Lien d'origine : https://arxiv.org/abs/2308.04556
1. Introduction
Les méthodes actuelles de détection d’objets 3D ne prennent pas explicitement en compte le problème de détection manquée.
Cet article propose la détection d'instance dure (HIP). Inspiré des têtes de décodage en cascade de détection de cible, HIP détecte progressivement les faux échantillons de détection et améliore considérablement le taux de rappel. À chaque étape, HIP supprime les échantillons TP et se concentre sur les échantillons FN de l'étape précédente, puis en itérant HIP, les échantillons FN difficiles peuvent être traités.
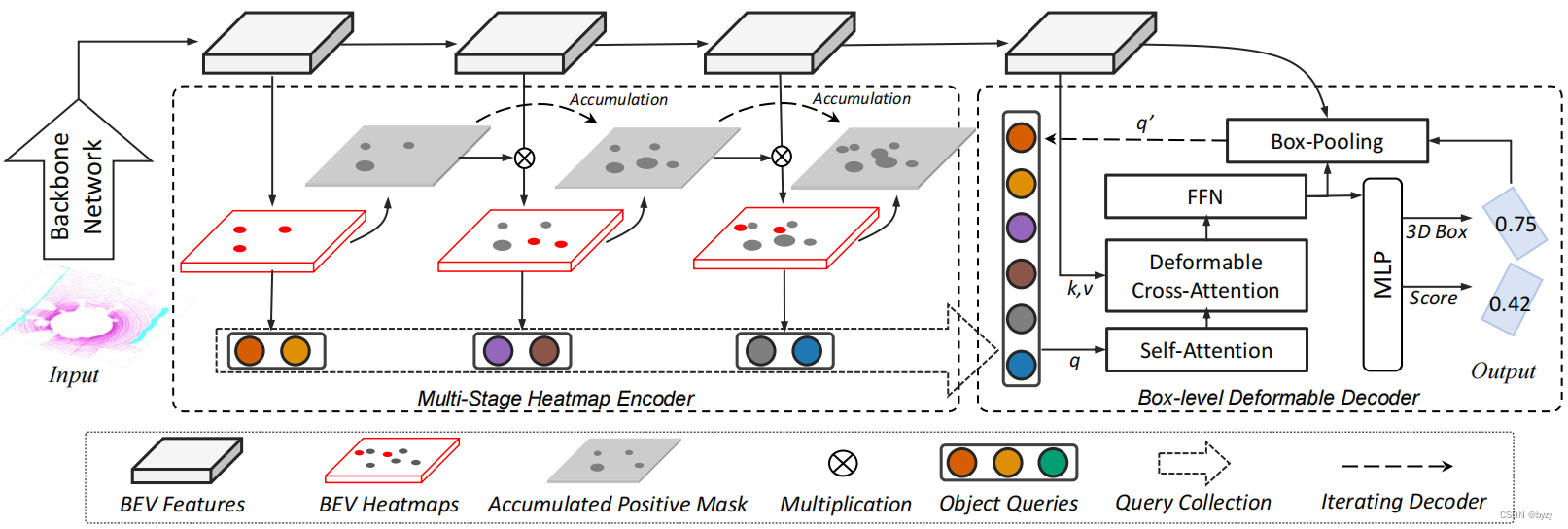
Basé sur HIP, cet article propose une détection de cible 3D appelée FocalFormer3D, comme le montre la figure ci-dessous. La prédiction de la carte thermique en plusieurs étapes est utilisée pour exploiter les instances difficiles. FocalFormer3D conserve un masque d'échantillons positifs accumulés pour indiquer les zones d'échantillons positifs des étapes précédentes, de sorte que le réseau ignore la formation sur les échantillons faciles et se concentre sur les instances difficiles (FN). Enfin, le réseau collecte les prédictions positives de toutes les étapes pour générer des objets candidats.
De plus, cet article propose également une étape de raffinement au niveau de la boîte englobante pour éliminer les objets candidats redondants. À l'aide d'un décodeur Transformer déformable, les objets candidats sont exprimés sous forme de requêtes au niveau de la boîte englobante via RoIAlign pour une interaction de requête au niveau de la boîte englobante et un raffinement itératif de la boîte englobante. Enfin, une stratégie de nouvelle notation est utilisée pour sélectionner les instances positives parmi les objets candidats.
3. Méthode
3.1 Détection d'instance matérielle (HIP)
Représentation d'une détection d'échantillon difficile : étant donné un objet réel O = { oi } i = 1 NGT \mathcal{O}=\{o_i\}_{i=1}^{N_GT}Ô={
oje}je = 1NGT, qui est l'objectif principal de la phase initiale. Étant donné un ensemble d'objets candidats A = { ai } i = 1 NOC \mathcal{A}=\{a_i\}_{i=1}^{N_OC}UN={
unje}je = 1NÔC(peut être une boîte d'ancrage, un point d'ancrage ou une requête d'objet), le réseau neuronal prédit sa positivité. Laissez kthL'échantillon positif prédit à l'étape k est P = { pi } i = 1 NP \mathcal{P}=\{p_i\}_{i=1}^{N_P}P.={
pje}je = 1NP, des objets réels peuvent être attribués à des objets prédits, et la catégorie est déterminée pour la boîte englobante réelle en fonction de l'affectation : O k TP = { oj ∣ ∃ pi ∈ P k , σ ( pi , oj ) > η } \mathcal{ O}_k^{ TP}=\{o_j|\exist p_i\in \mathcal{P}_k,\sigma(p_i,o_j)>\eta\}ÔkTP={
oj∣∃p _je∈P.k,s ( pje,oj)>η } oùσ( ⋅ , ⋅ ) \sigma(\cdot, \cdot)σ ( ⋅ ,⋅ ) est l'indice de correspondance (tel que IoU ou distance centrale),η \etaeta est un seuil prédéfini. Ensuite, les cibles restantes sans correspondance peuvent être considérées comme des instances difficiles : O k FN = O − ⋃ i = 1 k O k TP \mathcal{O}_k^{FN}=\mathcal{O}-\bigcup_{i=1 } ^k\mathcal{O}_k^{TP}ÔkFR=Ô−je = 1⋃kÔkTPkième + 1 k+1k+Le but d' une étape de la formation est de détecterO k FN \mathcal{O}_k^{FN}ÔkFR, tout en ignorant les prédictions positives.
Étant donné que cet article collecte des objets candidats à différentes étapes, le module de raffinement au niveau objet de la deuxième étape est nécessaire pour éliminer FP.
3.2 Encodeur de carte thermique à plusieurs étages
Connaissance préparatoire de la carte thermique centrale en perception BEV : Le but de la carte thermique centrale est de générer un pic de carte thermique au centre de l'objet. La carte thermique BEV utilise le tenseur S ∈ RX × Y × CS\in\mathbb{R}^{X\times Y\times C}S∈R.Expression X × Y × C , où X × YX\times YX×Y est la taille de la carte des caractéristiques BEV,CCC est le nombre de catégories. La carte thermique cible est obtenue en générant une gaussienne 2D à proximité du point de projection BEV de l'objet.
Accumulation de masque d'échantillon positif : afin de suivre les candidats positifs, cet article initialise un masque d'échantillon positif (PM) entièrement nul sur BEV et l'accumule en fonction de l'étape pour obtenir le masque d'échantillon positif accumulé (APM) : M ^ k ∈ { 0 , 1 } X × Y × C \hat{M}_k\in\{0,1\}^{X\times Y\times C}M^k∈{
0 ,1 } Les caractéristiques BEV multi-étages X × Y × C sont obtenues en concaténant des blocs résiduels inverses légers entre les étages. En ajoutant une couche convolutive supplémentaire, une carte thermique BEV à plusieurs étapes peut être obtenue. Selon les résultats de prédiction d'échantillon positif, les réponses de la carte thermique BEV sont triées par scores pour générer un masque d'échantillon positif. Plus précisément, aukthk stage, carte thermique BEV toutes positions, top KKdans toutes les catégoriesK réponses sont sélectionnées comme résultats de prédiction d'objetP k \mathcal{P}_kP.k. Le masque d'échantillon positif enregistre toutes les prédictions positives pi ∈ P k p_i\in\mathcal{P}_kpje∈P.kposition (x, y) (x, y)( x ,y ) et catégorieccc , et définissez la valeur de la position et de la catégorie correspondantes du masque sur 1 (M ( x , y , c ) = 1 M_{(x,y,c)}=1M( x , y , c )=1 ), et les positions restantes sont mises à 0.
Le schéma de génération de masque ci-dessus ne remplit que les points centraux de l'objet candidat, appelémasque de points. Cet article propose deux autres schémas de génération de masques :
- Masque basé sur le pooling : les petits objets remplissent le point central de l'objet candidat, les gros objets utilisent 3 × 3 3\times33×Remplissage de noyau de 3 tailles.
- Masques de cadre de délimitation : ajoutez une branche de prédiction de cadre de délimitation supplémentaire à chaque étape, et le masque remplit la région interne du cadre de délimitation prédit.
Non.kk _Le masque d'échantillon positif accumulé de la couche k est généré comme suit : M ^ k = max 1 ≤ i ≤ k M i \hat{M}_k=\max_{1\leq i\leq k}M_iM^k=1 ≤ je ≤ kmaximumMjeEnsuite, les zones d'échantillon positives de la carte thermique peuvent être filtrées et se concentrer sur les instances difficiles comme suit : S ^ k = S k ⋅ ( 1 − M ^ k ) \hat{S}_k=S_k\cdot(1-\hat {M} _k)S^k=Sk⋅( 1−M^k) Lors de la formation de l'encodeur de carte thermique, utilisez la perte focale gaussienne pour chaque couche et résumez-la pour obtenir la perte totale de la carte thermique.
Les objets candidats de toutes les étapes sont collectés et envoyés à la deuxième étape, où ils sont à nouveau notés et le FP est supprimé.
Discussion sur la mise en œuvre efficace du HIP : La méthode de masquage doit répondre aux conditions suivantes pour garantir l'efficacité du HIP :
- Exclure les anciens objets candidats positifs au stade actuel ;
- Évitez de supprimer des objets potentiellement réels.
Le masque de points satisfait aux conditions ci-dessus, mais n'exclut qu'un seul objet candidat BEV par prédiction positive par rapport au masque idéal utilisant le véritable masque de boîte englobante. Par conséquent, la méthode de masquage basée sur le pooling est plus efficace.
3.3 Décodeur déformable au niveau du cadre de délimitation
Les objets candidats peuvent être visualisés sous forme de requêtes d'objets avec des informations de localisation. L'augmentation du nombre d'objets candidats peut augmenter le taux de rappel, mais une détection redondante augmentera le FP.
Cet article modélise les objets candidats sous forme de requêtes au niveau de la boîte englobante et utilise l'attention déformable pour améliorer l'efficacité.
Module de pooling de boîtes englobantes : utilisez RoIAlign pour extraire les informations contextuelles de la boîte englobante à partir des fonctionnalités BEV. Plus précisément, étant donné la boîte prédite, chaque requête d'objet extrait 7 × 7 7\times7 de la boîte englobante BEV7×7 points de grille de fonctionnalités et passé par MLP à 2 couches. L'encodage de position est ajouté aux requêtes et aux points de grille.
Implémentation du décodeur : similaire à Deformable DETR, cet article utilise l'auto-attention multi-têtes et l'attention déformable multi-têtes. L'attention déformable échantillonne les caractéristiques sur les cartes de caractéristiques BEV à 3 échelles. Le module de regroupement de boîtes englobantes échantillonne dans chaque boîte englobante BEV pivotée et ajoute les fonctionnalités à l'intégration de requêtes après avoir traversé 2 couches de FC. Lors de l'échantillonnage, la boîte englobante est agrandie à 1,2 fois sa taille d'origine.
3.4 Formation sur modèle
Le modèle est formé en deux étapes. La première étape utilise la tête de décodage Transformer pour entraîner le réseau fédérateur lidar (le modèle correspondant s'appelle DeformFormer3D). Utilisez ensuite les poids de DeformFormer3D pour initialiser FocalFormer3D et entraîner l'encodeur de carte thermique multi-échelle et le décodeur au niveau de la boîte englobante. Cependant, lors de l’utilisation d’un décodeur déformable avec correspondance de graphes bipartis, une convergence lente se produit dans les premiers stades de la formation. Par conséquent, cet article génère des requêtes bruitées à partir d’objets réels pour résoudre ce problème. De plus, les paires correspondantes dont l'entraxe est supérieur à une certaine valeur seront exclues de la correspondance.
4. Expérimentez
4.1 Configuration expérimentale
Ensembles de données et indicateurs : En plus des indicateurs officiels, un indicateur de rappel moyen (AR) défini par l'entraxe est également ajouté à l'ensemble de données nuScenes.
4.2 Principaux résultats
NuScenes Détection de cible 3D basée sur lidar : Cette méthode peut atteindre SotA. Atteint toujours de meilleures performances que les modèles entraînés avec des annotations supplémentaires au niveau de la segmentation.
Détection de cible 3D multimodale nuScenes : cet article utilise des squelettes d'image pré-entraînés pour extraire les caractéristiques de l'image, met à niveau les caractéristiques de l'image vers un espace voxel prédéfini et les fusionne avec des fonctionnalités BEV basées sur lidar. Lorsque l'augmentation des données au moment du test (TTA) n'est pas effectuée, la méthode décrite dans cet article peut avoir de meilleures performances que sota et prendre moins de temps d'inférence ; elle a de meilleures performances sur certaines catégories rares.
Suivi de cible nuScenes3D : l'utilisation de SimpleTrack, un algorithme de suivi basé sur la détection, peut être meilleure que sota dans le passé ; de plus, FocalFormer3D utilisant TTA peut être meilleure que BEVFusion en utilisant l'intégration de modèles.
Détection de cible Waymo lidar 3D : Le modèle de cet article peut obtenir des résultats compétitifs sans affiner les hyperparamètres du modèle.
4.3 Analyse du taux de rappel
Comparaison de rappel d'objets candidats : FocalFormer3D utilisant une seule modalité lidar surpasse les méthodes multimodales.
Comparaison du taux de rappel de la prédiction finale : À mesure que le seuil de distance augmente, le taux de rappel de la prédiction finale (par rapport au taux de rappel des objets candidats) de la plupart des méthodes diminue. Le taux de rappel de cette méthode peut dépasser considérablement les méthodes précédentes.
Comparaison de rappel classe par classe : Par rapport à TransFusion-L, FocalFormer3D a un taux de rappel plus élevé sur les gros objets.
4.4 Études sur l'ablation
Taille des requêtes HIP et étapes de génération : augmenter le nombre de couches HIP ou le nombre total de requêtes peut améliorer les performances.
Type de masque d'échantillon positif : un masque à point unique peut améliorer la méthode sans masque ; l'utilisation d'un masque basé sur un regroupement peut encore améliorer les performances.
Affinement progressif : bien que le modèle ajoutant un encodeur de carte thermique à plusieurs étages ait un rappel significativement plus élevé par rapport à CenterPoint, l'amélioration de mAP et NDS est faible. En utilisant la réévaluation au niveau de l'objet et l'alignement basé sur la RoI, les performances peuvent être encore améliorées ; l'utilisation de décodeurs déformables au niveau de la boîte englobante peut grandement améliorer les performances.
Pour évaluer l'effet de la nouvelle notation, cet article a conçu une autre expérience dans laquelle seule la nouvelle notation a été effectuée pendant la phase de raffinement pour exclure l'influence de la régression de la boîte englobante. Les expériences montrent que cette méthode présente une amélioration significative des performances par rapport au modèle sans étape de raffinement. Cela illustre les limites de la notation par carte thermique dans la phase initiale. Une deuxième étape de re-notation est donc utile.
Analyse de latence des composants du modèle : le temps de calcul principal est situé dans le réseau fédérateur lidar basé sur une convolution clairsemée, tandis que l'encodeur de carte thermique à plusieurs étages et le décodeur déformable au niveau du cadre de délimitation occupent une proportion inférieure.
5. Discussion
Limites : la méthode HIP décrite dans cet article doit générer une carte thermique avec un pic au centre de l'objet, ce qui peut ne pas convenir à la détection par caméra, car la carte thermique de la caméra peut être en forme d'éventail.
annexe
A. Expériences d'ablation supplémentaires
Conception de la tête de décodage : par rapport à l'attention croisée, l'empilement de plusieurs couches d'attention déformable peut avoir une latence plus faible et de meilleures performances. Par rapport aux requêtes au niveau du point, l'utilisation de requêtes au niveau du cadre de délimitation (c'est-à-dire le regroupement de boîtes englobantes) peut permettre d'obtenir des performances plus élevées.
Analyse de latence : la méthode présentée dans cet article peut surpasser les méthodes précédentes en termes de performances et de vitesse.
B. Détails supplémentaires de mise en œuvre
Détails du modèle de l'ensemble de données nuScenes : les images non clés sont accumulées dans des images clés et entrées dans le modèle ; l'augmentation de l'échantillonnage GT est utilisée dans les premières étapes de la formation.
Détails du modèle de l'ensemble de données Waymo : utilisez l'entrée d'une seule image ; utilisez l'augmentation de l'échantillonnage GT au début de la formation.
Étendu à un modèle multimodal : Pour obtenir les caractéristiques de l'image BEV à partir des caractéristiques de la grille 3D de l'image projetée, cet article utilise une attention croisée dans chaque cylindre : les caractéristiques de la grille lidar BEV sont considérées comme des requêtes et les caractéristiques du voxel de l'image sont considérées comme des clés. et des valeurs. Utilisez des convolutions supplémentaires pour fusionner les fonctionnalités d’image BEV et les fonctionnalités lidar BEV. Cette fusion se produit à chaque étape de l'encodeur de carte thermique à plusieurs étages.
C. Localité prédictive pour le raffinement de deuxième étape
Cet article note que malgré l'utilisation d'opérations globales et d'informations sur la perspective de la caméra, la différence entre les petits objets et les grandes échelles limite le raffinement en deux étapes à longue portée. Autrement dit, par rapport à la prédiction de la carte thermique de la première étape, la plage de régression de décalage de la plupart des méthodes de la deuxième étape est très petite (c'est-à-dire la localité de prédiction), de sorte que la capacité de la deuxième étape à compenser les détections manquées (FN) est faible. Cet article peut atténuer ce problème dans une certaine mesure en déterminant FN sur BEV et en effectuant une nouvelle notation locale.
D. Exemple de visualisation
Résultats de visualisation : Bien que l'AR de cette méthode soit élevé, une occlusion sévère et des points manquants entraîneront l'apparition de FN ; une prédiction incorrecte de la direction du cadre de délimitation peut également provoquer l'apparition de FN.