まず、識字
この記事では
、次の問題を説明するのに役立ちます:
- 何スパーク糸上の?
- 動作原理pysparkアプリケーションは何ですか?
- どのようにpysparkアプリケーション糸を実行していますか?
第二に、実際の
- Python環境パッケージ
cd path_to_python
次のパッケージのpythonディレクトリ、そうでない場合はパス全体が(パスのpythonが配置されている)パックされます入力して、解凍した後の時間に、パスの前に長いのpythonがあること*注、することができ、正しく解析できませんエラー
zip -r path_to_pythonzip/python_user.zip ./*
- HDFSにアップロードPython環境
hadoop fs -put python_user.zip
- 修正スパークプロフィール
火花defualts.config設定ファイルには、中に各作業ノード環境に自動的に、Pythonのバンドルを火花提出するように、というのpythonをアップロードします。cp spark-defaults.conf spark-user.conf # 修改相关配置 spark.yarn.dist.archives path_to_hdfs/python_user.zip#python
*最後#python面が削除することはできません、彼はおそらくZIP伸張後のパスでのpythonのパスを見つけることに注意してください、その後のpythonという名前。これは、コンフィギュレーション・ファイルpysparkのpythonは、右を見つけることができますが関与します

- 提出されたスクリプトを変更します
#!bin/bash spark-submit --master yarn \ --driver-memory 4G --executor-memory 12G \ --properties-file conf/spark-user.conf \ --py-files other_dependence.py main.py
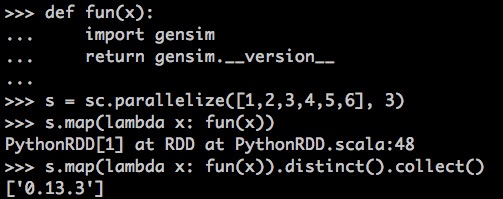
第三に、営業成績
単純にそれを実行し、gensimバージョン出力Python環境