを使用して各データの使用頻度を記録し、次に除去するために最も低い頻度を選択します。これにより、LRUが期間を処理できないという問題が回避されます。
上記の3つの戦略にはそれぞれ長所と短所があり、実装コストは1よりも高く、ヒット率も1よりも優れています。Guava Cacheには非常に多くの機能がありますが、本質的にはLRUをカプセル化します。より優れたアルゴリズムがあり、非常に多くの機能を提供できる場合は、比較すると見劣りします。
「LFUの制限」:LFUでは、データアクセスパターンの確率分布が変化しない限り、ヒット率が非常に高くなる可能性があります。たとえば、新しいドラマが出たとき、LFUを使用して彼のためにキャッシュします。この新しいドラマは過去数日間で数億回アクセスされており、このアクセス頻度もLFU数億回に記録されています。しかし、新しいドラマは常に時代遅れになります。たとえば、1か月後、この新しい番組の最初のいくつかのエピソードは実際には時代遅れですが、彼のトラフィックは確かに多すぎます。他のテレビ番組はこの新しい番組をまったく排除できないため、ここにこのモデルには制限があります。
「 LRUの利点と制限」:LRUはデータ頻度を累積する必要がないため、突然のトラフィック状況に非常によく対応できます。しかし、LRUは履歴データが限られていることから将来を予測し、最後のデータが再度アクセスされる可能性が最も高いと見なし、最も高い優先順位を与えます。
既存のアルゴリズムの制限の下で、キャッシュされたデータのヒット率は多少損なわれ、ヒット率はキャッシュの重要な指標です。HighScalabilityのWebサイトでは、元のGoogleエンジニアが発明したW-TinyLFU(最新のキャッシュ)の記事が公開されました。Caffine Cacheは、このアルゴリズムに基づいて開発されています。カフェインは、ウィンドウTinyLfuリサイクル戦略により、ほぼ最適なヒット率を提供します。
データアクセスパターンが時間とともに変化しない場合、LFU戦略は最高のキャッシュヒット率をもたらすことができます。ただし、LFUには2つの欠点があります。
- まず、各レコードの頻度情報を維持する必要があり、アクセスされるたびに更新する必要があります。これは大きなオーバーヘッドです。
- 第二に、データアクセスパターンが時間とともに変化すると、LFUの頻度情報はそれに応じて変更されないため、頻繁にアクセスされるレコードはキャッシュを占有し、それより後にアクセスされるレコードはヒットしません。
したがって、ほとんどのキャッシュ設計はLRUまたはそのバリアントに基づいています。対照的に、LRUは高価なキャッシュレコードのメタ情報を維持する必要がなく、時間の経過とともに変化するデータアクセスパターンを反映することもできます。ただし、多くの負荷の下では、LRUは、LFUと一致するキャッシュヒットレートを実現するためにより多くの領域を必要とします。したがって、「モダン」キャッシュは、両方の長所を組み合わせることができるはずです。
TinyLFUは、最近のアクセスレコードの頻度情報を保持します。フィルターとして、新しいレコードが来ると、TinyLFUの要件を満たすレコードのみをキャッシュに挿入できます。前述のように、最新のキャッシュとして、次の2つの課題を解決する必要があります。
- 1つは、頻度情報を維持するための高コストを回避する方法です。
- もう1つは、時間とともに変化するアクセスパターンを反映する方法です。
TinyLFUはデータストリームスケッチテクノロジーを使用しています。Count-MinSketchは明らかにこの問題を解決する有効な手段です。非常に低い誤検出率を確保しながら、周波数情報をはるかに小さなスペースに保存できます。しかし、2番目の質問を考えると、どのスケッチングデータ構造でも時間の変化を反映するのは難しいことがわかっているため、はるかに複雑になります。ブルームフィルターでは、タイミングブルームフィルターを使用できますが、CMSketchにはタイミングCMSketchの実行方法に関しては、それほど簡単ではありません。TinyLFUは、単純なリセット操作の助けを借りて、スライディングウィンドウベースの時間減衰設計メカニズムを使用します。レコードがSketchに追加されるたびに、カウンターは1ずつ増分され、カウンターがサイズWに達すると、記録されたすべてのスケッチ値を2で割ります。リセット操作は減衰の役割を果たすことができます。
W-TinyLFUは主に、一部のスパースバーストアクセス要素を解決するために使用されます。数は少ないがバーストアクセスが多いシーンでは、TinyLFUは一定の時間に十分な頻度で蓄積できないため、そのような要素を保存できません。したがって、W-TinyLFUはLFUとLRUの組み合わせであり、前者はほとんどのシナリオを処理するために使用され、LRUはバーストトラフィックを処理するために使用されます。
頻度レコードを処理するスキームでは、hashMapを使用して保存することを考えるかもしれません。各キーは頻度値に対応しています。次に、データ量が特に多い場合、このhashMapも特に大きくなりますか?これから、ブルームフィルターを考えることができます。キーごとに、nバイトを使用してフラグを格納し、キーがセット内にあるかどうかを判断します。原則は、kハッシュ関数を使用して、キーを整数にハッシュすることです。
W-TinyLFUのCount-Min Sketchを使用して訪問頻度を記録します。これもBloomフィルターの変形です。以下に示すように:
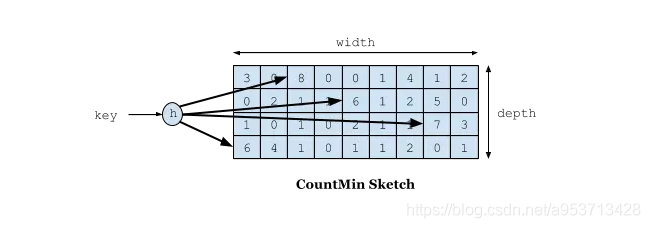
値を記録する必要がある場合は、複数のハッシュアルゴリズムでハッシュしてから、対応するハッシュアルゴリズムのレコードに+1を追加する必要があります。なぜ複数のハッシュアルゴリズムが必要なのですか?これは圧縮アルゴリズムであるため、バイト配列を作成して各データのハッシュ位置を計算するなど、競合が発生する可能性があります。たとえば、Zhang SanとLi Siの両方が同じハッシュ値を持っている可能性があります。たとえば、両方が1の場合、byte [1]の位置は対応する頻度を増やします。ZhangSanは10,000回、Li Siは1バイトにアクセスします[ 1]この場所は10:1です。LiSiのアクセス頻度を取得すると、101として取得されますが、Li Si Mingmingは1回しか訪問しません。この問題を解決するために、複数のハッシュが使用されます。アルゴリズムは、long [] [] 2次元配列の概念として理解できます。たとえば、最初のアルゴリズムではZhang SanとLi Siが競合しますが、2番目と3番目のアルゴリズムでは、アルゴリズムなどのように競合しない可能性が高くなります。競合の確率は約1%で、4つのアルゴリズムが同時に競合する確率は1%の4乗です。このモデルを通じて、Li Siのアクセス率をとるとき、すべてのアルゴリズムの中でLi Siが最も低い頻度を持つ回数をとります。それで、彼の名前はCount-Min Sketchです。
使用する
現在の最新バージョンは次のとおりです。
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>2.6.2</version>
</dependency>
2.1キャッシュ充填戦略
Caffeine Cacheは、手動、同期読み込み、非同期読み込みの3つのキャッシュ充填戦略を提供します。
「1.手動読み込み」
キーを取得するたびに同期関数を指定します。キーが存在しない場合は、この関数を呼び出して値を生成します。
/**
* 手动加载
* @param key
* @return
*/
public Object manulOperator(String key) {
Cache<String, Object> cache = Caffeine.newBuilder()
.expireAfterWrite(1, TimeUnit.SECONDS)
.expireAfterAccess(1, TimeUnit.SECONDS)
.maximumSize(10)
.build();
//如果一个key不存在,那么会进入指定的函数生成value
Object value = cache.get(key, t -> setValue(key).apply(key));
cache.put("hello",value);
//判断是否存在如果不存返回null
Object ifPresent = cache.getIfPresent(key);
//移除一个key
cache.invalidate(key);
return value;
}
public Function<String, Object> setValue(String key){
return t -> key + "value";
}
「2.同期読み込み」
キャッシュを構築するとき、buildメソッドはCacheLoader実装クラスを渡します。loadメソッドを実装し、キーを介して値をロードします。
/**
* 同步加载
* @param key
* @return
*/
public Object syncOperator(String key){
LoadingCache<String, Object> cache = Caffeine.newBuilder()
.maximumSize(100)
.expireAfterWrite(1, TimeUnit.MINUTES)
.build(k -> setValue(key).apply(key));
return cache.get(key);
}
public Function<String, Object> setValue(String key){
return t -> key + "value";
}
「3.非同期読み込み」
AsyncLoadingCacheはLoadingCacheクラスから継承されます。非同期読み込みでは、Executorを使用してメソッドを呼び出し、CompletableFutureを返します。非同期読み込みキャッシュは、反応型プログラミングモデルを使用します。
同期的に呼び出す場合は、CacheLoaderを提供する必要があります。非同期で表現するには、AsyncCacheLoaderを提供し、CompletableFutureを返す必要があります。
/**
* 异步加载
*
* @param key
* @return
*/
public Object asyncOperator(String key){
AsyncLoadingCache<String, Object> cache = Caffeine.newBuilder()
.maximumSize(100)
.expireAfterWrite(1, TimeUnit.MINUTES)
.buildAsync(k -> setAsyncValue(key).get());
return cache.get(key);
}
public CompletableFuture<Object> setAsyncValue(String key){
return CompletableFuture.supplyAsync(() -> {
return key + "value";
});
}
2.2リサイクル戦略
カフェインは、サイズベースのリサイクル、時間ベースのリサイクル、参照ベースのリサイクルという3つのリサイクル戦略を提供します。
「1.サイズに基づく有効期限」
サイズベースのリサイクル戦略には2つの方法があります。1つはキャッシュサイズに基づいており、もう1つは重みに基づいています。
// 根据缓存的计数进行驱逐
LoadingCache<String, Object> cache = Caffeine.newBuilder()
.maximumSize(10000)
.build(key -> function(key));
// 根据缓存的权重来进行驱逐(权重只是用于确定缓存大小,不会用于决定该缓存是否被驱逐)
LoadingCache<String, Object> cache1 = Caffeine.newBuilder()
.maximumWeight(10000)
.weigher(key -> function1(key))
.build(key -> function(key));
maximumWeight与maximumSize不可以同时使用。
「2.時間ベースの有効期限方式」
// 基于固定的到期策略进行退出
LoadingCache<String, Object> cache = Caffeine.newBuilder()
.expireAfterAccess(5, TimeUnit.MINUTES)
.build(key -> function(key));
LoadingCache<String, Object> cache1 = Caffeine.newBuilder()
.expireAfterWrite(10, TimeUnit.MINUTES)
.build(key -> function(key));
// 基于不同的到期策略进行退出
LoadingCache<String, Object> cache2 = Caffeine.newBuilder()
.expireAfter(new Expiry<String, Object>() {
@Override
public long expireAfterCreate(String key, Object value, long currentTime) {
return TimeUnit.SECONDS.toNanos(seconds);
}
@Override
public long expireAfterUpdate(@Nonnull String s, @Nonnull Object o, long l, long l1) {
return 0;
}
@Override
public long expireAfterRead(@Nonnull String s, @Nonnull Object o, long l, long l1) {
return 0;
}
}).build(key -> function(key));
カフェインは3つのタイミング立ち退き戦略を提供します。
- expireAfterAccess(long、TimeUnit):最後のアクセスまたは書き込みの後にタイミングを開始し、指定された時間の後に期限切れになります。キーにアクセスする要求が常にある場合、キャッシュが期限切れになることはありません。
- expireAfterWrite(long、TimeUnit):キャッシュへの最後の書き込み後にタイミングを開始し、指定された時間後に期限切れになります。
- expireAfter(Expiry):自己定義の戦略。有効期限はExpiryによって個別に計算されます。
キャッシュ削除戦略では、遅延削除と定期削除を使用します。これら2つの削除戦略の時間の複雑さは、どちらもO(1)です。
「3.引用ベースの有効期限方法」
Javaの4つの参照型

// 当key和value都没有引用时驱逐缓存
LoadingCache<String, Object> cache = Caffeine.newBuilder()
.weakKeys()
.weakValues()
.build(key -> function(key));
// 当垃圾收集器需要释放内存时驱逐
LoadingCache<String, Object> cache1 = Caffeine.newBuilder()
.softValues()
.build(key -> function(key));
注:AsyncLoadingCacheは、弱参照とソフト参照をサポートしていません。
-
Caffeine.weakKeys():弱参照を使用してキーを格納します。他の場所でキーへの強い参照がない場合、キャッシュはガベージコレクターによってリサイクルされます。ガベージコレクターはIDの等価性のみに依存しているため、キャッシュ全体で、equals()ではなくID(==)の等価性を使用してキーを比較します。
-
Caffeine.weakValues():弱参照を使用して値を格納します。他の場所に値への強い参照がない場合、キャッシュはガベージコレクターによって再利用されます。ガベージコレクターはIDの等価性のみに依存しているため、キャッシュ全体で、equals()ではなくID(==)の等価性を使用してキーを比較します。
-
Caffeine.softValues():ソフト参照を使用して値を格納します。メモリがいっぱいになると、ソフト参照オブジェクトは、最近使用されていない方法でガベージコレクションされます。ソフトリファレンスの使用は、メモリがいっぱいになるまで待機してから再利用する必要があるため、通常、メモリを最大に使用してキャッシュを構成することをお勧めします。softValues()は、equals()の代わりにID(==)を使用して値を比較します。
Caffeine.weakValues()とCaffeine.softValues()を一緒に使用することはできません。
「3.イベントリスナーを削除する」
Cache<String, Object> cache = Caffeine.newBuilder()
.removalListener((String key, Object value, RemovalCause cause) ->
System.out.printf("Key %s was removed (%s)%n", key, cause))
.build();
「4.外部ストレージへの書き込み」
CacheWriterメソッドは、キャッシュ内のすべてのデータをサードパーティに書き込むことができます。
LoadingCache<String, Object> cache2 = Caffeine.newBuilder()
.writer(new CacheWriter<String, Object>() {
@Override public void write(String key, Object value) {
// 写入到外部存储
}
@Override public void delete(String key, Object value, RemovalCause cause) {
// 删除外部存储
}
})
.build(key -> function(key));
複数レベルのキャッシュがある場合でも、この方法は非常に実用的です。
注:CacheWriterは、弱いキーまたはAsyncLoadingCacheと一緒に使用できません。
「5.統計」
Guava Cacheと同じ統計。
Cache<String, Object> cache = Caffeine.newBuilder()
.maximumSize(10_000)
.recordStats()
.build();
Caffeine.recordStats()を使用すると、統計のコレクションに変換でき、CacheStatsはCache.stats()によって返されます。CacheStatsは、次の統計方法を提供します。
- hitRate():キャッシュヒット率を返します
- evictionCount():キャッシュコレクションの数
- averageLoadPenalty():新しい値をロードする平均時間
SpringBootのデフォルトのCache-Caffineキャッシュ
SpringBoot 1.xバージョンのデフォルトのローカルキャッシュはGuava Cacheです。Caffine Cacheは、バージョン2.x(Spring Boot 2.0(spring 5))でGuava Cacheを置き換えました。結局のところ、より優れたキャッシュ除去戦略があります。
SpringBoot2.xバージョンでキャッシュを使用する方法について話しましょう。
依存関係を導入する:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>2.6.2</version>
</dependency>
コメントを追加してキャッシュサポートを有効にする
@EnableCachingアノテーションを追加します。
@SpringBootApplication
@EnableCaching
public class SingleDatabaseApplication {
public static void main(String[] args) {
SpringApplication.run(SingleDatabaseApplication.class, args);
}
}
関連するパラメーターを構成ファイルに挿入する
プロパティファイル
spring.cache.cache-names=cache1
spring.cache.caffeine.spec=initialCapacity=50,maximumSize=500,expireAfterWrite=10s
またはYamlファイル
spring:
cache:
type: caffeine
cache-names:
- userCache
caffeine:
spec: maximumSize=1024,refreshAfterWrite=60s
refreshAfterWrite構成を使用する場合は、CacheLoaderを指定する必要があります。この構成を使用しない場合、このBeanは不要です。前述のように、CacheLoaderはキャッシュマネージャーによって管理されるすべてのキャッシュに関連付けられるため、CacheLoader <Object、Object>として定義する必要があり、自動構成ではすべてのジェネリック型を無視します。
import com.github.benmanes.caffeine.cache.CacheLoader;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @author: rickiyang
* @date: 2019/6/15
* @description:
*/
@Configuration
public class CacheConfig {
/**
* 相当于在构建LoadingCache对象的时候 build()方法中指定过期之后的加载策略方法
* 必须要指定这个Bean,refreshAfterWrite=60s属性才生效
* @return
*/
@Bean
public CacheLoader<String, Object> cacheLoader() {
CacheLoader<String, Object> cacheLoader = new CacheLoader<String, Object>() {
@Override
public Object load(String key) throws Exception {
return null;
}
// 重写这个方法将oldValue值返回回去,进而刷新缓存
@Override
public Object reload(String key, Object oldValue) throws Exception {
return oldValue;
}
};
return cacheLoader;
}
}
カフェインの一般的に使用される構成手順:
- initialCapacity = [integer]:初期キャッシュスペースサイズ
- maximumSize = [long]:キャッシュの最大数
- maximumWeight = [long]:キャッシュの最大の重み
- expireAfterAccess = [duration]:最後の書き込みまたはアクセスから一定時間後に期限切れ
- expireAfterWrite = [duration]:最後の書き込みから一定時間後に期限切れ
- refreshAfterWrite = [duration]:キャッシュが作成されてから、またはキャッシュが最後に更新されてから一定の時間が経過した後に、キャッシュをリフレッシュします
- weakKeys:キーへの弱い参照を開く
- weakValues:値への弱い参照を開く
- softValues:値のソフトリファレンスを開く
- recordStats:統計関数を開発する
注意:
- expireAfterWriteとexpireAfterAccessが同時に存在する場合、expireAfterWriteが優先されます。
- MaximumSizeとmaximumWeightは同時に使用できません
- weakValuesとsoftValuesを同時に使用することはできません
キャッシュアイテムを構成するために構成ファイルを使用すると、一般に使用要件を満たすことができますが、柔軟性はそれほど高くありません。キャッシュアイテムが多い場合、書き込みを行うと構成ファイルが長くなります。したがって、一般に、Beanを使用してCacheインスタンスを初期化することもできます。
次のデモでは、Beanを使用して注入します。
package com.rickiyang.learn.cache;
import com.github.benmanes.caffeine.cache.CacheLoader;
import com.github.benmanes.caffeine.cache.Caffeine;
import org.apache.commons.compress.utils.Lists;
import org.springframework.cache.CacheManager;
import org.springframework.cache.caffeine.CaffeineCache;
import org.springframework.cache.support.SimpleCacheManager;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.TimeUnit;
/**
* @author: rickiyang
* @date: 2019/6/15
* @description:
*/
@Configuration
public class CacheConfig {
/**
* 创建基于Caffeine的Cache Manager
* 初始化一些key存入
* @return
*/
@Bean
@Primary
public CacheManager caffeineCacheManager() {
SimpleCacheManager cacheManager = new SimpleCacheManager();
ArrayList<CaffeineCache> caches = Lists.newArrayList();
List<CacheBean> list = setCacheBean();
for(CacheBean cacheBean : list){
caches.add(new CaffeineCache(cacheBean.getKey(),
Caffeine.newBuilder().recordStats()
.expireAfterWrite(cacheBean.getTtl(), TimeUnit.SECONDS)
.maximumSize(cacheBean.getMaximumSize())
.build()));
}
cacheManager.setCaches(caches);
return cacheManager;
}
/**
* 初始化一些缓存的 key
* @return
*/
private List<CacheBean> setCacheBean(){
List<CacheBean> list = Lists.newArrayList();
CacheBean userCache = new CacheBean();
userCache.setKey("userCache");
userCache.setTtl(60);
userCache.setMaximumSize(10000);
CacheBean deptCache = new CacheBean();
deptCache.setKey("userCache");
deptCache.setTtl(60);
deptCache.setMaximumSize(10000);
list.add(userCache);
list.add(deptCache);
return list;
}
class CacheBean {
private String key;
private long ttl;
private long maximumSize;
public String getKey() {
return key;
}
public void setKey(String key) {
this.key = key;
}
public long getTtl() {
return ttl;
}
public void setTtl(long ttl) {
this.ttl = ttl;
}
public long getMaximumSize() {
return maximumSize;
}
public void setMaximumSize(long maximumSize) {
this.maximumSize = maximumSize;
}
}
}
SimpleCacheManagerをCacheの管理オブジェクトとして作成し、2つのCacheオブジェクトを初期化して、ユーザーキャッシュとdeptタイプのキャッシュをそれぞれ格納しました。もちろん、キャッシュを構築するためのパラメーター設定は比較的簡単であり、使用するときに必要に応じてパラメーターを構成できます。
注釈を使用して、キャッシュを追加、削除、変更、チェックします
@ Cacheable、@ CachePut、@ CacheEvict、およびSpringによって提供されるその他のアノテーションを使用して、カフェインキャッシングを便利に使用できます。
redis、caffeineなどの複数のcahceを使用する場合は、特定のCacheManageを@primaryとして指定する必要があります。@ CacheableアノテーションでcacheManagerが指定されていない場合は、primaryとしてマークされているものが使用されます。
主に5つのキャッシュアノテーションがあります。
- @Cacheableはキャッシュエントリをトリガーします(これは通常、作成と取得のメソッドに配置されます。@ Cacheableアノテーションは、最初にキャッシュがあるかどうかを照会します。キャッシュがある場合はキャッシュを使用します。ない場合は、メソッドが実行されてキャッシュされます)
- @CacheEvictはキャッシュされたエビクション(削除に使用されるメソッド)をトリガーします
- @CachePutはキャッシュを更新し、メソッドの実行には影響しません(変更に使用されるメソッドでは、このアノテーションの下のメソッドは常に実行されます)
- @Cachingは、メソッドの複数のキャッシュを組み合わせます(このアノテーションにより、メソッドは複数のアノテーションを同時に設定できます)
- @CacheConfigいくつかの一般的なキャッシュ関連の構成をクラスレベルで設定します(他のキャッシュと組み合わせて使用されます)
@Cacheableと@CachePutの違いについて説明します。
-
@Cacheable:アノテーション付きメソッドが実行されるかどうかは、Cacheableの条件に依存し、多くの場合、メソッドは実行されない可能性があります。
-
@CachePut:このアノテーションはメソッドの実行に影響を与えません。つまり、構成する条件に関係なく、メソッドが実行され、より頻繁に変更に使用されます。
Cacheableクラスの各メソッドの使用について簡単に説明します。
public @interface Cacheable {
/**
* 要使用的cache的名字
*/
@AliasFor("cacheNames")
String[] value() default {};
/**
* 同value(),决定要使用那个/些缓存
*/
@AliasFor("value")
String[] cacheNames() default {};
/**
* 使用SpEL表达式来设定缓存的key,如果不设置默认方法上所有参数都会作为key的一部分
*/
String key() default "";
/**
* 用来生成key,与key()不可以共用
*/
String keyGenerator() default "";
/**
* 设定要使用的cacheManager,必须先设置好cacheManager的bean,这是使用该bean的名字
*/
String cacheManager() default "";
/**
* 使用cacheResolver来设定使用的缓存,用法同cacheManager,但是与cacheManager不可以同时使用
*/
String cacheResolver() default "";
/**
* 使用SpEL表达式设定出发缓存的条件,在方法执行前生效
*/
String condition() default "";
/**
* 使用SpEL设置出发缓存的条件,这里是方法执行完生效,所以条件中可以有方法执行后的value
*/
String unless() default "";
/**
* 用于同步的,在缓存失效(过期不存在等各种原因)的时候,如果多个线程同时访问被标注的方法
* 则只允许一个线程通过去执行方法
*/
boolean sync() default false;
}
注釈ベースの使用法:
package com.rickiyang.learn.cache;
import com.rickiyang.learn.entity.User;
import org.springframework.cache.annotation.CacheEvict;
import org.springframework.cache.annotation.CachePut;
import org.springframework.cache.annotation.Cacheable;
import org.springframework.stereotype.Service;
/**
* @author: rickiyang
* @date: 2019/6/15
* @description: 本地cache
*/
@Service
public class UserCacheService {
/**
* 查找
* 先查缓存,如果查不到,会查数据库并存入缓存
* @param id
*/
@Cacheable(value = "userCache", key = "#id", sync = true)
public void getUser(long id){
//查找数据库
}
/**
* 更新/保存
* @param user
*/
@CachePut(value = "userCache", key = "#user.id")
public void saveUser(User user){
//todo 保存数据库
}
/**
* 删除
* @param user
*/
@CacheEvict(value = "userCache",key = "#user.id")
public void delUser(User user){
//todo 保存数据库
}
}
アノテーションを使用してキャッシュを操作したくない場合は、SimpleCacheManagerを直接使用してキャッシュキーを取得し、操作することもできます。
上記のキーはspEL式を使用することに注意してください。Spring Cacheには、SpELコンテキストデータが用意されており、次の表はSpringの公式ドキュメントから直接引用しています。
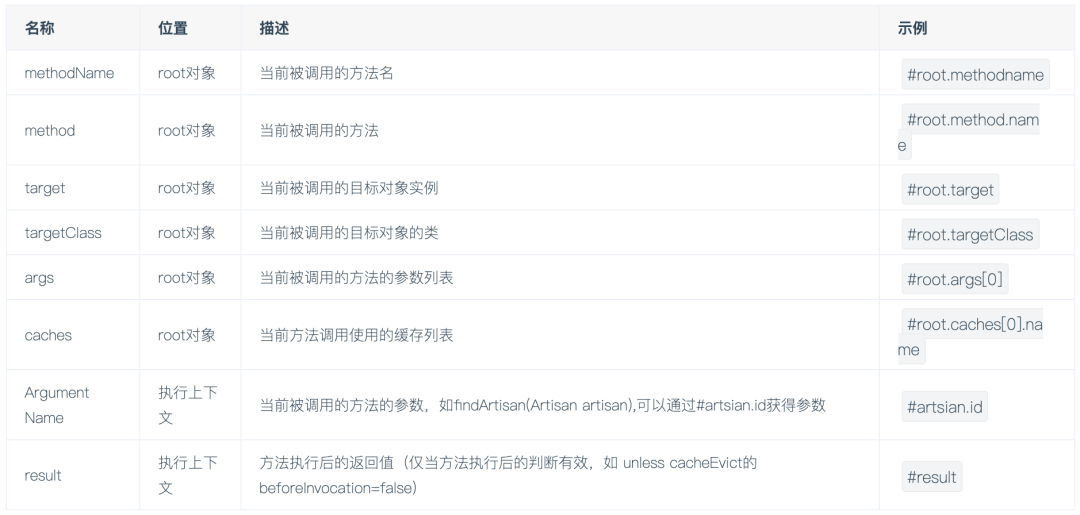
注意:
1.ルートオブジェクトのプロパティをキーとして使用する場合、Springはデフォルトでルートオブジェクトのプロパティを使用するため、「#root」を省略することもできます。といった
@Cacheable(key = "targetClass + methodName +#p0")
2.メソッドパラメータを使用する場合、「#パラメータ名」または「#pパラメータインデックス」を直接使用できます。といった:
@Cacheable(value="userCache", key="#id")
@Cacheable(value="userCache", key="#p0")
SpELはさまざまな演算子を提供します
