ビッグデータのオフライン分析シナリオ
解析および処理に大量のデータを指す、得られたデータは、データ・アプリケーションのための次のステップが形成されています。処理のオフライン処理は時間が重要ではなく、処理する大量のデータ、通常MRまたはスパークジョブまたはジョブSQLの実施を通じて、より多くのストレージリソースを占有計算します。HDFS分散ストレージデータベースエンジンへのソフトウェアのオフライン分析システムアーキテクチャはMapReduceのハイブに基づいて点火SparkSQLに基づいて算出されます。

大型リアルタイムデータ取得シーン
これは、ビジネス全体のリソース使用率のリアルタイム分析を強化するために、高帯域幅、マルチプロトコルオブジェクト・ストレージ・サービスと組み合わせ、業界で主流のビジネスプラットフォームのリアルタイム分析をサポートするために弾性膨張、低遅延、高スループット、高性能コンピューティングリソースを提供します。
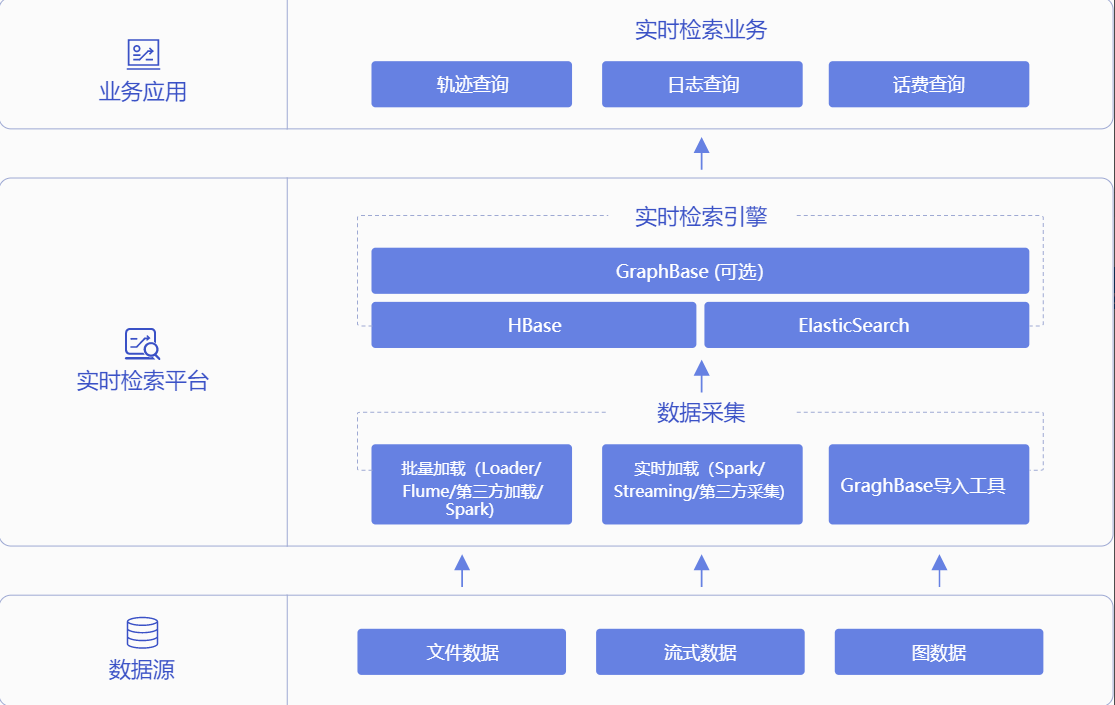
大規模なシーンを処理するリアルタイム・データ・ストリーム
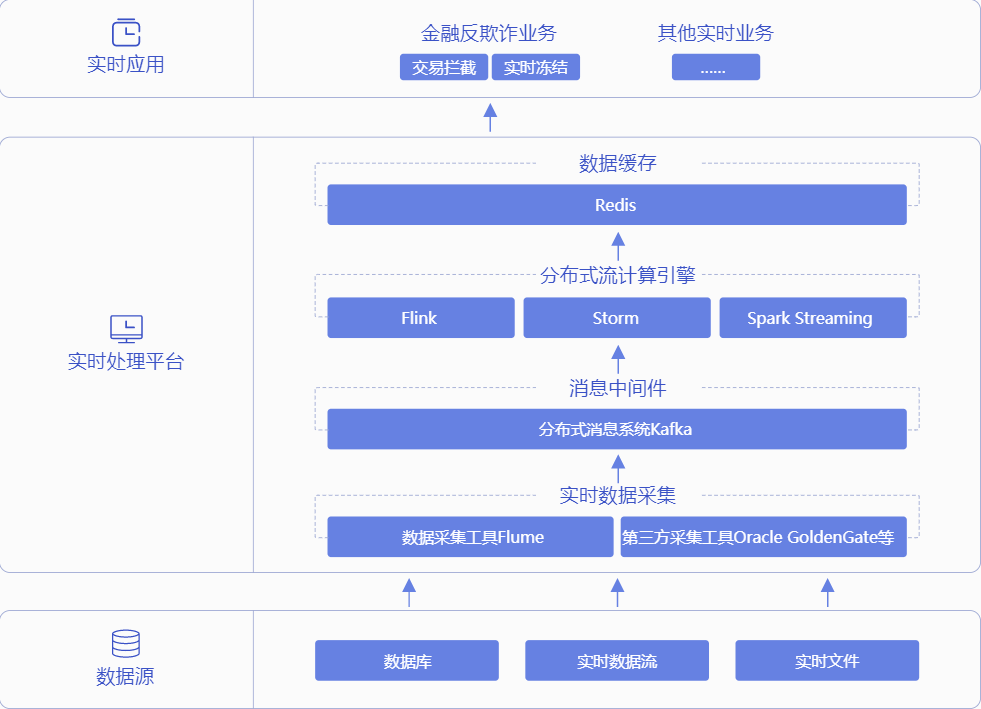
多くの場合、迅速な分析のために、リアルタイムのデータソースを参照して、シーンはすぐに次のアクションをトリガーします。リアルタイムのデータ分析や要求の速度を処理し、該当しない巨大な規模、高いCPUおよびメモリ要件が、通常はデータを処理し、データ、ストレージを要求しません。リアルタイム処理は、通常は嵐によって、達成するためにストリーミングまたはFLINKタスクをスパーク。分散メッセージは、データ処理をストリーミングエンジンFLINK、嵐、スパークを計算リアルタイム分散ストリームカフカにデータ取得システムを介して送信され、その結果、上部Redisのために格納されるキャッシュサービスを提供します。
[雲]から取られたHuawei社Kunpeng @