Répertoire d'articles
Préface
Afin de résoudre la maintenance et la gestion de plusieurs clusters sous HDFS Federation, la communauté Hadoop a implémenté la fonction Router-Based Federation (HDFS-10467) . La puissance de cette fonction est qu'elle ajoute une nouvelle couche de service de routeur entre le client et le service NN du cluster. Avec ce service de routeur, toutes les demandes des clients seront transmises aux nœuds NN en aval par ce routeur. Dans ce cas, l'utilisateur client n'a pas besoin de savoir quels nœuds NN sont en aval et quel type de données est distribué dans chaque espace de noms NN. Le routeur effectuera ces tâches de manière transparente pour le client. Étant donné que le routeur effectue principalement la transmission de la demande ici, il est lié pour avoir les étapes d'établissement d'une nouvelle connexion avec le NN en aval, puis de la transmission de la demande. La question est donc de savoir comment le routeur gère-t-il cela? S'il s'agit d'une demande client à chaque fois, le routeur établit une nouvelle connexion pour demander le NN, cela signifie que le routeur fera beaucoup d'opérations de rétablissement de connexion, ce qui n'est évidemment pas une approche efficace. Une approche plus efficace consiste à maintenir une certaine connexion par le routeur lui-même, puis à réutiliser la connexion autant que possible pour demander le NN. Mais cela augmentera sans aucun doute le travail de gestion de Router Connection, et le problème de fuite de connexion doit être évité ici. L'auteur de cet article parlera brièvement du contenu de la gestion de la connexion du routeur, de la manière dont le routeur parvient à une gestion de la connexion efficace et sécurisée.
Compromis de gestion des connexions
En ce qui concerne la gestion des connexions, il y aura toujours un compromis: devez-vous maintenir autant de connexions que possible ou maintenir le moins de connexions possible? Plus de connexion signifie un taux de réutilisation plus élevé, mais en même temps, cela peut entraîner un trop grand nombre de connexions inactives pour affecter le service en aval lui-même.
Par conséquent, la gestion des connexions n'est pas ici une approche universelle. Il n'y a pas de fixe indiquant combien de connexions ouvertes actuelles doivent être mises en cache, mais une approche de gestion plus flexible et flexible. En termes simples, lorsque nous devons établir plus de connexions, nous essayons de mettre ces connexions en cache. Mais lorsque nous constatons que de nombreuses connexions ne sont pas utilisées dans un laps de temps, nous les fermons et les nettoyons à temps. La gestion des connexions de RBF utilise cette stratégie intelligemment.
Gestion des connexions de RBF
Division Pool de connexion à granularité fine
En mode RBF, le routeur doit faire face aux demandes RPC de différents clients d'une part, et d'autre part, il doit également transmettre les demandes à plusieurs nœuds NN d'espace de noms. Afin de réaliser l'isolement de la connexion entre différents espaces de noms et différents utilisateurs, le routeur effectue ici l'isolement de la connexion en fonction du niveau utilisateur / espace de noms / protocole. En termes simples, Router crée ConnectionPool conformément aux trois dimensions mentionnées ci-dessus, puis chaque ConnectionPool gère la connexion elle-même.
Création de connexion
En ce qui concerne la gestion des connexions, il ne s’agit que de deux aspects majeurs du traitement, l’un est la création de la connexion et l’autre est le nettoyage de la connexion. Ici, nous examinons d'abord la création de connexion.
Le routeur tente de créer la connexion s'il constate que la connexion disponible n'est pas suffisante à chaque fois qu'il obtient la connexion. Le code correspondant est le suivant:
public ConnectionContext getConnection(UserGroupInformation ugi,
String nnAddress, Class<?> protocol) throws IOException {
...
// 1) 根据user+ns+protocol拼出connectionPoolId
ConnectionPoolId connectionId =
new ConnectionPoolId(ugi, nnAddress, protocol);
ConnectionPool pool = null;
readLock.lock();
try {
// 2) 根据connectionPoolId取出对应的ConnectionPool
pool = this.pools.get(connectionId);
} finally {
readLock.unlock();
}
// Create the pool if not created before
if (pool == null) {
...
}
// 3) 取出一个connection
ConnectionContext conn = pool.getConnection();
// Add a new connection to the pool if it wasn't usable
if (conn == null || !conn.isUsable()) {
// 4) 如果connection不可用,则将connection pool加入队列让其进行connection的异步创建
if (!this.creatorQueue.offer(pool)) {
LOG.error("Cannot add more than {} connections at the same time",
this.creatorQueueMaxSize);
}
}
if (conn != null && conn.isClosed()) {
LOG.error("We got a closed connection from {}", pool);
conn = null;
}
return conn;
}
Comme indiqué dans le code ci-dessus, la file d'attente creatorQueue est utilisée pour stocker temporairement le pool de connexions à créer. Cette file d'attente sera utilisée dans le thread qui crée la connexion ci-dessous.
/**
* Thread that creates connections asynchronously.
*/
static class ConnectionCreator extends Thread {
...
@Override
public void run() {
while (this.running) {
try {
// 从queue中获取connection pool
ConnectionPool pool = this.queue.take();
try {
int total = pool.getNumConnections();
int active = pool.getNumActiveConnections();
float poolMinActiveRatio = pool.getMinActiveRatio();
// 判断此pool内
// 1) 前活跃的connection数超过最小阈值
// 2) connection总数不超过最大值限制的话
// 则进行新的connection的创建
if (pool.getNumConnections() < pool.getMaxSize() &&
active >= poolMinActiveRatio * total) {
ConnectionContext conn = pool.newConnection();
pool.addConnection(conn);
} else {
LOG.debug("Cannot add more than {} connections to {}",
pool.getMaxSize(), pool);
}
} catch (IOException e) {
LOG.error("Cannot create a new connection", e);
}
} catch (InterruptedException e) {
LOG.error("The connection creator was interrupted");
this.running = false;
} catch (Throwable e) {
LOG.error("Fatal error caught by connection creator ", e);
}
}
}
Le point le plus ingénieux de l'implémentation ci-dessus est qu'elle définit le seuil minimum de connexion active pour garantir que la nouvelle connexion ne deviendra pas une connexion inutile à l'avenir.
Nettoyage de connexion
Un autre aspect de la gestion des connexions est le nettoyage de la connexion. Le routeur utilise ici une planification de tâches périodiques pour nettoyer la connexion.
this.cleaner.scheduleAtFixedRate(
new CleanupTask(), 0, recyleTimeMs, TimeUnit.MILLISECONDS);
La logique du code de la tâche de nettoyage CleanupTask est la suivante:
/**
* Removes stale connections not accessed recently from the pool. This is
* invoked periodically.
*/
private class CleanupTask implements Runnable {
@Override
public void run() {
long currentTime = Time.now();
List<ConnectionPoolId> toRemove = new LinkedList<>();
// Look for stale pools
readLock.lock();
try {
for (Entry<ConnectionPoolId, ConnectionPool> entry : pools.entrySet()) {
// 1)根据最近一次的活跃时间,查找那些过期的不活跃的connection pool
ConnectionPool pool = entry.getValue();
long lastTimeActive = pool.getLastActiveTime();
boolean isStale =
currentTime > (lastTimeActive + poolCleanupPeriodMs);
// 2)如果查找到的情况,则加入pool移除列表
if (lastTimeActive > 0 && isStale) {
// Remove this pool
LOG.debug("Closing and removing stale pool {}", pool);
pool.close();
ConnectionPoolId poolId = entry.getKey();
toRemove.add(poolId);
} else {
// 3)如果当前connection pool还是活跃在使用的话,则继续进行此pool内无用connection的清理
LOG.debug("Cleaning up {}", pool);
cleanup(pool);
}
}
} finally {
readLock.unlock();
}
// Remove stale pools
if (!toRemove.isEmpty()) {
writeLock.lock();
try {
for (ConnectionPoolId poolId : toRemove) {
pools.remove(poolId);
}
} finally {
writeLock.unlock();
}
}
}
}
La logique de nettoyage ci-dessus nettoie les connexions inutiles du pool de connexions obsolètes aux connexions inactives dans le pool. Cela peut éviter l'existence d'un trop grand nombre de connexions invalides.
Enfin, il existe un schéma simplifié de la gestion des connexions au routeur: ce qui
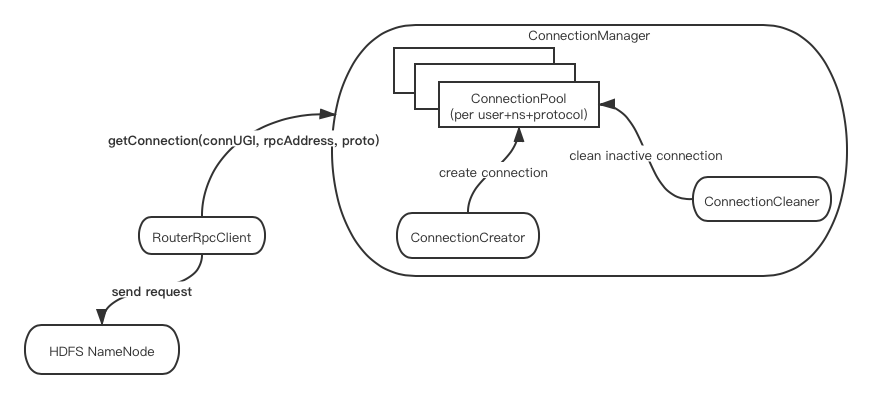
précède est tout le contenu à expliquer dans cet article. Les codes mentionnés ci-dessus proviennent tous de la classe ConnectionManager du lien de référence ci-dessous. Les étudiants intéressés peuvent lire et apprendre par eux-mêmes .
Référence
[1] .https: //github.com/apache/hadoop/blob/trunk/hadoop-hdfs-project/hadoop-hdfs-rbf/src/main/java/org/apache/hadoop/hdfs/server/federation/ router / ConnectionManager.java