CSVファイルを読み込み、ダブルループのために使用されています
最近では、そのデータを統合し、ダブルサイクルを使用しますが、結果ははるかに満足のいくからです、データの最初のバッチが正常に処理することができ、残りは読んでいないため除くために百万csvファイルのデータ量を、読んで、テストは、問題を発見した後、
ディアンは、問題を発見しました
プロセスデータに、データは、第1の予備抽出IDであります
id_union = [776001, 776002, 776003, 776004, 776005, 776006, 776007, 776008, 776009, 776013, 776016, 776018, 776021,776030, 776031, 776032, 776033, 776034, 776035, 776999]
BISは、データとループ処理を読んで
with open('model_3.csv', 'r') as f:
initial_data = csv.reader(f)
lv_ranks = {}
for node_id in id_union:
lv_ranks['lv_' + str(node_id)] = []
for i in initial_data:
if i[5] == str(node_id):
lv_ranks['lv_' + str(node_id)].append(float(i[6]))
# print(lv_ranks)
第一プリントIDの上記の結果に加えて、キー値であるという問題が発生する理由は、後者は、空である、手掛かりを見つけることができなかった、死の第二のループサイクルは、存在する辞書が存在しないリセット、第二Iありませんシングルサイクルのデータへの二重ループは裁判官がジレンマに巻き込ま問題を、説明していない場合は、Baiduはあなたが望む答えを見つけられませんでした、右に来ることができます
二ディアンが解決しようとし
私は最も簡単なの合理化、および二重循環の過程を再現するために2つのリストが表示されますので、問題は、大量のデータのために二つのリストを、横断するつまるところ、操作中の問題は、対処することは困難であることが見出さ
a = ["1", "2", "3", "4", "5"]
b = [(1, "1"), (2, "2"), (3, "3"), (4, "4"), (5, "5")]
c = {}
for i in a:
c[i] = []
for j in b:
if j[1] == i:
c[i].append(j[0])
print(c)
私は漠然と、問題の原因を推測して上記のコードの印刷の結果は、試しに続いて、予想通り
with open('model_3_预测1月.csv', 'r') as f:
initial_data = csv.reader(f)
initial_data = list(initial_data)
lv_ranks = {}
for node_id in id_union:
lv_ranks['lv_' + str(node_id)] = []
for i in initial_data:
if i[5] == str(node_id):
lv_ranks['lv_' + str(node_id)].append(float(i[6]))
# print(lv_ranks)
私はその後、私はその理由を知らない、本当に問題を解決するため、リストのリストに変換し、csvファイルに上記の結果を読み取ります
水と問題の概要
変換タイプは、ここに関与読み取りリストを説明したcsvファイルタイプの結果ではありませんが、それは、反復型である必要があり、読み取り結果のデータ・タイプCSVの下に印刷されました 
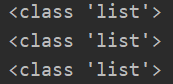
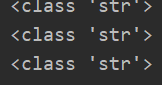
見かけ上のデータ型のリストが、トラバースされない、データの各行がリストされ、リストタイプは、再び各データ列に存在している、この質問のニーズは完全な二重にリストの型に変換しますサイクル。
CSVのデータ型は、二次サイクルであるか、またはもつれの数時間後に、読む前に循環一貫性のないデータ型を入力することはできませんので、このような操作は、私は理解していなかった、それがあるべきすべき理由のために、問題を解決するために考えることができます