Gestion des métadonnées
Qu'est-ce que les métadonnées
- Dans HDFS, les métadonnées sont principalement des métadonnées liées aux fichiers, qui sont gérées et maintenues par le nœud de nom. D'un point de vue général, étant donné que le namenode doit également gérer de nombreux nœuds DataNode, les informations d'emplacement et d'état de santé du DataNode appartiennent également aux métadonnées.
Présentation de la gestion des métadonnées
Dans HDFS, il existe deux types de métadonnées liées aux fichiers :
- Nom du fichier d'informations sur les attributs du fichier
, autorisations, heure de modification, taille du fichier, facteur de réplication, taille du bloc de données - Les informations de mappage de l'emplacement des blocs de fichiers
enregistrent les informations de mappage entre les blocs de fichiers et le DataNode, c'est-à-dire quel bloc se trouve sur quel nœud. Selon la
forme de stockage, il existe deux types : les métadonnées de la mémoire et les fichiers de métadonnées, qui sont stockés en mémoire et sur le disque. respectivement.
Métadonnées de la mémoire
- Afin de garantir une interaction utilisateur efficace et une faible latence lors de l'utilisation des métadonnées, le nœud de nom stocke toutes les métadonnées en mémoire, que nous appelons métadonnées de mémoire. Les métadonnées en mémoire sont les plus complètes, y compris les attributs de fichier et les informations de mappage d'emplacement de bloc de fichier.
- Mais le problème fatal de la mémoire est que les données des points d'arrêt sont perdues et qu'elles ne seront pas conservées. Par conséquent, le nœud de nom aide avec les fichiers de métadonnées pour garantir la sécurité et l'intégrité du bureau des transports.
fichier de métadonnées
Il existe deux types de fichiers de métadonnées : le fichier image mémoire fsimage et le journal des modifications.
fichier image mémoire fsimage
- Il s'agit d'un point de contrôle persistant des métadonnées de la mémoire. Cependant, fsimage ne contient que des informations de métadonnées liées aux attributs du fichier lui-même dans le fichier hadoop, mais ne contient pas d'informations sur l'emplacement du bloc de fichier. Les informations sur l'emplacement des blocs de fichiers sont uniquement stockées en mémoire. Elles sont obtenues en signalant les blocs de données à DataNode lorsque DataNode commence à rejoindre le cluster, et les rapports ultérieurs sur les blocs de données sont effectués à des intervalles spécifiés.
- L'action de persistance est le processus d'E/S des données de la mémoire vers le disque. Cela aura un certain impact sur le service normal du nœud de nom et ne pourra pas être conservé fréquemment.
modifie le journal logedit
Afin d'éviter le problème de perte de données entre deux persistances, le fichier journal d'édition du journal des modifications est conçu. Ce qui est enregistré dans le fichier est le journal de toutes les opérations de modification (création, suppression ou modification de fichier) de HDFS. Les opérations de modification effectuées par le client du système de fichiers seront d'abord enregistrées dans le fichier d'édition.
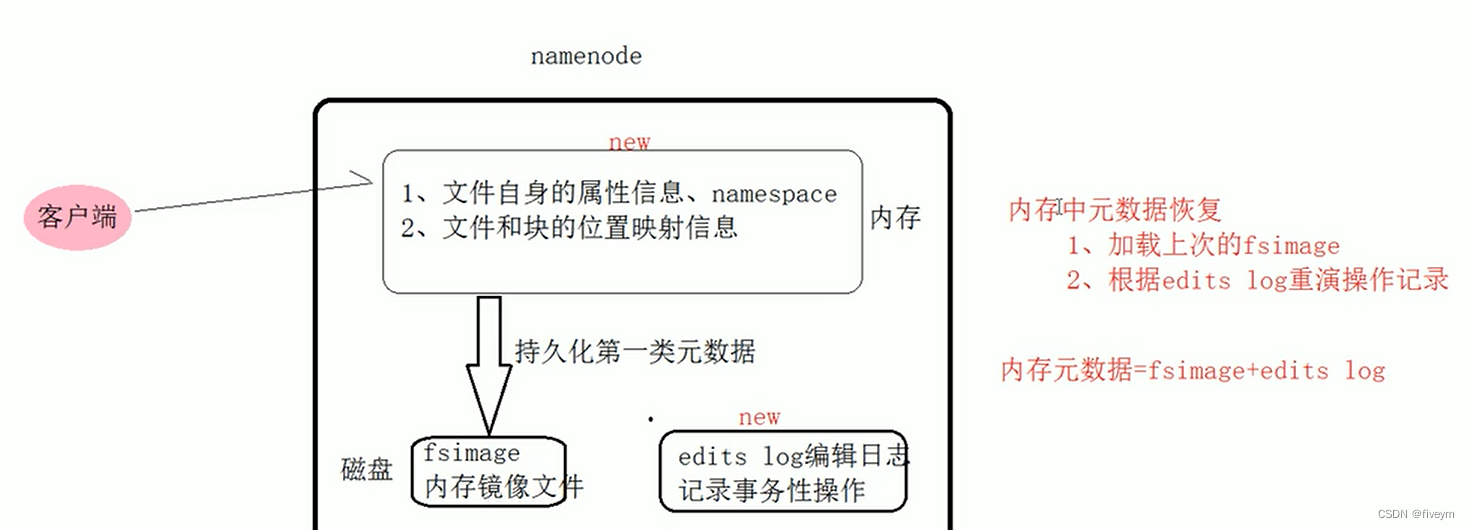
Namenode charge l'ordre des fichiers de métadonnées
- Les fichiers fsimage et les fichiers d'édition sont sérialisés. Lorsque le nœud de nom démarre, il chargera le contenu du fichier fsimage dans la mémoire, puis effectuera diverses opérations dans le fichier d'édition pour comparer les métadonnées en mémoire avec la synchronisation réelle, les métadonnées stockées en mémoire prend en charge les opérations de lecture du client et constitue également les métadonnées les plus complètes.
- Lorsque le client ajoute ou modifie un fichier dans HDFS, l'enregistrement de l'opération est d'abord inclus dans le fichier journal des modifications. Lorsque l'opération du client réussit, les métadonnées correspondantes seront mises à jour dans les métadonnées de la mémoire. Étant donné que les fichiers fsimage sont généralement très volumineux (le niveau Go est très courant), si toutes les opérations de mise à jour sont ajoutées au fichier fsimage, le système fonctionnera très lentement.
- La conception et la mise en œuvre de HDFS se concentrent sur : premièrement, une mise à jour rapide des données et une requête en mémoire, ce qui réduit considérablement le temps de réponse de l'opération ; deuxièmement, le risque de perte de métadonnées en mémoire est élevé (panne de courant T_T), ce qui facilite l'image des métadonnées. fichier (fsimage) + Mécanisme de sauvegarde pour les fichiers journaux d'édition (modifications) pour garantir la sécurité des métadonnées
- Le nœud de nom conserve l'intégralité des métadonnées du système de fichiers. Par conséquent, la gestion précise des métadonnées affecte la capacité de HDFS à fournir des services de stockage de fichiers.
Fichiers de catalogue liés à la gestion des métadonnées
-
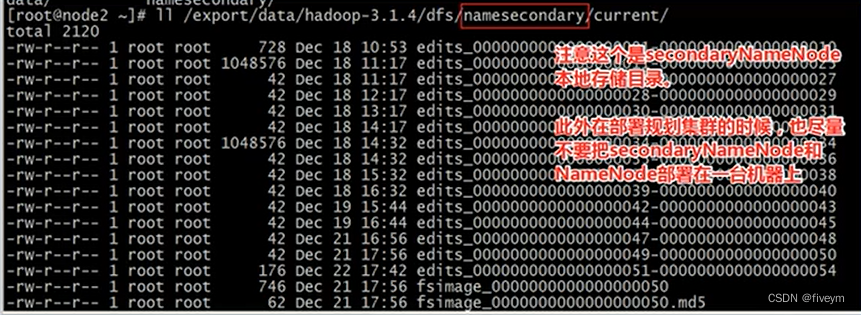
Le répertoire de stockage des métadonnées du namenode est spécifié par le paramètre : dfs.namenode.name.dir
-
Une fois le formatage terminé, les fichiers suivants seront créés dans le répertoire $hdfs.namenode.name.dir/current :

-
dfs.namenode.name.dir est configuré dans le fichier hdfs-site.xml. La valeur par défaut est la suivante

Fichiers liés aux métadonnées
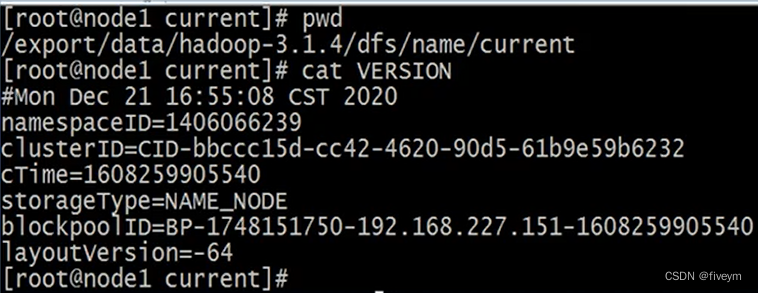
VERSION
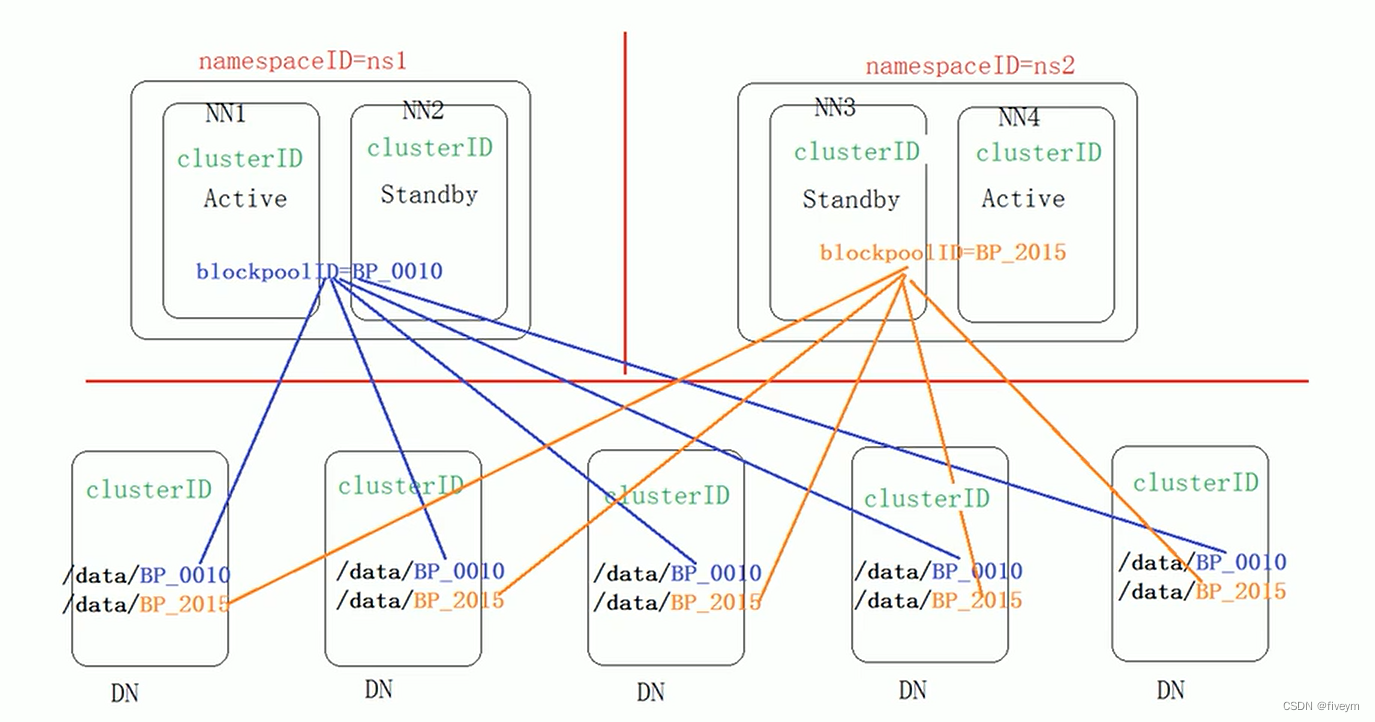
- namespaceID/clusterID/blockpollID
sont les identifiants uniques du cluster HDFS. L'identifiant est utilisé pour empêcher DataNodes de s'enregistrer accidentellement auprès d'un namenode dans un autre cluster. Ces gemmes sont particulièrement importantes dans les déploiements de fédération. En mode fédéré, plusieurs nœuds de noms fonctionneront indépendamment. Chaque nœud de nom fournit un ID d'espace de noms unique et gère un ensemble unique de pools de blocs de fichiers (blockpoolID). Le clusterID lie l’ensemble du cluster en une seule unité logique et est le même sur tous les nœuds du cluster. - storageType
indique les informations sur la structure des données de processus que ce fichier stocke. S'il s'agit d'un nœud DataNode, storageType=DATA_NODE - cTime
heure de création du système de stockage du nœud de nom, cet attribut est 0 lorsque le système de fichiers est formaté pour la première fois, lorsqu'on lui demande l'horodatage après la mise à niveau du système de fichiers - layoutVersion
La version du format de métadonnées HDFS. HDFS sera mis à jour lors de sa mise à niveau
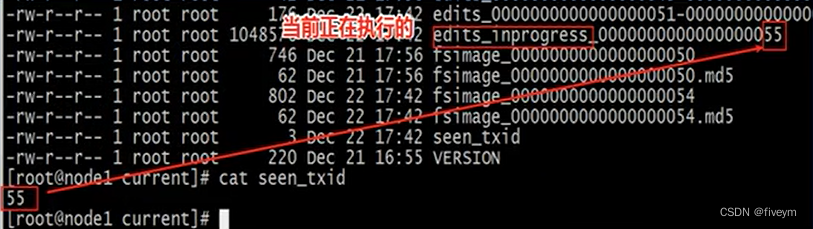
vu_txid
- Contient le dernier ID de transaction du dernier point de contrôle, qui n'est pas le dernier ID de transaction accepté par le nœud de nom.
- Le contenu de saw_txid ne sera pas mis à jour à chaque opération transactionnelle, mais ne sera mis à jour que lors du point de contrôle.
- Lorsque le nœud de nom démarre, il vérifie le fichier saw_txid pour vérifier qu'il peut charger au moins ce nombre de transactions. Si la transaction de chargement ne peut pas être vérifiée, le nœud de nom mettra fin au démarrage
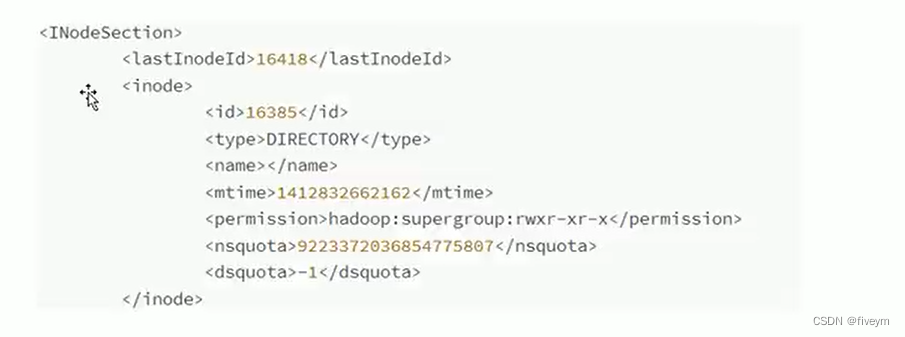
Visualisation des fichiers de métadonnées (OIV, OEV)
- Le fichier fsimage est un point de contrôle permanent des métadonnées du système de fichiers Hadoop. Il contient les informations sérialisées de tous les répertoires et identifiants de fichiers du système de fichiers Hadoop ; pour les fichiers, les informations incluses incluent l'heure de modification, l'heure d'accès et la taille du bloc. une information de blocage de fichier, etc. ; pour les répertoires, elle contient principalement des informations telles que l'heure de modification, les autorisations de contrôle d'accès, etc.
- oiv est l'abréviation de visionneuse d'images hors ligne, qui peut vider le contenu des fichiers hdfs fsimage dans un format lisible par l'homme.
- Commandes couramment utilisées : hdfs oiv -i fsiamge_00000000000050 -p XML -o fsimage.xml
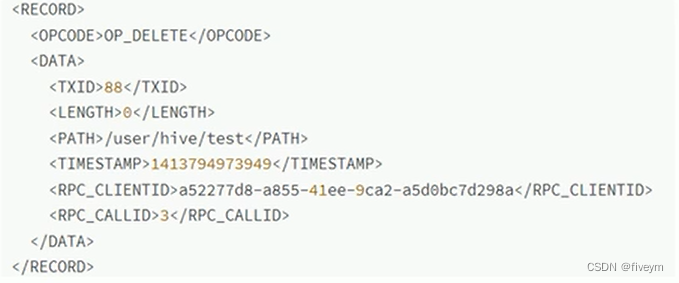
- Le fichier journal des modifications stocke tous les journaux d'opérations mis à jour du système de fichiers Hadoop.
- Toutes les opérations d'écriture effectuées par le client du système de fichiers sont d'abord enregistrées dans le fichier d'éditions.
- oev est l'abréviation de visionneuse de modifications hors ligne (visualiseur de modifications hors ligne). Cet outil ne nécessite pas l'exécution du cluster Hadoop.
- Commande : hdfs oev -i edits_00000000000000000090-00000000000000000000089 -o edits.xml
- Dans le fichier de sortie, chaque RECORD enregistre une opération. L'exemple est le suivant :
Introduction à SecondNameNode
- SNN peut réduire la taille du fichier des journaux d'édition et obtenir un dernier fichier fsimage, ce qui réduira également la pression sur le nœud de nom.
mécanisme de point de contrôle
1. Le cœur de Checkpoint est le processus de fusion de fsimage et du journal des modifications pour générer un nouveau fsimage. Ensuite, NN générera un nouveau fichier journal des modifications : nouvelles modifications pour faciliter l'enregistrement des opérations ultérieures. 2. SNN fusionnera l'ancien fichier journal des modifications. avec le précédent
. Copiez l'image fs dans son propre local (en utilisant la méthode HTTP GET)
3. SNN charge d'abord l'image fs dans la mémoire, puis exécute les opérations dans le fichier d'édition une par une, de sorte que l'image fs dans la mémoire soit constamment mis à jour. Ce processus est la fusion des fichiers d'édition et des fichiers fsimage. . Une fois la fusion terminée, SNN vide les données dans la mémoire pour générer un nouveau fichier fsimage
4. SNN copie le nouveau fichier Fimage sur le nœud NN. Jusqu'à présent, il ne s'agit que d'un cycle, attendant le prochain point de contrôle pour déclencher le fonctionnement du nœud de nom secondaire, et le cycle continue ainsi.
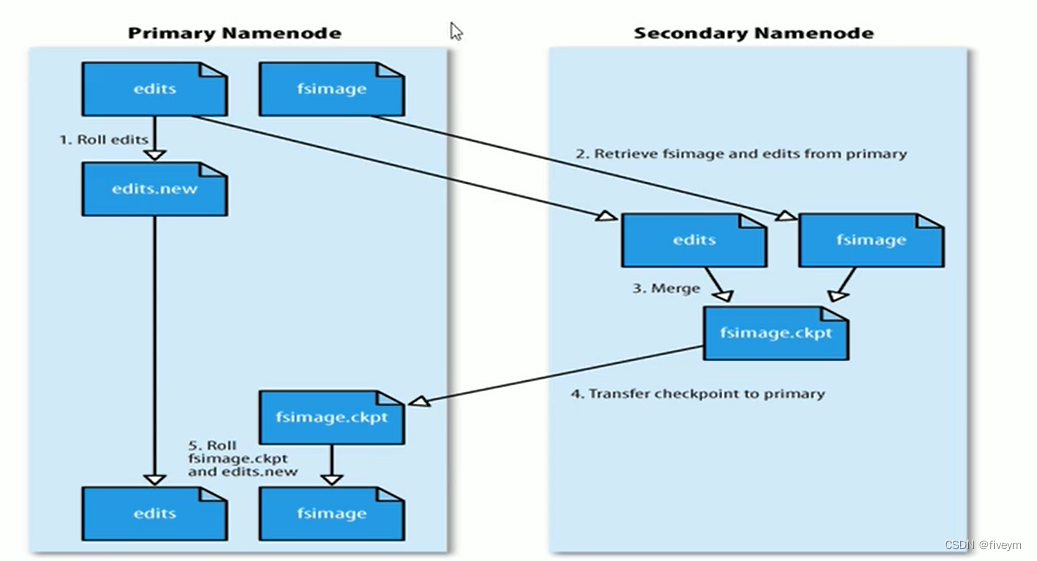
Mécanisme de déclenchement du point de contrôle SNN
- core-site.xml
dfs.namenode.checkpoint.period=3600 //L'intervalle de temps entre deux points de contrôle consécutifs. La valeur par défaut est d'une heure
. dfs.namenode.checkpoint.txns=1000000 //Le nombre maximum de transactions de point de contrôle qui n'ont pas été exécutées forcera l'exécution d'un point de contrôle d'urgence si le cycle de point de contrôle est atteint. Le nombre de transactions par défaut est de 1 million
Récupération de fichiers de métadonnées
namenode stocke plusieurs répertoires
- Le répertoire de stockage des métadonnées du namenode est déterminé par le paramètre : dfs.namenode.name.dir
- L'attribut dfs.namenode.name.dir peut configurer plusieurs répertoires. La structure des fichiers et le contenu stockés dans chaque répertoire sont exactement les mêmes, ce qui équivaut à une sauvegarde. L'avantage est que lorsque l'un des répertoires est cassé, il n'affectera pas les métadonnées Hadoop.Données, notamment lorsqu'un des répertoires est sur NFS (système de fichiers réseau), même si votre machine est endommagée, les métadonnées seront sauvegardées
Récupérer à partir de SNN
- Lorsque SNN reçoit le point de contrôle, il télécharge fsimage et modifie le journal dans le répertoire de stockage local sur sa propre machine. Et il ne sera pas supprimé après le point de contrôle
- Si quelque chose ne va pas avec la fsimage dans NN, vous pouvez toujours remplacer la fsimage dans NN par la fsimage dans SNN. Bien qu'il ne s'agisse plus de la dernière fsimage, nous pouvons minimiser la perte.