Table des matières
Certains fichiers d'informations et fichiers de code pertinents peuvent être trouvés directement à la fin de l'article ~ N'oubliez pas d'aimer et de soutenir ~

avant-propos
Le crawler consiste cette fois à capturer des informations sur les prix des logements, et son but est de pratiquer le traitement des données et l'exploration complète de plus de 100 000.
Le sentiment le plus intuitif de l'augmentation de la quantité de données est l'augmentation des exigences en matière de logique de fonction.Selon les caractéristiques de Python, la structure de données est soigneusement sélectionnée. Dans le passé, lors de la capture de petites quantités de données, même si la partie logique de la fonction est répétée, la fréquence des demandes d'E/S est intensive et l'imbrication de boucle est trop profonde, la différence n'est que de 1 à 2 s. augmentation de l'échelle des données, la différence de 1 ~ 2s Il est possible d'étendre à h.
Par conséquent, pour les sites Web qui doivent capturer une grande quantité de données, nous pouvons réduire le temps nécessaire à la capture d'informations sous deux aspects.
1) Optimisez la logique de fonction, sélectionnez la structure de données appropriée et conformez-vous aux habitudes de programmation Pythonic. Par exemple, la combinaison de chaînes utilise join() pour économiser de l'espace mémoire que "+".
2) Sur la base des méthodes d'exécution parallèle multi-thread et multi-processus gourmandes en E/S et CPU, sont sélectionnées pour améliorer l'efficacité de l'exécution. # 1. Qu'est-ce que les pandas ?
Exemple : pandas est un outil basé sur NumPy créé pour résoudre des tâches d'analyse de données.
1. Obtenez l'indice
Enveloppez la demande et définissez le délai d'expiration
# 获取列表页面
def get_page(url):
headers = {
'User-Agent': r'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
r'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Referer': r'http://bj.fangjia.com/ershoufang/',
'Host': r'bj.fangjia.com',
'Connection': 'keep-alive'
}
timeout = 60
socket.setdefaulttimeout(timeout) # 设置超时
req = request.Request(url, headers=headers)
response = request.urlopen(req).read()
page = response.decode('utf-8')
return page
Emplacement du niveau 1 : informations sur la zone
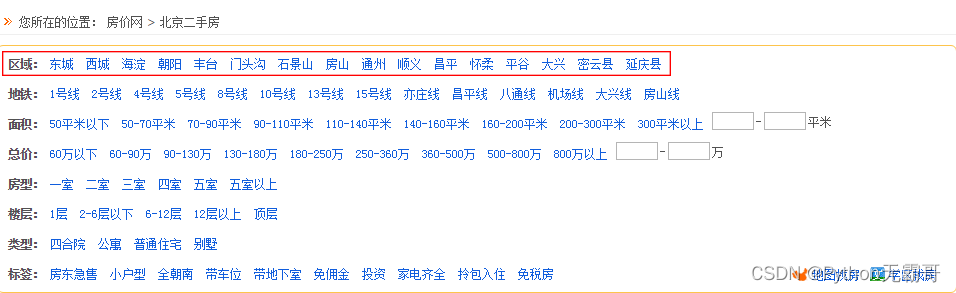
Position secondaire : informations sur la plaque

Stocké dans dict, vous pouvez rapidement interroger la cible que vous recherchez. -> {'Chaoyang' : {'Gongti', 'Anzhen', 'Pont Jianxiang'...}}
Localisation niveau 3 : informations métro (recherche d'informations logement autour du métro)

Ajoutez les informations de localisation du métro au dict. -> {'Chaoyang' : {'Gongti' : {'Ligne 5', 'Ligne 10', 'Ligne 13'}, 'Anzhen', 'Pont Jianxiang'...}}
URL correspondante : http://bj.fangjia.com/ershoufang/–r-%E6%9C%9D%E9%98%B3%7Cw-5%E5%8F%B7%E7%BA%BF%7Cb- % E6%83%A0%E6%96%B0%E8%A5%BF%E8%A1%97
URL décodée : http://bj.fangjia.com/ershoufang/–r-Chaoyang|w-Line 5|b-Huixin West Street
Selon le paramètre mode de l'url, il existe deux manières d'obtenir l'url de destination :
- Obtenir l'url de destination selon le chemin de l'index

# 获取房源信息列表(嵌套字典遍历)
def get_info_list(search_dict, layer, tmp_list, search_list):
layer += 1 # 设置字典层级
for i in range(len(search_dict)):
tmp_key = list(search_dict.keys())[i] # 提取当前字典层级key
tmp_list.append(tmp_key) # 将当前key值作为索引添加至tmp_list
tmp_value = search_dict[tmp_key]
if isinstance(tmp_value, str): # 当键值为url时
tmp_list.append(tmp_value) # 将url添加至tmp_list
search_list.append(copy.deepcopy(tmp_list)) # 将tmp_list索引url添加至search_list
tmp_list = tmp_list[:layer] # 根据层级保留索引
elif tmp_value == '': # 键值为空时跳过
layer -= 2 # 跳出键值层级
tmp_list = tmp_list[:layer] # 根据层级保留索引
else:
get_info_list(tmp_value, layer, tmp_list, search_list) # 当键值为列表时,迭代遍历
tmp_list = tmp_list[:layer]
return search_list
- Enveloppez l'URL selon les informations du dict
{'Chaoyang' : {'Gongti' : {'Ligne 5'}}}
paramètre:
—— r-Chaoyang
—— corps de travail b
—— Ligne w-5
Paramètres d'assemblage : http://bj.fangjia.com/ershoufang/–r-Chaoyang|w-line 5|b-gongti
# 根据参数创建组合url
def get_compose_url(compose_tmp_url, tag_args, key_args):
compose_tmp_url_list = [compose_tmp_url, '|' if tag_args != 'r-' else '', tag_args, parse.quote(key_args), ]
compose_url = ''.join(compose_tmp_url_list)
return compose_url
2. Obtenez le nombre maximum de pages dans la page d'index
# 获取当前索引页面页数的url列表
def get_info_pn_list(search_list):
fin_search_list = []
for i in range(len(search_list)):
print('>>>正在抓取%s' % search_list[i][:3])
search_url = search_list[i][3]
try:
page = get_page(search_url)
except:
print('获取页面超时')
continue
soup = BS(page, 'lxml')
# 获取最大页数
pn_num = soup.select('span[class="mr5"]')[0].get_text()
rule = re.compile(r'\d+')
max_pn = int(rule.findall(pn_num)[1])
# 组装url
for pn in range(1, max_pn+1):
print('************************正在抓取%s页************************' % pn)
pn_rule = re.compile('[|]')
fin_url = pn_rule.sub(r'|e-%s|' % pn, search_url, 1)
tmp_url_list = copy.deepcopy(search_list[i][:3])
tmp_url_list.append(fin_url)
fin_search_list.append(tmp_url_list)
return fin_search_list
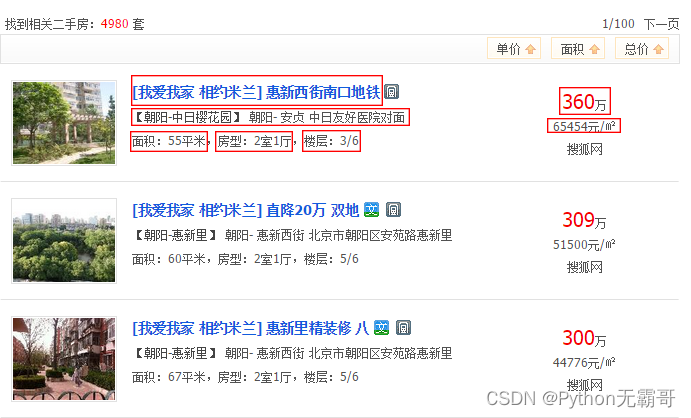
3. Saisissez la balise d'informations sur la liste
Voici la balise que nous voulons saisir :
['zone', 'assiette', 'métro', 'titre', 'emplacement', 'mètre carré', 'type de maison', 'étage', 'prix total', 'prix unitaire au mètre carré']
# 获取tag信息
def get_info(fin_search_list, process_i):
print('进程%s开始' % process_i)
fin_info_list = []
for i in range(len(fin_search_list)):
url = fin_search_list[i][3]
try:
page = get_page(url)
except:
print('获取tag超时')
continue
soup = BS(page, 'lxml')
title_list = soup.select('a[class="h_name"]')
address_list = soup.select('span[class="address]')
attr_list = soup.select('span[class="attribute"]')
price_list = soup.find_all(attrs={
"class": "xq_aprice xq_esf_width"}) # select对于某些属性值(属性值中间包含空格)无法识别,可以用find_all(attrs={})代替
for num in range(20):
tag_tmp_list = []
try:
title = title_list[num].attrs["title"]
print(r'************************正在获取%s************************' % title)
address = re.sub('\n', '', address_list[num].get_text())
area = re.search('\d+[\u4E00-\u9FA5]{2}', attr_list[num].get_text()).group(0)
layout = re.search('\d[^0-9]\d.', attr_list[num].get_text()).group(0)
floor = re.search('\d/\d', attr_list[num].get_text()).group(0)
price = re.search('\d+[\u4E00-\u9FA5]', price_list[num].get_text()).group(0)
unit_price = re.search('\d+[\u4E00-\u9FA5]/.', price_list[num].get_text()).group(0)
tag_tmp_list = copy.deepcopy(fin_search_list[i][:3])
for tag in [title, address, area, layout, floor, price, unit_price]:
tag_tmp_list.append(tag)
fin_info_list.append(tag_tmp_list)
except:
print('【抓取失败】')
continue
print('进程%s结束' % process_i)
return fin_info_list
4. Attribuez des tâches et récupérez en parallèle
Divisez la liste des tâches, configurez un pool de processus et récupérez en parallèle.
# 分配任务
def assignment_search_list(fin_search_list, project_num): # project_num每个进程包含的任务数,数值越小,进程数越多
assignment_list = []
fin_search_list_len = len(fin_search_list)
for i in range(0, fin_search_list_len, project_num):
start = i
end = i+project_num
assignment_list.append(fin_search_list[start: end]) # 获取列表碎片
return assignment_list
En configurant le pool de processus pour qu'il explore en parallèle, le temps est réduit à 3/1 du temps d'analyse d'un processus unique, et le temps total est de 3h.
L'ordinateur a des cœurs 4. Après le test, lorsque le nombre de tâches est de 3, l'efficacité de fonctionnement de l'ordinateur actuel est la plus élevée.
5. Stockez les résultats de l'exploration dans Excel et attendez le traitement visuel des données
# 存储抓取结果
def save_excel(fin_info_list, file_name):
tag_name = ['区域', '板块', '地铁', '标题', '位置', '平米', '户型', '楼层', '总价', '单位平米价格']
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
tmp = book.add_worksheet()
row_num = len(fin_info_list)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_info_list[i-1] # -1是因为被表格的表头所占
tmp.write_row(con_pos, content)
book.close()

Résumer:
Lorsque l'échelle des données capturées est plus grande, les exigences pour la logique du programme sont plus rigoureuses et les exigences pour la syntaxe python sont plus compétentes. Comment écrire une grammaire plus pythonique nécessite également un apprentissage et une maîtrise continus.
