1、専門の治療システムの問題(プロシステムの誕生がスパークしている前に、本明細書で言及されます)
- 反復作業:分散SQLエンジンとして、機械学習エンジンが同じパラレル重合を行う必要があります。ドメインごとに別々のコンピューティング・システムがどのように並列コンピューティングの重合を解決する必要があります。この性能は、割り当てや耐障害性に繰り返されます。これは、多くのプロのコンピューティング・システムの潜在的な問題です。
- コンピューティングの組み合わせを実行する際に:ほとんどの場合、データを計算し、大量のデータが非常に大きい、およびコンピューティングの組み合わせからパイプラインの複数を介して、典型的には、計算エンジンを最終的な計算に達する前に、この中間体の多くを生成しますデータ、現在のソリューションは、出力に再現、安定したストレージシステムにデータを、複数のコンピューティング・エンジン間で共有されるデータです。ここでの問題は、膨大な量のデータを移動させることは重い代償です。価格は通常何倍、通常の計算です。
- 計算範囲の制限:アプリケーションは、計算モデルの特殊なコンピューティング・システムに適用されない場合、ユーザーはシステムは、アプリケーションが使用することを可能にする、または新しいオペレーティングシステム用のアプリケーションを書き換えることで変更する必要があります。簡単な例として、反復計算の大規模な数の機械学習のアプリケーションでは、HadoopのMapReduceの計算モデルは適用されません。
- リソースの共有:動的共有リソース応用アプリケーション・リソースの間に、コンピューティング・エンジンの大半は、彼らがマシンの同じセットを持っていることを前提とし、ので、別の計算エンジンとの間に非常に困難です。
- 管理では:統一されたシステム容量の包括的なセットと比較して、別の支払システムの管理と展開、ワークロードは、あなたはまた、彼らのAPIを学ぶ必要があると各モデルシステムのために計算され、それよりも、重要です。
上記の制限に基づいて、スパークは大幅な利益、特に複雑なマルチユーザ・コンピューティング環境では、ユーザビリティとパフォーマンスの両方から、クラスタコンピューティングのための統一された抽象化として、誕生しました。
図2に示すように、弾性分散データはRDDを設定します
この問題を解決するために、アカウントに効率、フォールトトレランスを取って、RDDは、並列コンピューティングの広い範囲のための抽象化を提供します。これは、単純な延長のMapReduceモデルです。繰り返し、インタラクティブ・コンピューティングのために、そのようなMapReduceのストリーミングクエリのワークロードは、適用されない大きな違いが見えるかもしれませんが、彼らはただのMapReduceに共通の特性の欠如必要があります:相間の効率的なデータ共有並列コンピューティングを。したがって、抽象クラスのMapReduceと算術演算と共有効率的なデータは、作業負荷を効率的に発現させることができるようになり、キーは、既存の専門家のコンピューティングシステムの最適化です。
フォールトトレラント処理クラスタモデルの前には何?
ドライアドのMapReduceのいずれかのために、それらは、障害回復のための再生部DAGにそれらを可能にする計算されたDAG(有向非巡回グラフ)に組み立てられます。しかし、個々の間の計算のために、例えば反復計算、複製依存性記憶機能に加えて、分散ファイルシステムを配布した、抽象モデルは、ストレージを提供しません。これは大幅に起因するネットワークをもたらす間でのデータの複製にオーバーヘッドが増加します。これに対し、RDDSがフォールトトレラントメモリの抽象化され、それは重複を避けることができます。各RDDは、それが操作することによって生成され、これらの操作を効率的にこのグラフによれば、再計算することができるデータを回復するために障害が発生した場合に、同様のバッチモードで、グラフを形成する記録されています。もちろん、比較的粗粒でなければなりませんRDD操作を作成するための前提条件でもあり、それは、オペレータがデータ要素の多くに適用されると言うことです。これは、大幅に効率を向上させ、ネットワークを介してデータの複製を避けることができます。
しかし、なぜ唯一の効率的なデータ共有を提供することにより、大幅に消費電力にそれを計算改善できますか?2点を説明するためのドキュメント:
- ビューの最初に、表情豊かポイント
RDDSであれば、システムを効率的に行うことができる一定の遅延を許容することができるように、任意の分散システムをシミュレートすることができます。その理由は、強化されたデータ共有効率一旦、バルクMapReduceの並列同期並列計算モデルをシミュレートすることが可能である、ということである、唯一の欠点は、各計算ステップのMapReduce、典型的には最大50-100msの間に一定の遅延があることです。
- システムからの第2の観点、
通常RDDSとは異なり、ほとんどのクラスタコンピューティングアプリケーションのリソースのボトルネックを最適化するのに十分な制御を与えるMapReduceは、ネットワーク及びストレージリソースのこれらのボトルネックは、特にI / Oを指します これらのリソースは、通常、実行時間を導いたのみの対照(例:制御データが配置される位置)され、同じリソースに匹敵する一般専門システム性能を投与することができます。
ほとんどのプロのデータモデルを実現し、使用中の新しいプログラミングモデル今日RDDSにより、豊富な機能を提供することにより、耐障害性と効率的なパフォーマンスを確保するために組み合わせることができますすることができます。ここで、組成物は、上記複数のMapReduceの間の遅延で言及されていると述べました。複数のMapReduceを実行するパイプラインを形成するようにそれを理解することができます。
モデルRDDSに基づいて3、
- 反復アルゴリズム:RDDSは、例えばHaLoopとツイスターのために、そのようなプレゲル、反復のMapReduceモデルとしてモデル、様々な捕捉GraphLabとPowerGraphモデルのバージョンを決定することができます。
- クエリに関連付けられている:MapReduceは、この点に固有の欠点、彼のフォールトトレラントモデルで重要な性能を有しています。しかしながら、多くの一般的なデータベースエンジン特性RDD計算の実現に、例えば、このサメシステムに基づいて、列指向性データ処理は、また、完全なフォールトトレランスを提供することができる、短いクエリと長いクエリすることができ、およびRDDに構成呼び出すことができそのような機械学習などの複雑な解析機能、。
- MapReduceは:それは効率的DAG(有向非巡回グラフ)一般的なアプリケーション、例えばDryadLINQに基づいのMapReduceプログラムなどを操作できるようにRDDSは、マップリデュースのスーパーセットを提供します。
- ストリーム処理:
- データ記録はしばしば後ろに達しているが、それらは記録に達したときに長いライフサイクルプロセスオペレータは、記録されたデータが到達するように後方に廃棄されるモデルオペレータ、すなわち、前の連続フロープロセスを使用して大規模なデータで起こります。フォールトトレランスは、コピーに制限したり、高価な場合、またはも長い回復時間を消費します。
- この問題に対処するために、D-ストリームストリーム処理モデル、RDDにおける中間状態に格納されたバッチを実行短い、決定論的計算、一連のようなフロー計算を導入する火花。それをコピーせずに回復が、RDD関与依存関係グラフに沿って回復によって並列化します。また、投機的実行のバックアップコピーは、出遅れの遅い作業を容易にします。実行するために、個別のタスクとして動作しますが、遅延を増加させていますが、この遅延は、サブ秒で、また以前のスタンドアロンシステムのパフォーマンスと同じ達し、100個のノードまで拡張することができます。その強い反発が大きいクラスタ特性を処理するための第1のストリーム処理モデルの一つとなっています。RDDSに基づいて、同時にまた、バッチおよび対話型のクエリを結合するための強力な方法でアプリケーションを可能にします。
- 関節モデル
多関節処理モデルを必要とする用途において、取り扱いが難しい既存の専門システム、スパークができます。例えば、多くのワークフロープロセスは、過去のデータと結合する必要があります。RDDSにより、バッチ処理とストリーム処理を再び同じプログラムで発現させてもよいし、バッチモードとストリーム処理モデルにおけるモデル間でのデータの共有とフォールトトレランス。通常フロー状態ニーズにアドホッククエリをストリーミング以上があります。スパークストリーミングこの機能を提供する、D-ストリームにおけるRDDS照会する静的データと同じであってもよいです。バッチ処理は、多くの場合、データのセットを抽出するためにSQLを使用するように、例えば、の組み合わせを必要とし、その後、このデータセットのトレーニング機械学習モデルは、そのモデルを照会します。この理由は、外部ファイルシステムを介してシステム間でデータを共有する必要があり、そのような組合せを処理するときには有効ではないプロ前に、上記処理システムと一致して、分散ファイル・システムは、IO処理性能を制限します。そしてRDDベースのシステムで、この組み合わせは、パイプライン実行は、外部ファイルシステムのIOを必要とせずに同じエンジンで完了することができます。
4.結果が要約されています
- スパークで使用される抽象データモデルはRDDSです。ユニバーサルRDDSが、しかし、注文はまだ比較的小さなスパークコード34000行のScala言語です。重要なのは、プロのモデルスパークがあることを彼らの独立したモデルよりもはるかに小さいの上に構築されました。プレゲルと符号の反復MapReduceのわずか数百行、個別のストリーム8000は、SQLの12000スパーク。スパークよりも小さい大きさの順に構築されたこれらのシステムは、その独立を達成し、かつ豊富な混合モデル方式をサポートしており、プロのシステムはまだ性能に匹敵することができます。
- 符号量とサイズをスパークし、それに3つのシステムの性能比較や人気の専門的な処理システムを構築
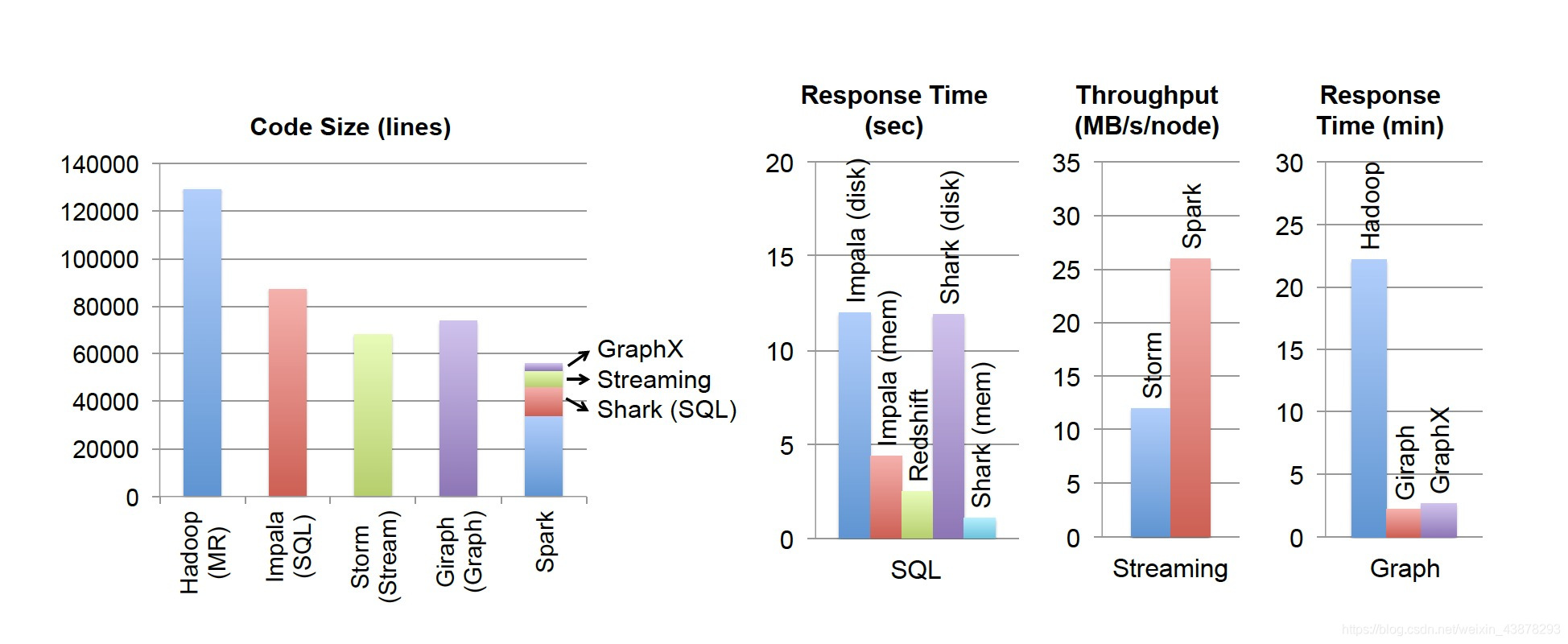
図との比較。1スパーク、他の業務用システム - また、スパークは、複雑な処理機能のRDDSを実装するために使用される一般的な技術を含んでいます。前述のように、RDDモデルは、任意の分散システムをシミュレートし、MapReduceの方式よりも効果的であることができます。RDDインタフェースは、アプリケーションが、プロのシステムの効果を一致させるために、ボトルネックリソースのクラスタの制御を取ることができるようにします。依然として効率的な自動フェイルオーバーおよびそれらの組み合わせがあります。
注:オリジナルの論文からの写真。