一、よく使われるアクティベーション機能
1.シグモイド
- ステッカー
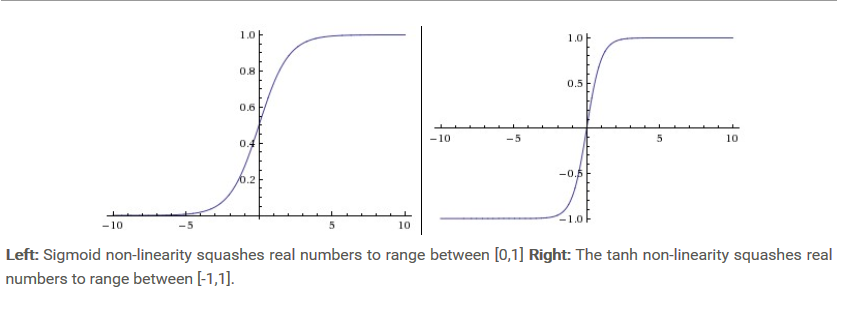
現在、使用量は少なく、主な欠点は次のとおりです。
- 勾配爆発と勾配消失があります。バックプロパゲーションでは勾配が簡単に消え、重みパラメータを初期化すると勾配爆発が発生しやすくなるため、ネットワークはあまり学習しません。
- ゼロ中心ではない場合、考えられる問題は、バックプロパゲーション中に、勾配が常に正または負であり、不適切な動的パラメーターの更新が発生することです。
2.魚
-
ステッカー
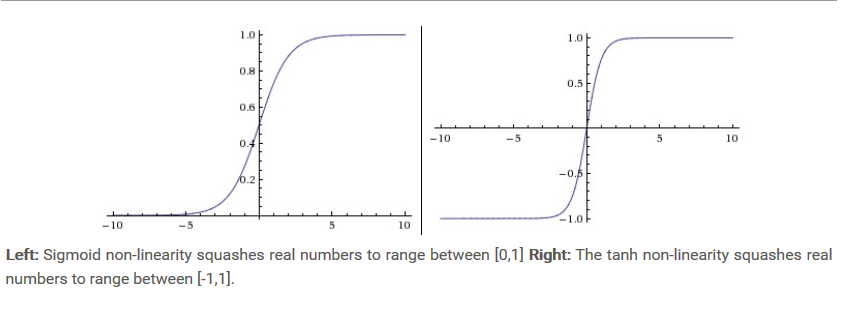
-
勾配爆発と勾配消失の問題はまだ残っていますが、中心はゼロです。シグモイドの2番目の問題はなくなりました。
3. ReLU
-
ステッカー

-
近年、比較的人気の高い起動機能となっています。
長所と短所:
- 確率的勾配降下法の収束率は、シグモイドおよびタンに比べて大幅に加速されていることがわかります。
- 計算コストが少なくなります。
- 勾配が0に変更されている可能性があり、これを更新することはできません。
二、ニューラルネットワークアーキテクチャ
- ニューラルネットワークレイヤーの数については、入力レイヤーは含まれないことに一般的に同意します。
- 過剰適合を恐れているため、小規模なネットワークは使用できません。過剰適合を減らすには、正則化を使用する必要があります。
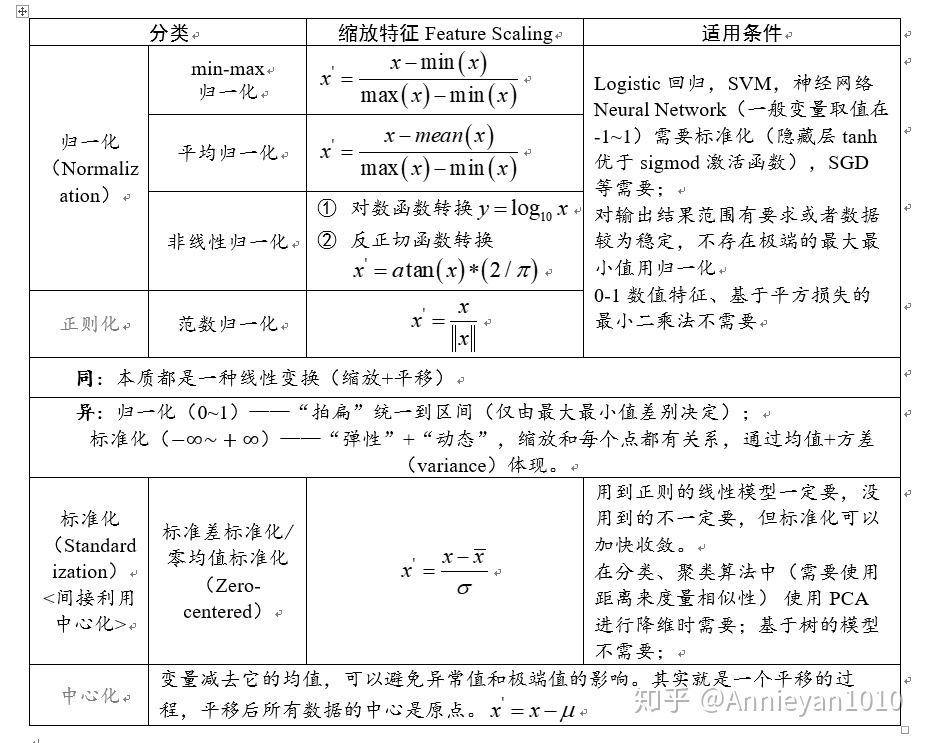
三、データ前処理
- 平均減算:ゼロ中心とは、各次元の平均を減算することです。つまり、データの中心点が原点に変換されます。正規化(正規化)は、データをスケーリングすることです。いくつかの形式があり、1つは0にスケーリングすることです。 〜1の間で、-1〜1にズームすることもできます。標準化とは、平均が0で分散が1であることを意味します。
- SVDとは ??
- ホワイトニング操作は、フィーチャベースのデータに基づいており、各ディメンションは、スケールを正規化するためにフィーチャ値で除算されます。
- 一般的な落とし穴は、データが前処理されている場合、データの平均の計算はトレーニングセットを計算することだけであり、すべてのデータの平均を計算するのではなく、この平均を使用して(トレーニングセット、検証セット、テストセット)で減算することです。 、次にデータセットを減算して除算します。
- この部分は理解されておらず、後続の線形代数の知識が必要です。
四、重みの初期化
- 一般的な問題は次のとおりです。
- 各ニューロンは同じ結果を計算し、勾配計算は逆伝播プロセス中に同じパラメーターを更新するため、すべての重みは0に初期化されますが、これは実行不可能です。負です。
- 初期化の重みは、できるだけ0に近づけたい、つまり、ランダム初期化の重みは可能な限り小さくしたいものです。ただし、数値が小さいほど良いという意味ではありません。たとえば、ニューラルネットワークレイヤーでは、初期の重みが小さすぎると、逆伝播の勾配が小さくなります。
- 推奨されるヒューリスティックは、各ニューロンの重みベクトルを次のように初期化することです。
w = np.random.randn(n) / sqrt(n)ここnで、は入力の数です。 - ReLUアクティベーション機能で推奨される初期化方法は次のとおりです。
w = np.random.randn(n) * sqrt(2.0/n)
- バッチ正規化:堅牢性を高めるために使用され、各ネットワーク層がネットワーク自体に差別化可能な方法で統合する前の前処理としても使用されます。
五、正規化
- ネットワークの過剰適合を防止するために使用
- L2正則化:明示的な特徴選択に焦点を当てていない場合、L2正則化はL1正則化よりも優れています。重要なのは、データを発散させることと、ピークの重みベクトルを厳しく罰することです。
- L1正則化:ノイズの影響を受けず、最も重要なスパースデータのみが使用されます。
- 最大ノルム制約:各ニューロンの重みベクトルサイズに絶対的な上限が課され、制約を課すために投影勾配降下法が使用されます。その魅力的な機能の1つは、学習率が高すぎる場合でも、更新が常に制限されているため、ネットワークが「爆発」しないことです。
- ドロップアウト:非常に効果的な方法です。ドロップアウトは、ニューロンを特定の確率p(ハイパーパラメーター)でアクティブにしておくか、0に設定することで実現できます。(ステッカー)

六、損失関数
-
SVM(テクスチャ)
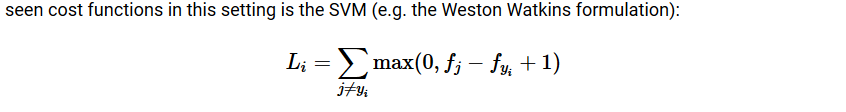
-
ソフトマックス
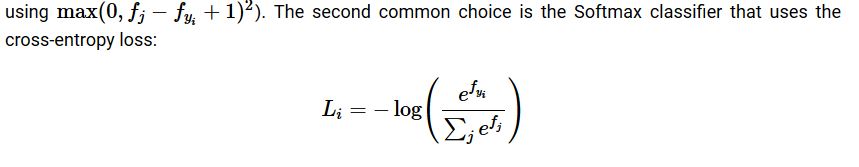
-
L2損失:安定したSoftmaxよりも最適化が難しく、その要件は非常に高く、極端な値は巨大な勾配を引き起こす可能性があるため、その堅牢性は低くなります。