1.概要
翻訳要約:私の基本的な論文は、「リカレントニューラルネットワークによる標識セグメント化されていないシーケンスデータコネ時間的分類」に基づいています。密接に関連し、RNNを知っているし、(セグメント化されていない)を分割するためには適用されませんCTCに関連したルック論文のトピックを予測するためのシーケンス、ポイント。
CTCに(コネ時間的分類)の前に、のHMM(隠れマルコフモデル隠れマルコフモデル)のCRF(条件付確率の条件付きランダムフィールド)と関連する変異体は、この方法は、主に、標識配列のために使用されます。これらの方法の1つは、標的認識の多くの知識を必要とし、そして第二に、そのようなHMMとして独立したHMMの仮定第三に、の分布として仮定の数が訓練することができ、標準は、適切なシーケンスがない場合であっても、そこにあります。
HMM-RNNモデルは、長いシーケンスは、データ構造を処理することができます。HMMセグメントの配列は、自動である。しかし、その後、スイッチングネットワークは、シーケンス全体の特性の効果的な使用がない、タグ配列に分類されます。
CTCのトレーニングデータは、シーケンス全体での直接的な役割の出力を後処理、セグメンテーションを事前にする必要はありません。CTCは、タグのすべての可能な入力シーケンスの確率分布に基づいてネットワークとして出力されます。
2.Temporal分類
X:入力空間。M次元の実数ベクトル
Z:オブジェクト空間、Z = L *。ラベルLのアルファベットに基づいてシーケンスのセット。
L:L *(S)要素には、タグ配列の供給源です。
S:得られたD(X、Z)の固定された分布に基づいて、サンプルセットをトレーニングします。サンプルS(X、Z)のそれぞれに。標的配列Z =(Z1、Z2、... 、ZU)、 入力シーケンスX =(X1、X2、... 、XT、)。zは長さTがUをxは長さ未満であることがある、すなわち、U <= T. すなわち、入力とターゲットの長さは矛盾することができます。
H:X→Z関数は、関数は、分類の時間として定義されます。
S`:分布D(X、Z)の固定された部分が、Sの互いに素なセット。
ED(P、Q):Qシーケンス編集距離pの配列、すなわち、P qは必須挿入、置換、欠失の最小数となります。
以下は、キー、ラベル・エラー・レート(LER)である : 手段LER時間(時間区分)が目標分類Sにおいて生成される時間と目標と定義されます的编辑距离(ED),这句话我看着也饶,编辑距离是衡量两者之间的,但下面的公式却只写了一个参数。 Z is the total number of target labels in S。
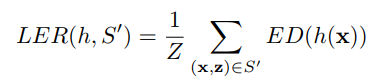
3.Connectionist時間的分類
この章では、RNNの出力にCTCに適用する方法を説明します。
重要なステップは、タグ配列の条件付き確率分布に基づいてネットワークの出力を変換することです。その後、ネットワークは、入力シーケンスが最も可能性の高いラベルで選択することができます。
ラベルにネットワークから出力された3.1
X:ネットワーク入力、T.の長さは、上述したように Xは、m次元です。
Y:ネットワーク出力、yはn次元です。wは重みです。Nは、yの重み関数を用いて> x軸を規定します。
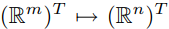
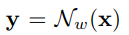
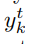 :Kは時刻tにおける活性化された出力部として定義されます。また、時刻tにおけるラベルkを観察する可能性として解釈さ(確率)
:Kは時刻tにおける活性化された出力部として定義されます。また、時刻tにおけるラベルkを観察する可能性として解釈さ(確率)
'L' = L∪{空白}:賃金以上のブランクラベル。
π: 'L'要素の内部。各要素はパスです。

パス(ループ経路ネットワークの複数)の確率は、各観察タグの確率の積の種々の時間(Tの合計長さ)に等しくなる(例えば、予測されるシーケンスABC、確率等しい確率B、 Cの確率)、配列の長さTは、確率はT時間を掛けています。前記出力は、異なる時間にネットワークの状態が独立であると仮定されます
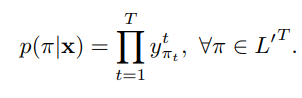
B:この変換のための多くの機能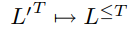 。簡単な方法を用いて、紙、及びそのようなB空白ラベルの繰り返し除去( - AB-)= B (-Aa - -abb)= AAB
。簡単な方法を用いて、紙、及びそのようなB空白ラベルの繰り返し除去( - AB-)= B (-Aa - -abb)= AAB
xにラベルLの最終入力のBにより各パスの機能を処理し、次いで、確率P(L | X)は、各経路πの確率です。

分類子の3.2建設
上記式を取得した後、我々は、入力シーケンスのために知ることができ、出力は最高確率は、次式を識別するために取られるべきです。
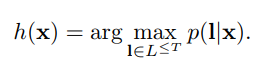
しかし、上記の式を計算するための良い方法を見つけることができませんでした。以下は、2近似法を説明します。
第一の方法(ベストパス法):最尤パス最も可能性の高いラベルを有するように、すなわち、以下の式に対応すること:
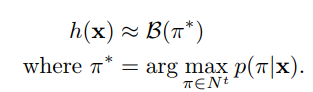
第二の方法は、メソッドクエリプレフィックス(プレフィックス検索復号化)です。そして、プレフィクスの最大数は、妥当な時間で計算することができ、出力がスパイク状プロファイルである場合は特に、入力系列長として指数関数的に増加し、そのことは非常に困難であろう。しかし、我々は発見的方法を見つけます。
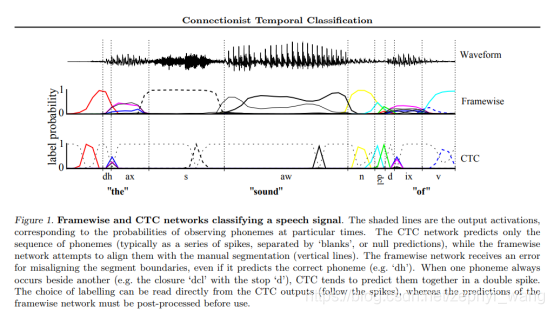
図は、プレフィックス方式である、あなたは、画像内のテキストを見ることができます。

リマインダーに由来図ヒューリスティックの方法は、ブランクの一連によって形成されたCTC出力ネットワークは、予測可能なスパイクを分割します。フラグメントは最初から最後までがある場合、私たちは、セクションを形成し、これらのブランク分割出力を使用します。もちろん、空白のラベルの選択は、一定の確率しきい値に基づいています。我々は、彼らが最終的に一緒にラベルの究極の合成を入れて、これらのフラグメント最も可能性の高い独立したラベルを計算します。
非常によく、このヒューリスティック実行で実際には、接頭辞のクエリメソッド、およびベストパス法よりも良いです。しかし、この方法はまた、同じラベルの両側のセグメント境界として、いくつかの場合には失敗した両方の非常に弱い予測です。
ニューラルネットワークを訓練4
上述した一連のパスの確率予測ラベルを記載しています。そして、プレフィックス検索方法を用いて近似することができます。これらのプレフィックスの反復加算パスが逆再帰パラメータ前に、有効であることが計算されてもよいです。
4.1 CTC前に逆アルゴリズムへ

メイン式より数を取得します。
式1:

式2:
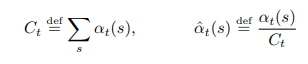
式3:目標は、最大値算出式、すなわち、最も高い確率です。プラス対数関数。
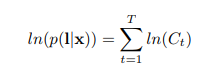
4.2最尤計算
CTCの目標は、確率p(L | X)を最大化することである。それは、次の値を最小化することです。
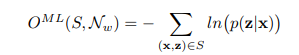
アルゴリズムのこの部分は、それが、最終的な式は次のようにされ、(s)が反転されるフォワードβT(単数または複数)のある元の紙を表示することで、より多くのです。これは、勾配降下法の適用を可能にします。
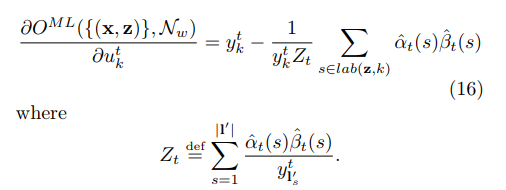
5.実験結果
編集距離尺度、CTC最高の性能を持つ各モデルの結果を以下の。
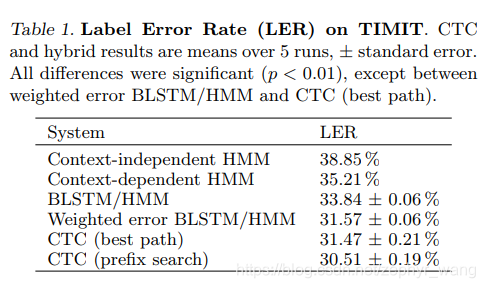
CTCは、それがこれらの2つの問題の特性を有していると判断し、即ち、必要な配列セグメント場合、CTCはサポートしていない、第二には、CTCを正確に内部ラベルとの間の関係を記述することはできません。
6.tf.nn.ctc_loss
:このメソッド持ってTensorflow
https://tensorflow.google.cn/versions/r1.15/api_docs/python/tf/nn/ctc_lossを
方法の説明:.計算CTC(コネ時間的分類)損失
方法は戻り値を返し:
。。A-Dを1テンソルフロート、サイズ[BATCH]、負の対数確率を含む
可視戻り値は、確率の負の対数です。それは、(| x)は、P(L -ln必要があります )。
6.1エラーctc_lossエラーは、「いいえ有効なパスが見つかりません。」原因:
予測できない入力タグの長さよりも長さ(1)大きい、ことができない計算喪失;
(2)そのような誤差は0.1、0.01となり、実行することができ、レートLEARNING_RATE学習または設定が高すぎます。
