Fonctionnalités et architecture du GPU
Introduction de base au GPU
Introduction aux concepts de GPU
GPU, unité de traitement graphique (unité de traitement graphique), également appelé noyau d'affichage, processeur visuel, puce d'affichage, est un type de processeur spécialement utilisé sur les ordinateurs personnels, les postes de travail, les consoles de jeux et certains appareils mobiles (tels que les tablettes, les smartphones, etc. .) Microprocesseur qui effectue des opérations liées aux images et aux graphiques.
La naissance du GPU
- NVIDIA a proposé pour la première fois le concept de GPU lors du lancement de la puce de traitement graphique GeForce 256 le 31 août 1999.
- La principale raison pour laquelle le GPU est appelé processeur graphique est qu'il peut effectuer presque toutes les opérations de données liées à l'infographie, qui étaient autrefois le domaine exclusif des processeurs.
- Actuellement, l’infographie se trouve dans une période de développement sans précédent. Ces dernières années, la technologie GPU s’est développée à une vitesse incroyable. Les taux de rendu doublent tous les 6 mois. Les performances se sont améliorées des milliers de fois depuis 1999 ! Dans le même temps, non seulement les performances ont été améliorées, mais la qualité des calculs et la flexibilité de la programmation graphique se sont également progressivement améliorées.
Forme physique de la macro GPU
- Grâce à l’introduction de la nanotechnologie, les GPU peuvent intégrer des centaines de millions de transistors et d’appareils électroniques dans une petite puce. Du point de vue de la structure macro-physique, la plupart des GPU de bureau modernes sont du même ordre de grandeur que les pièces de monnaie.
- Lorsque le GPU est combiné avec des ventilateurs de refroidissement, des emplacements PCI, des interfaces HDMI et d'autres composants, il forme une carte graphique.
- La carte graphique ne peut pas fonctionner indépendamment et doit être chargée sur la carte mère et combinée avec des périphériques matériels tels que le processeur, la mémoire, la mémoire vidéo et le moniteur pour former un PC complet.
Fonctionnalités du GPU
- Dessin graphique
Les fonctions les plus traditionnelles, de base et essentielles du GPU. Fournit des fonctions de traitement graphique et de dessin pour la plupart des ordinateurs de bureau, des appareils mobiles et des postes de travail graphiques.
- simulation physique
Le moteur physique (PhysX, Havok) intégré au matériel GPU fournit des simulations physiques avec des performances des centaines ou des milliers de fois pour les jeux, les films, l'éducation, les simulations scientifiques et d'autres domaines, permettant ainsi de présenter en réalité des simulations physiques qui nécessitaient auparavant des calculs à long terme. temps.
- Informatique massive
L'émergence des shaders de calcul et de la sortie de flux a permis diverses demandes massives de calcul parallèle, tel que CUDA.
- Informatique IA
Ces dernières années, l’essor de l’intelligence artificielle a favorisé l’intégration des unités de calcul AI Core dans les GPU, ce qui a contribué à l’amélioration des capacités informatiques de l’IA et apporté des améliorations aux capacités informatiques dans tous les domaines.
- Autres calculs
L'encodage et le décodage audio et vidéo, le cryptage et le déchiffrement, le calcul scientifique, le rendu hors ligne, etc. sont tous indissociables des capacités de calcul parallèle et des capacités de débit massif des GPU modernes.
Développement de l'architecture GPU à travers les générations
- Architecture Fermi, y compris les séries GTX4 et GTX5
- Architecture Kepler, série GTX6
- Architecture Maxwell, série GTX9 et GTX750
- Architecture Pascal, série GTX10
- Architecture Turing, séries RTX20 et série GTX16
- Architecture Ampère, série RTX30
- Architecture AdmAnda, série RTX40
La différence entre GPU et CPU
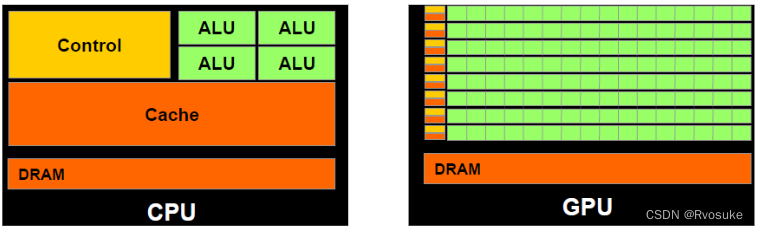
- Boîte verte : unités de calcul (unités calculables) ou cœurs de calcul (cœurs de calcul)
- Boite orange : souvenirs (mémoire)
- Encadré jaune : unités de contrôle (unités de contrôle)
La différence entre les unités de calcul (cœurs)
- Les unités de calcul du CPU ont une forte puissance de calcul et sont peu nombreuses ;
- Les unités de calcul du GPU ont une faible puissance de calcul et un grand nombre ;
- L'avantage du CPU réside dans le noyaupuissance de calcul、Calculer la capacitéFort, avec des « exécutions dans le désordre » (exécution dans le désordre)Fonction ;
- L'avantage du GPU estTraitement massivement parallèle des donnéescapacité à adopterSIMDMéthode de programmation, les opérations de calcul de chaque Core sont effectuées en même temps ; (MAD et FMA) L'instruction MAD calcule effectivement la valeur de A*B+C
- GPULe noyau ne peut effectuer que certaines des opérations à virgule flottante les plus simples, telles que les instructions de multiplication-ajout (MAD) ou de multiplication-ajout fusionné (FMA) ;
- La principale différence entre MAD et FMA est qu'ils visent tous deux à résoudre A*B+C
La différence entre la mémoire
-
Le système de mémoire du CPU est généralement basé surDRAM et sur le cache dans son système de mémoire Il peut réduire le temps nécessaire au processeur pour accéder à la DRAM ;
-
La mémoire (DRAM) du GPU est appeléemémoire globaleouGMEM , sa taille de mémoire est bien inférieure à la DRAM du processeur ;
-
Le petit bloc orange dans le coin supérieur gauche du GPU est le segment de cache du GPU.Les mécanismes de cache du GPU et du CPU sont différents (expliqués dans la version 4.3) ;< /span>
Architecture sous-jacente du GPU
Dans certaines applications, il n'est pas nécessaire de communiquer entre plusieurs cœurs. Par exemple, dansmise à l'échelle d'image, cœur et cœur. Aucune collaboration n'est nécessaire entre eux, leurs tâches sontcomplètement indépendantes, donc de simples opérations parallèles suffisent.
Mais il existe également de nombreuses occasions où plusieurs cœurs doivent communiquer et coopérer les uns avec les autres, comme tableaux Sommeproblème.
Problème de somme de tableau GPU
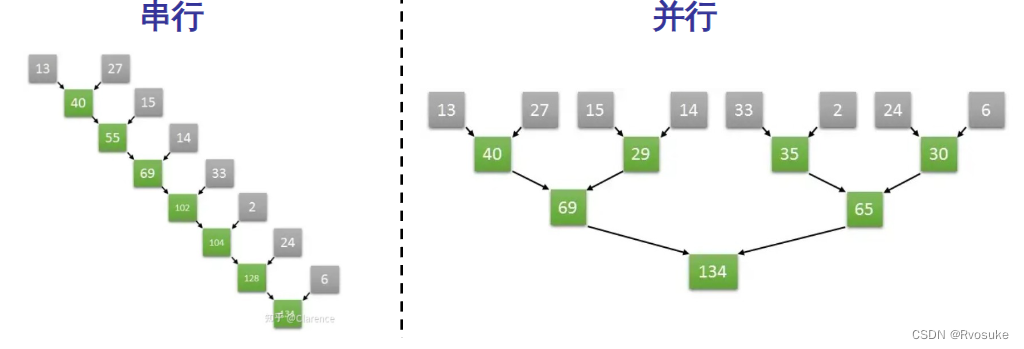
Les tableaux de longueur 8 sont additionnés par paires. Il ne faut que 3 fois pour calculer le résultat. Le calcul séquentiel nécessite < /span>< a i=3>8 fois.
Si selon l'algorithme d'addition parallèle par paire, N nombres sont ajoutés, alors seulement l o g 2 N log_2N log2Le calcul peut être effectué en N fois.
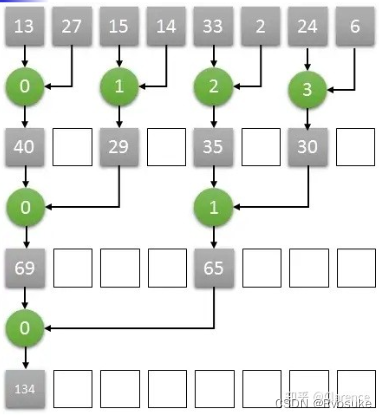
Le GPU n’a besoin que de quatre cœurs pour compléter l’algorithme de sommation de tableau de longueur 8.
Plusieurs cœurs doiventpartager un espace mémoire pour les opérations de lecture/écriture afin de compléter l'interaction des données.
Méthode de collaboration entre plusieurs cœurs : classifiez les cœurs de différents types de GPU en plusieurs groupes pour former plusieurs processeurs de flux ( Streaming Multiprocessors )< /span>. SM, appelés
Architecture GPU globale (en prenant l'architecture Turing comme exemple)
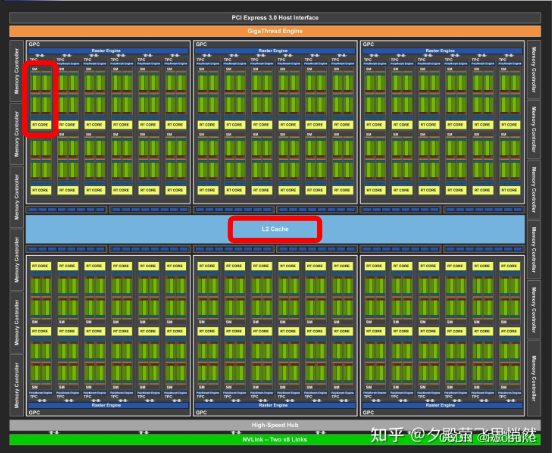
Le bloc vert est SM (une collection de noyaux)
SM (architecture Turing comme exemple)
Il existe différents types de CORE. Principalement divisé en INT32, FP32, TENSOR CORES, etc.
Les cœurs FP32 effectuent des opérations en virgule flottante à progression unique ;
Les cœurs FP64 effectuent des opérations à virgule flottante à double progression ;
Integer Cores, effectuez des opérations sur des nombres entiers ;
Tensor Cores, qui effectuent des calculs tensoriels pour accélérer les opérations courantes d'apprentissage en profondeur ;
Mécanisme de mise en cache GPU et coopération de communication entre plusieurs cœurs
Il y en a un au bas des quatre blocs SMCache L1, permettant l'accès par chaque Core. Chaque SM a un bloc dans le Cache L1 dédiémémoire partagée. Le cache L1 a une taille limitée et est très rapide, bien plus rapide que l'accès à GMEM.
Le cache L1 a deux fonctions : l'une permet aux cœurs de SM de partager de la mémoire entre eux et l'autre est . L'accès L1 est le plus rapide, L2 est le deuxième et GMEM est le plus lent. S'il n'est pas trouvé, il le fera revenir en arrière< /span>GMEM. S'il n'y a pas de cache L2, il sera recherché à partir de Cache L2L1, les instructions compilées par le compilateur stockeront une partie des résultats dans la mémoire partagée afin que les différents cores puissent obtenir les données correspondantes. Lorsqu'il est utilisé comme fonction de cache normale, lorsque le noyau a besoin d'accéder aux données GMEM, il recherchera d'abord dans travailler ensemble. Lorsque les Cores doivent Fonction de cache commune
Futures mises à niveau matérielles du GPU
Plus d'unités de calcul ;
plus d'espace de stockage ;
Une concurrence plus élevée ;
bande passante plus élevée ;
Latence inférieure ;
Recherchez dans che. S'il n'y a pas de cache L2, les données seront obtenues à partir de GMEM**, L'accès L1 est le plus rapide, L2 est le deuxième et GMEM est le plus lent.
Futures mises à niveau matérielles du GPU
Plus d'unités de calcul ;
plus d'espace de stockage ;
Une concurrence plus élevée ;
bande passante plus élevée ;
Latence inférieure ;
… …