(A)に基づいて、LZ77アルゴリズムとハフマンファイル圧縮アルゴリズム
1.データ圧縮の概念
データ圧縮手段 有用な情報を失うことなく、収納スペースを削減し、その輸送、貯蔵及び処理効率を向上させる、またはデータ冗長性とストレージスペースを減らすために、特定のアルゴリズムに従ってデータを再編成するためにデータの量を減らします 技術的な方法
2.なぜあなたは圧縮が必要なのです
- パックドデータ記憶容量、ストレージ容量を削減
- 通信効率を向上させ、データ伝送速度を向上させ、帯域幅の消費を削減することができます
- データ保護の暗号化、送信中のデータのセキュリティを強化
3.分類圧縮
有损压缩
非可逆圧縮は、圧縮中に失われたいくつかの情報を可能にする画像や音響特性の特定の周波数成分に対するヒト非感受性の使用、完全に元のデータを復元するが、理解の上、元の画像の一部が失われていないが影响缩小、しかしはるかに大きな圧縮率と引き換えに、データを再構築するために圧縮されたデータの使用を参照して元のデータが異なっていると再構築が、不影响情報を誤解する人元の式の情報。
无损压缩
データファイルの特定の符号化フォーマットで再編成は、圧縮されたファイルは圧縮され、完全に元のファイルに削減することができる全相同的格式、それがデジタルイメージのため、ファイルの内容には影響しません、不会使图像细节有任何损失
4. ZIP圧縮歴史
1977年、2人のイスラエル人ジェイコブ・ジブとアブラハム・レンペル、紙「AユニバーサルアルゴリズムforSequentialデータ圧縮」を出版 、 汎用のデータ圧縮アルゴリズムを、いわゆる汎用圧縮アルゴリズムは、データがないことを圧縮アルゴリズムを指しリミットのどのようなタイプ、アルゴリズムであるコアの今日の無損失データ圧縮のほとんどの基礎二人の科学者を記念するために、アルゴリズムは、それらがLZ78と呼ばれる同様のアルゴリズムを、引き上げ年後、LZ77として知られています。ZIP LZ77このアルゴリズムは進化の考えに基づいているが、圧縮は、これまで困難であるまで、ZIP LZ77符号化と圧縮後の結果が続いています。LZ77、たくさんのバリエーションに基づいLZ78アルゴリズムでは、基本的には、このようなLZW、LZO、LZMA、LZSS、として、LZで始まる LZR、LZB、LZH、LZC、LZT、LZMW、LZJ、LZFG ようにと。
カッツは、ZIPフィルの著者です、
彼は伝説の悲劇的なオープンソースコミュニティを持っていると考えます。フィル・カッツは、DOS時代に有名になった、スピードの時代が非常に遅い、速いハードウェアのプログラマであるフィル・
カッツは、インターネットは、何の外観がないWWWの事実は、当然のことながら、ブラウザ少ない1990以上でない場合は、インターネットはそれをやっていました?基本的なネットワークは、ノック各種コマンドに似ているので、実際には、また、チャットすることができ、フォーラム、転送ファイルなしで
圧縮、スローデッドスローその後、確かに死んだので、圧縮は、その時代に非常に重要です。そこ営利企業は、あなたがその時代に速くチャットすることができ、ARCと呼ばれる圧縮ソフトウェアを提供していましたが、賃金に、フィル・
カッツは、その後、私は自由でなく、互換性だけでなく、PKARC圧縮ツールを書いて、不快に感じましたARCは、ユーザーは、同社が自然に不幸なことに、ARCをPKARCを使用しているので、フィル・
カッツは、知的財産権を伴うので、フィル・カッツの刑務所の結果、上のことを言って、訴えました。牛は、牛で
越えて全体アルゴリズムはARCの決定に回帰さ格闘あり、思考のための刑務所だけで無料ではない、PKZIPと呼ばれる、全体のうちの2週間で、そこにあるだけでなく、オープンソース、直接刑務所にアルゴリズムは同じではありませんので、ソースコードを公開し、知的財産権に関連していない、ZIPの人気ので、しかし、フィル・
この人は内側からペニーを獲得、あるいは疲弊、理由はあまりにも多くを飲んで、多くはなかったカッツ理由、彼はモーテルの部屋で死亡した2000年、インチ なくなっヒーロー、ASCIIコードは、我々は2バイト文字の始まりを見ることができ、精神が生き続け、そして今、私たちはUEとのZIPファイルを開くには、2本のPKです

5. GZIP圧縮アルゴリズムの作品
GZIP圧縮アルゴリズムは、2つの段階を経ています、第一段階は、格納されたデータの効率的な圧縮を達成するために、バイトを完成ためにされた圧縮データに圧縮の思想第一段階をハフマン符号化を使用して、圧縮、第二相の文脈で変更LZ77圧縮アルゴリズム繰り返しステートメントを使用し。
5.1 LZ77圧縮アルゴリズム
LZ77ある長い文字列(またフレーズとも呼ばれる)印は、圧縮の目的を達成するように、小さなマーカーの代わりに辞書内の語句と、ショートに符号化することを辞書ベースのアルゴリズム。
LZ77これは、使用している前向缓冲区と一个滑动窗口、辞書を維持します。それはデータの前部は、最初のフレーズによってバッファに一度データの前に、バッファにロードされ、それは、スライディングウィンドウの移動に伴って、辞書の内容をスライディング・ウィンドウに移動し、辞書の一部となりますそれは常に、それが新しい辞書、サイド圧縮を変化させていることを意味し、更新されます。
辞書は、確立されたと仮定フレーズマークにそれをコードする定期的なフレーズがあるかどうかを検索、辞書にフレーズが繰り返し発生しているかどうかを確認し、それぞれが文字を読んで、あなたが先にスキャンします。フレーズマーカーは、3つの部分から構成:スライディングウィンドウは、最初のシンボルに一致するようにバッファの終わりの前に、シンボルの数と一致(マッチの先頭から文字の開始前)のオフセット- (O FFセット、な長さ、 nextChar) 。
一致するものが見つからない、非マッチングシンボルの符号化シンボルに変換します。シンボルマークのみがシンボル自体が含まれ、非圧縮プロセスはありません。nがシンボルを符号化してNスライディングウィンドウの端からのシンボルは、使用前及びシンボルの数を同じ緩衝液でそれらを置換除去されるであろう対応するマーカーを、生成後。その後、前方にバッファを補充します。
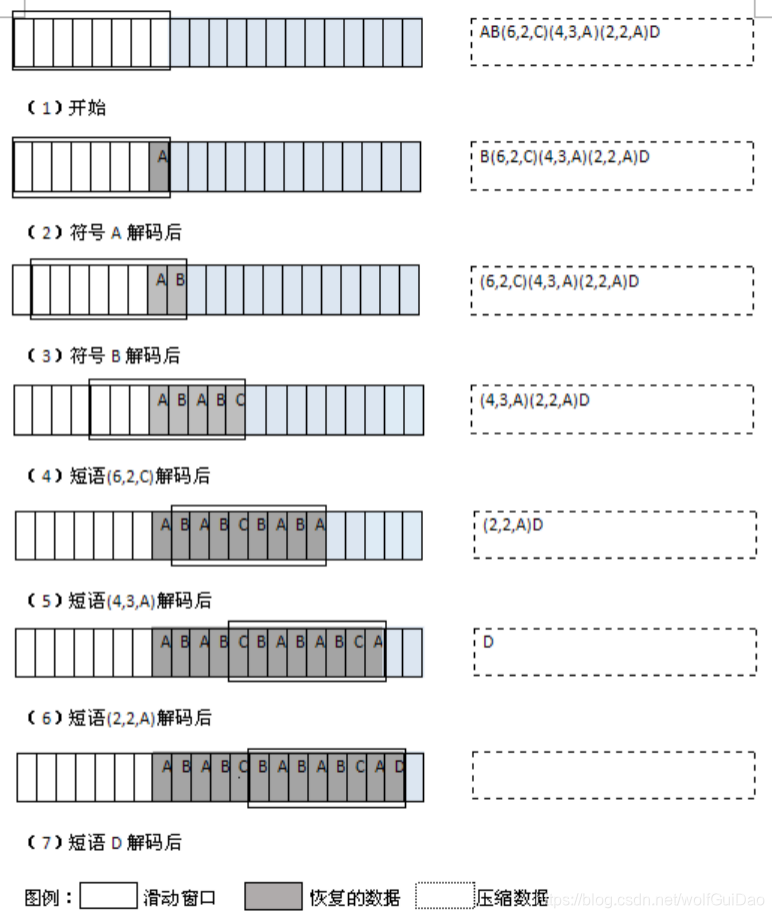
次の図に示すLZ77圧縮処理、スライディングウィンドウサイズを想定すると、順方向バッファのサイズは4バイトで、8バイトです。

各マーカをデコードする場合、マーカーは、スライディングウィンドウにコピーされた文字にエンコード。フレーズマーカーは、フレーズの指定した長さのためにそこにいながら、スライディングウィンドウで適切なオフセットを見つけることがあるたびに。マーク記号があるたびに、それはシンボル保存されたタグを生成します。
LZ77の5.2 GZIP思考
GZIPアルゴリズムではLZ77アルゴリズムの考え方にも使用されているが、それは主に、フレーズマーカーを改善するため、改善されました:唯一の“长 度+距离”的二元组表情がでていると一致するように言われます查找缓冲区中进行的,即字典。

注:查找缓冲区的数据スキャンされた、建立的字典中的数据、第一のバッファは、圧縮したデータであります
最初のバイトの現在の最初のバッファは、文字行うには、「r」は、ルックアップバッファの最初の連続文字数によってバッファの中で最も長い文字列にマッチする、開始文字として「R」を見つけることです。我々は後者を選んだので、「再」たとえば、そこに緑のセクションで、「(スペースがある)再」、緑のセクションにありますが、前者1文字よりも後者より。
4つの問題に対処する必要があります。
-
从“r”开始,先行缓冲区中的字符串由几个字符构成?有什么规定吗?还是说只要能找到匹配,不管几个 字符都行? -
如何高效的在查找缓冲区中找到匹配串? -
如何找到最长匹配? -
找不到匹配怎么办?
5.2.1 匹配串中由几个字符构成?
-
単一の文字の長さから、子どもの交換した場合、それは同様に置き換えられない場合があります
-
子供のための2つの連続した文字は、交換が2つの数字(実際には文字の数)を使用する必要があります前と後に、それは、とにかく、何の関係も持って交換するか、距離の長さに置き換えた場合
-
文字列は、連続した文字に配置された少なくとも最初の3つのバッファを前提に置き換えることができ、また最初から始まる最初のバイトのバッファリングしなければなりません
このように:文字列が3つの連続した文字の最初の最小値からなるバッファ。つまり、とき先行缓冲区中的字符串至少由3个 连续的字符组成并且在查找缓冲区中找到了匹配、「+長さ距離」を持つ子どものバッファの交換には、この時点での最初の文字列。
5.2.2 如何高效的查找匹配串
文字列は、文字列を検索文字列バッファ内の一致のための資格を得るために、少なくとも三つの連続した文字が含まれている必要があります。圧縮された検索速度を上げるために辞書(ハッシュテーブル)を使用。圧縮に連続メモリ構成の単一片から、「辞書」、メモリのサイズは、図3に示すように、二つの部分、WSIZEサイズの各部分に分け、64キロバイトです。

ポインターhead = prev + WSIZE、prev指向该字典整个内存的起始位置。メモリが連続しているので、前頭部は、2基の配列、すなわちPREV []ヘッド、および[]のように見ることができます。
圧縮されたハッシュ値を計算するための3つの文字の使用、ハッシュ値は、ヘッド[]配列のインデックスです。異なる順序で配置された異なる三文字、計算されたハッシュ値は、異なる合計であり2^24 种结果、ハッシュ値の範囲は[0、32767](ヘッドアレイサイズが32Kである)、したがってそれぞれ行うことができません、文字列のハッシュ値に対応する肯定会存在冲突、とPREVは、競合を解決することであり、配列はまた、最長一致文字列を見つけることができます。
- 辞書建物
辞書のいわゆる建設、辞書に文字列にあり、バイトの圧縮によるバイトは、バイトでそれぞれ取引を行われ、バイトのための外観は拡大(あなたが32キロバイトに達している場合は、最初のバッファの方向にスライドバッファバイト)、先頭のバイトは常にバッファの最初の文字の前に変え、狭いバッファ。バッファの最初のバイトに先行するたびに変化が計算の構成文字列「の三つの連続バイトに先行するバッファの最初のバイトの前にバッファ現在の開始により」使用する必要がある場合ハッシュ値ins_h、ハッシュ値は、ヘッド配列[]のインデックスであるので、ヘッドと【ins_h]は、文字列の位置を記録するために表示され、文字列は、文字列(すなわち、電流の発生位置であります文字列辞書を挿入するプロセスであるウィンドウの現在の位置に)最初のバイトの前バッファ。

- 一致する文字列を検索します
注:辞書に文字列が、実際に文字列の開始位置が辞書に挿入され、ハッシュはちょうどこの最初の試合を満たしている場所を見つけるための予備的な試合を得た、唯一の長いマッチを見つけるために、この位置を使用目標です。
5.2.3 最長一致を見つける方法
插入时字典冲突怎么办?
使用挿入ヘッド[ins_h]に文字列、ins_h現在のハッシュ値、文字列、ヘッド[]配列のインデックスの現在の位置を記録するために表示されます。現在の位置は、文字列は、ヘッド[ins_h]に接続されて表示された場合、私はどのように[ins_h]空の頭を行うにはしていないとき?例えば:

仮定:strstart最初の位置は、ウィンドウのバッファの最初の文字であり、配列要素PREV [strstart]は文字列の前の位置です。:次のように挿入され

注:strstartが徐々に増加し、毎回の前の[strstart]割り当ては、各割り当ての前に、前の古い内容を上書きしません[strstart]は、必ずしも新しいことを確実にすることが可能です。

したがって、「形成链式」関係、チェーンPREVによってこの関係[]配列インデックス配列要素の値と一緒に、文字列の同じであるが、異なる鎖位置のハッシュ値を。
注:圧縮前の頭に[]配列はなり全てゼロに初期化が、PREV []配列を初期化しません。PREV []配列の初期化が動的に行われます。したがって、として一致フラグ列が存在しない、すなわちヘッド[X]とPREV [X] 0「空」と、彼らはそれ自体値意味、文字列は、文字列の位置であるが、0番目の文字ウィンドウは、以下からなります位置が曖昧であり、0であり、そして溶液の曖昧さが非常に簡単で粗製で、ウィンドウ内の最初の文字列が照合処理に参加できるようにする単純です。
先行缓冲区第一个字符位置大于32K怎么办?
バイトで圧縮バイトと、連続的に(増加させる)前進最初の文字バッファstrstartに先行する(スライディングウィンドウのサイズが64Kであるため)、strstartは32K、直接効果を超えた場合、32Kよりも大きくなるように結合されていますインデックスの前の配列は間違って行くでしょう。ソース・ソリューションです:レッツのstrstartとWMASKのビット単位のAND演算前のため[]インデックスのではなく、直接前のためstrstart []インデックス、WMASKに、前のある小数32768を、値[strstart &WMASK]。本性を保証strstartの範囲で、PREV []のインデックスことと完全strstartに対応しています。
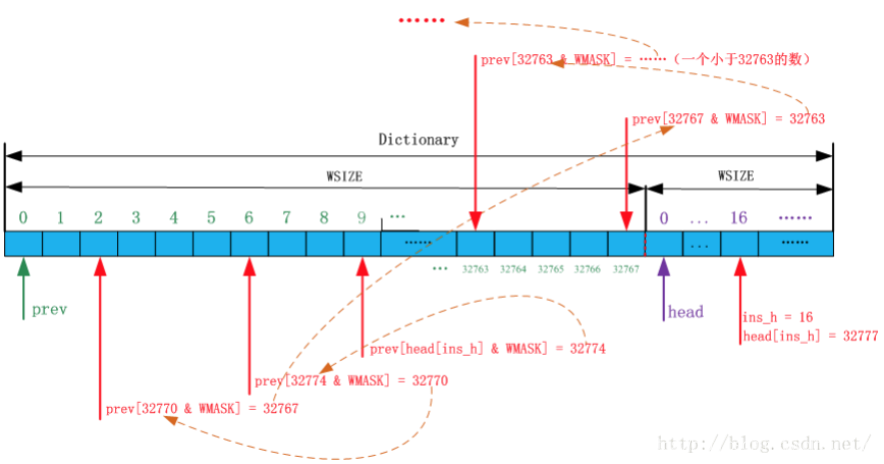
匹配链造成死循环怎么办? 当strstart大于32K的时候,匹配链有可能出现死循环。
この問題を解決するために、ソースの利用max_chain_lengthは(最大鎖長256を表し)、チェーン、最大の発見を見下ろしたとき、一致の数を示します。max_chain_length値が小さいほど、検索の少ない整合ノード、高速圧縮が、圧縮率が比較的低くてもよいです。
懒匹配ソースは最長一致を見つけるための2つの方法があります懒匹配和long_match。
レイジーは、現在の文字列の最長一致を見つけるlongest_match、最長一致異なる文字列に一致するものを検索します。
いわゆる怠惰な試合は、という現在の文字列は、一連の最適な一致を見つけるために、しかし急いで交換する子どもたちへの距離の長さをできるように、しかし、2つの変数でprev_lengthとprev_matchそれぞれ一致したレコードの長さと位置を一致させるものの、。
そして、現在の文字列を更新し、新しい場所にstrstart今、文字バッファを移動するstrstart最初の方向をみましょう。このとき、現在の文字列の一致文字列のために最も適したを検索します。試合と仮定すると得一致した位置が自分のスキル、時間怠惰な試合のその時点で、長さと一致し、現在の文字列の文字列のために最も適して発見されました。前者が後者より大きければ現在位置更新prev_matchと一致しながら、現在のマッチした文字列の一致長とprev_lengthと比較して、後者と前者は、更新され、 - 上の位置としてその文字(現在strstart 1)で一致するプロセス文字ず、prev_length prev_match更新を完了し、その後さらにstrstartが文字バッファの移動方向に先行し、同様の処理を継続する場合、この方法は、怠惰な一致です。
前者が後者よりも小さい場合、すなわち、最後の一致(prev_length)の長さがこれより大きい場合、遅延マッチを停止し、子供タプルの最後の完全な交換とのマッチング位置から組成及び長の一致長。
怠惰な一致が停止した後、prev_lengthとprev_match初期化、strstartは、遅延マッチング処理の新しいラウンドを開始する準備ができて、(列の外側交換する)新しい場所に移動しました。文字列からなる文字列は、すべての文字がまだ辞書に挿入されるように置換されることに注意してください。

5。 longest_match
longest_matchは、マッチング・チェーンを横断しているもちろん、最長の部分文字列マッチングのチェーンを見つけるために、最も長い部分文字列は、それがベストマッチを見つけるために、怠惰の組み合わせを必要とし、必ずしも最適ではありません。

注意:
- 無限に実行されないマッチング・ノードを横断する、チェーン・ノードの最大数と一致するようには限界があります
- マッチングの一致文字列の長さが無限ではなく、文字列マッチングの最大一致長はMAX_MATCH(258)であり
- 距離は無限ではないマッチ、マッチング距離がMAX_DISTを超えることはできません。
- 一致longest_match怠惰と仕事一緒にして得られた最長一致文字列。前者は、発見された最も長い文字列の一致の長さに責任がある現在のstrstartの最長一致を見つけるための責任があるという究極のように、いくつかの連続するstrstartで最長一致で本当の最長一致。
5.2.4 找不到最长匹配怎么办?
試合の文字列に圧縮結果を得るために、またはどのように元の文字と区別するには?例えば:

注:無登録の実際の圧縮ストリングの距離。そこで質問です:23は、それはそれを区別する方法、距離ではない文字の源であり、12の代表、16、右?
ソリューション:1ビットをマークすると、そのような距離を表し、0はソース文字を表し。
5.2.5 解凍

解凍すると、バイトを解析します:
- 現在のバイトの最上位ビットは、ファイルに直接ソースバイト書き込みを表し、0であれば
- 現在のバイトの最上位ビットが1、代表距離である場合、開始位置の距離と実効解析文字列の一致長に応じて、次にペアから採取し、そして。
5.3 GZIPハフマンの思考
繰り返し圧縮ソースデータの変形フロントLZ77のアイデアによって運ば声明文レベルの再現後には解決されているが、それは効果も繰り返しの多くを持って最高の圧縮、バイトレベルを達成してきたことを意味するものではありません。
例:「BCDCDDBDDCADCBDC」
8ビットを表すバイトは、その後、我々は、すべての符号化されたバイトを見つけることができる場合に8ビットより小さい場合、対応するバイトが再度書き換えられる見つけるために、ソースファイルをエンコードするソースファイルを小さくすることができるように、。それをコードすることを発見するには?
5.3.1 静的等しい長コーディング、各文字のコード長は、例えば、同じです。
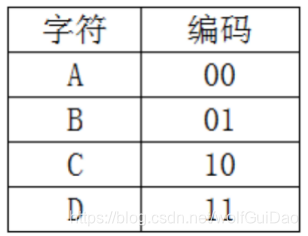
等しい長さは、ソースデータの圧縮符号化で:0,110,111,011,110,111 1,110,001,110,011,110を、圧縮結果の完了のみ4バイトの後に、圧縮率は依然として比較的高いです。
5.3.2 動的可変長コード:文字の各文字を符号化するためになど、特定の状況に応じて決定されます

可変長符号データ圧縮源を使用して:最後のバイトの終了後1,011,101,100,101,001 1,100,011,101,011圧縮も明らか長符号化圧縮率が良くダイナミックピア可変長符号よりもすることができ、残りの3ビットを使用していません。それを得るためにどのように動的な可変長符号?
5.3.3 FFコーディングHU男
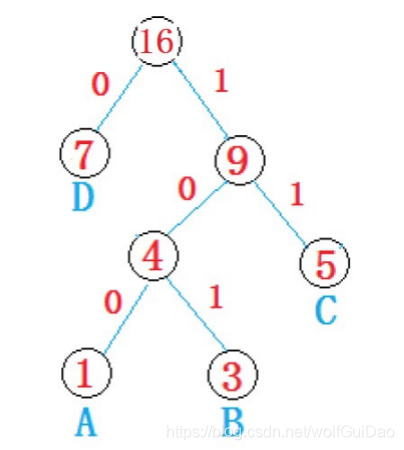
男ツリーFF 1.ha
重み付け二分木とバイナリツリー経路長WPLのためのすべての経路長のリーフノードと対応する重みのルートから二分木の製品。

それぞれ4本の木の重み付き経路長:
- WPLa = 3 + 1×2×2×2 + 5 + 7×2 = 32
- WPLB = 1 * 2 + 3 * 3 + 5 * 3 + 7×1 = 33
- WPLC = 7 * 3 + 5×3 + 3×2 + 1×1 = 43
- WPLd = 1 * 3 + 3 * 3 + 5 * 2 + 7×1 = 29
分木の最小加重経路がフーFF人と呼ばれています
2. HU男FF木構築
-
N-重み{W1、W2、W3、...、WN}所与のn木だけルートノード構成バイナリツリーの森F = {T 1、T2、T3、...、Tnを}、及びそれらのそれぞれのみ加重バイナリーTiでルートノードの値のwiは、子供たちは空のままにしています。
-
次の木Fまで左まで、次の手順を繰り返します
- Fにおける2つのバイナリ重みの最小根、新しいバイナリツリー構造として、左右のサブツリー、子ルートノードの重量についてである重量の新しいバイナリ値のルートノードを選択して
- Fにこれらの二つのバイナリツリーを削除します。
- Fに追加された新しいバイナリ、

3. コーディング男FF取得ヘクタール

5.3.4使用して、ソースファイルの圧縮をコードHU FF男を
统计源文件中每个字符出现的次数以字符出现的次数为权值创建huffman树通过huffman树获取每个字符对应的huffman编码读取源文件,对源文件中的每个字符使用获取的huffman编码进行改写,将改写结果写到压缩文件中, 直到文件结束。
5.3.4 圧縮ファイル形式
压缩文件中只保存压缩之后的数据可以吗?
解凍するとき、それを抽出する方法がないので答えは、十分ではありません。たとえば:あなたはまた、圧縮されたデータに加えて、圧縮ファイルを保存したいので1,011,101,100,101,001 1,100,011,101,011、唯一の圧縮データは、解凍に方法はありません保存に使用するために必要な情報を抽出する必要があります:
- ソースファイルのサフィックス
- 行の合計数の文字の数
- 文字と文字の数(各文字が一列に配置されている間に簡単にするために)表示され
- 圧縮データ
5.3.5 解凍
- 圧縮されたファイルからソースファイルの接尾辞を取得します。
- 行の合計数で圧縮したファイルからの文字数を取得します。
- 各文字が表示された回数を取得します。
- 復興HU FF男ツリー
- 減圧
圧縮されたデータバイトの圧縮されたファイルから取得し、取得した圧縮データの各バイトは、ルートから開始し、バイナリビットバイトHU FF人ツリートラバーサルの情報は、このビットが0の場合、現在のノードを取っています左の子は、リーフノードの位置を通じて子どもたちをテイクダウンするそうでない権利は、文字が正常に解決されました。データ解析のすべてが完了するまで、このプロセスを続行します。
