Préface
La 6e conférence chinoise sur la reconnaissance de formes et la vision par ordinateur (PRCV 2023) s'est récemment tenue avec succès à Xiamen. En participant à cette conférence, j'ai eu l'occasion de rencontrer de nombreux chercheurs et collègues de l'industrie dans le domaine de la reconnaissance de formes et de la vision par ordinateur du pays et de l'étranger, et de découvrir les dernières réalisations théoriques et techniques dans le domaine de la reconnaissance de formes et de la vision par ordinateur en mon pays. Parmi eux, celui qui m'a le plus touché était la section spéciale sur « Exploration des technologies de pointe de l'image documentaire – Multimodalité et sécurité de l'image » , expliquée par le Dr Guo Fengjun de Shanghai Hehe Information .

Héhé, les informations
Avant d'expliquer la sécurité multimodale et d'image , donnons une brève introduction à Hehe Information Technology.
Shanghai Hehe Information Technology Co., Ltd. s'engage à fournir des services numériques et intelligents innovants aux entreprises mondiales et aux utilisateurs individuels grâce à des technologies de base dans les domaines de la reconnaissance de texte intelligente et du Big Data commercial, des produits côté C et côté B et de l'industrie. solutions.

Les produits C-end qu'elle a développés, qui sont appréciés des utilisateurs du monde entier, ont été téléchargés par plus de 2,3 milliards d'utilisateurs dans le monde, avec un nombre d'utilisateurs actifs mensuels cumulés d'environ 130 millions. Parmi elles, les versions gratuites de Business Card King et Scanner King figurent en tête du classement de l’App Store.
Analyse, reconnaissance et compréhension d’images de documents
défi technique
Lors de la conférence, le Dr Guo a développé les difficultés techniques actuelles dans l'analyse, la reconnaissance et la compréhension des images de documents, qui se reflètent principalement dans les aspects suivants :
- Lorsque la qualité de l’image du document se dégrade, l’image du document devient floue. Ce problème de qualité est étroitement lié à la technologie de numérisation d’images de documents ;
- D'après les exemples d'images suivants, la mise en page du texte est très complexe, ce qui pose d'énormes défis en matière d'analyse de mise en page et de détection de texte ;
- Dans le domaine de la reconnaissance de texte, en raison de l'écriture bâclée, il existe de nombreux types de reconnaissance, en plus du texte et des formules, il existe également des symboles spéciaux ;
explorer
Sur la base des questions et problèmes ci-dessus, Hehe Information a divisé le sujet de recherche sur l'analyse, la reconnaissance et la compréhension d'images de documents en six modules suivants :

- Analyse et prétraitement des images de documents : il résout principalement le problème de qualité des images de documents. Par exemple, une image de document qui ne peut pas être vue clairement par l'œil humain a été traitée par amélioration du rognage des bords, suppression du moiré, correction du pli, compression d'image, détection PS. et d'autres technologies.Après traitement, cela devient une image très claire et de très haute qualité.
- Analyse et reconnaissance de documents : après l'analyse et le prétraitement de l'image du document, l'image du document ira ensuite au module d'analyse et de reconnaissance de documents. Nous obtenons des informations textuelles grâce à des technologies telles que la reconnaissance de texte, la reconnaissance de tableaux et l'analyse de fichiers électroniques.
- Analyse et restauration de la mise en page : nous traiterons les informations textuelles obtenues à l'étape précédente, utiliserons la détection des éléments, l'identification des éléments, la restauration de la mise en page et d'autres technologies pour identifier le titre, le paragraphe, l'image et d'autres éléments du document, et restaurer la structure de mise en page d'origine. du document pour l’extraction et la compréhension ultérieures des informations.
- Extraction et compréhension d'informations documentaires : Utiliser la technologie informatique pour extraire automatiquement des informations utiles à partir de documents et les comprendre, les classer et les résumer. L'extraction et la compréhension des informations documentaires peuvent aider les utilisateurs à gérer et à utiliser plus efficacement de grandes quantités de données documentaires, améliorant ainsi l'efficacité du travail et la qualité de la prise de décision. Il offre de larges perspectives d'application dans la gestion de fichiers numériques, la gestion des connaissances d'entreprise, les moteurs de recherche, le service client automatisé et d'autres domaines.
- Sécurité de l'IA : dans le processus d'analyse, de reconnaissance et de compréhension des images de documents, la confidentialité des données de l'utilisateur et la sécurité des images de documents sont assurées grâce à la classification des falsifications, à la détection des falsifications, à la détection de synthèse, à la détection de génération d'IA et à d'autres technologies.
- Connaissances et stockage, récupération et gestion : organiser, stocker, récupérer et gérer efficacement les informations et les connaissances, extraire des connaissances utiles à partir d'une grande quantité de données et d'informations et faciliter leur accès et leur utilisation, ce qui est important pour améliorer l'efficacité du travail et la prise de décision. -la qualité de fabrication et les capacités d'innovation sont d'une grande importance.
Avancées et exploration des modèles multimodaux
Avec l'émergence de ChatGPT l'année dernière, tout le monde s'intéresse beaucoup à savoir si les modèles multimodaux peuvent être rapidement intégrés dans leurs scénarios de travail. Parlons ensuite de l’impact qu’auront les grands modèles multimodaux sur le traitement des images de documents.
Propriétés multimodales de l'image du document
Les grands modèles multimodaux font référence à de puissants modèles de réseaux neuronaux capables de traiter plusieurs types de données (telles que des images, du texte, de la parole, etc.) simultanément. Il intègre des données d'entrée provenant de plusieurs modalités et effectue une formation et une inférence conjointes via une structure de modèle partagée.
L'idée principale des grands modèles multimodaux est de fusionner et d'interagir avec des données provenant de différentes modalités pour obtenir un traitement des tâches plus complet et plus précis. Par exemple, dans les tâches de génération d'images et de documents, le modèle peut accepter à la fois les entrées d'image et de document et générer la sortie correspondante en fonction de l'association entre les deux. On peut voir que les images de documents ont des propriétés multimodales naturelles .
Application de grands modèles multimodaux au traitement d'images de documents
- GPT-4 : les grands modèles multimodaux tels que GPT-4 ont fait des progrès significatifs et peuvent traiter simultanément des données de texte et d'image, améliorant ainsi les performances de reconnaissance et de compréhension d'images de documents. Cela facilite le traitement de nombreux types d’informations, notamment le texte, les images et d’autres médias.
- Google Bard : Google Bard est un autre grand modèle multimodal qui fonctionne également bien dans le domaine des images de documents. Cette compétition stimule le progrès technologique dans le domaine et devrait conduire à davantage d'innovation.
- Grands modèles d'images de documents : une série de grands modèles propriétaires ont émergé dans le domaine du traitement d'images de documents, tels que les séries LayoutLM, LiLT INTSIG, UDOP et Donut. Ces modèles utilisent des encodeurs Transformer multimodaux et peuvent être appliqués à différentes tâches de traitement d'images de documents, notamment le texte, les tableaux, la structure de mise en page et la prise en charge multilingue.
- Limites des grands modèles multimodaux : bien que les grands modèles multimodaux fonctionnent bien dans le traitement du texte et des images, ils présentent encore certaines limites, notamment de mauvaises performances dans le traitement du texte à granularité fine. Cela présente des défis et des opportunités pour les recherches futures visant à améliorer encore les performances de ces modèles.
Documenter les tendances technologiques en matière de traitement d'images à l'ère du LLM
Avec les progrès rapides de la technologie dans le domaine des grands modèles, les experts dans le domaine ont fait des prédictions sur la tendance de la technologie de traitement d'images de documents à l'ère du LLM. On pense généralement que l'extrémité d'entrée doit être une approche multimodale, que l'architecture doit être une architecture de transformateur, d'encodeur/décodeur et que le niveau de données doit être constitué de données massives/de haute qualité. Ce n'est que lorsque les trois conditions ci-dessus sont remplies qu'un meilleur effet d'un modèle d'image de document volumineux peut être obtenu.
Après la sortie de ChatGPT4, la méthode précédente de création d'OCR s'appliquera-t-elle toujours ? La réponse est oui, l'OCR reste une technologie importante dans les grands modèles multimodaux, car la formation d'un bon grand modèle dépend de Big Data de haute qualité, et l'OCR elle-même est un outil qui fournit des données de haute qualité. L'OCR peut prendre en charge une saisie de données efficace pour les grands modèles et prend en charge l'extraction d'informations dans différents formats.
Système bien connu pour le traitement d’images de documents

Grâce à une analyse expérimentale comparative, les performances du système d'évaluation actuel des grands modèles doivent encore être améliorées, et elles ne sont toujours pas significatives par rapport aux résultats de l'apprentissage supervisé. La raison peut être liée à la résolution de l'encodeur visuel et aux limitations des données d'entraînement.

sécurité des images
Avec le développement rapide de l'intelligence artificielle générative, dans le domaine des images, de plus en plus de systèmes sont capables de générer des images génératives avec une très haute qualité d'image. L'authenticité et la sécurité des images deviennent de plus en plus importantes. Le changement de visage de l'IA, la falsification de licences, etc. auront un impact sur le système de certification des secteurs de la banque, de l'assurance et de la finance :



L'Académie chinoise des technologies de l'information et des communications s'est associée à Hehe Information pour lancer la formulation de la « Norme de détection de falsification d'images de documents » afin de fournir une garantie fiable pour la sécurité du contenu des images de documents et d'aider à établir un système de sécurité d'IA dans la nouvelle ère. Cela se reflète principalement sous deux aspects : la détection de falsification d’image et la discrimination AIGC.
Type de sabotage
La falsification d'image est divisée en quatre types : copie et déplacement, collage, effacement et réimpression.

structure du système
La solution est principalement résolue grâce au modèle de segmentation suivant : Backbone utilise ConvNeXt comme encodeur et utilise LightHam et EANet en parallèle comme décodeur pour obtenir de meilleurs résultats de jugement.

défis techniques
Le principal défi technique lié à la falsification d’images de documents et de photos d’identité se reflète principalement dans sa généralisation. L'amélioration du problème de généralisation est obtenue grâce à la construction de grandes quantités de données et à l'ajustement continu de l'ensemble de la stratégie de formation.

Hehe Information a remporté cette année le championnat de détection de falsification d’images de documents ICDAR2023.

Identification générative de l'IA
En prenant la scène du visage comme exemple, plusieurs têtes d'attention spatiale sont utilisées pour se concentrer sur les caractéristiques spatiales, et le module d'amélioration de la texture est utilisé pour amplifier les artefacts subtils dans les caractéristiques superficielles afin d'améliorer la perception et la précision du jugement du modèle sur les visages réels et les faux visages.
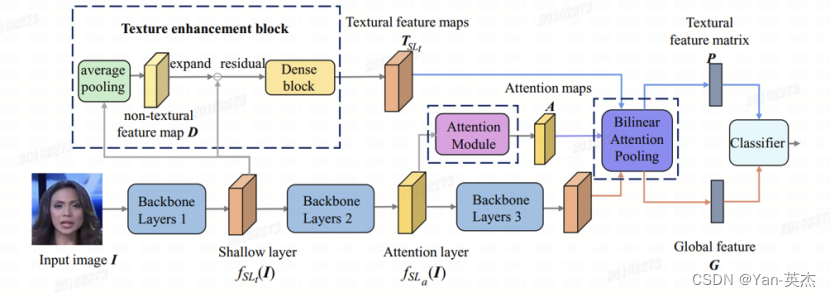
Affichage des résultats d'identification

Perspectives
Les résultats des recherches de Hehe Information fournissent des solutions pratiques pour diverses industries. Le traitement intelligent des images est l'un des domaines importants. Hehe Information a développé des algorithmes et des outils de traitement d'images efficaces et précis, fournissant des solutions optimisées pour divers scénarios d'application. Ces résultats sont largement utilisés dans les domaines financier, manufacturier, médical et autres, améliorant considérablement l'efficacité et la précision et apportant des avantages pratiques au développement de diverses industries. On espère que Hehe Information pourra continuer à mener des recherches, des explorations et des innovations technologiques approfondies, continuer à réaliser davantage de percées et promouvoir l'application de la technologie de l'intelligence artificielle et le développement de l'industrie intelligente.