Lien d'origine : https://arxiv.org/abs/2211.11646
1. Introduction
Le modèle NeRF peut apprendre les représentations NeRF de scènes 3D directement à partir d'images RVB et de poses de caméra données. Cet article propose NeRF-RPN, qui utilise les champs de rayonnement et les densités extraits du modèle NeRF pour générer directement des propositions de boîtes englobantes.
3. Méthode
Comme le montre la figure, notre méthode comporte deux composants, l'extracteur de caractéristiques (grille de radiance et de densité échantillonnée à partir de NeRF) et la tête RPN (générant des propositions d'objets).
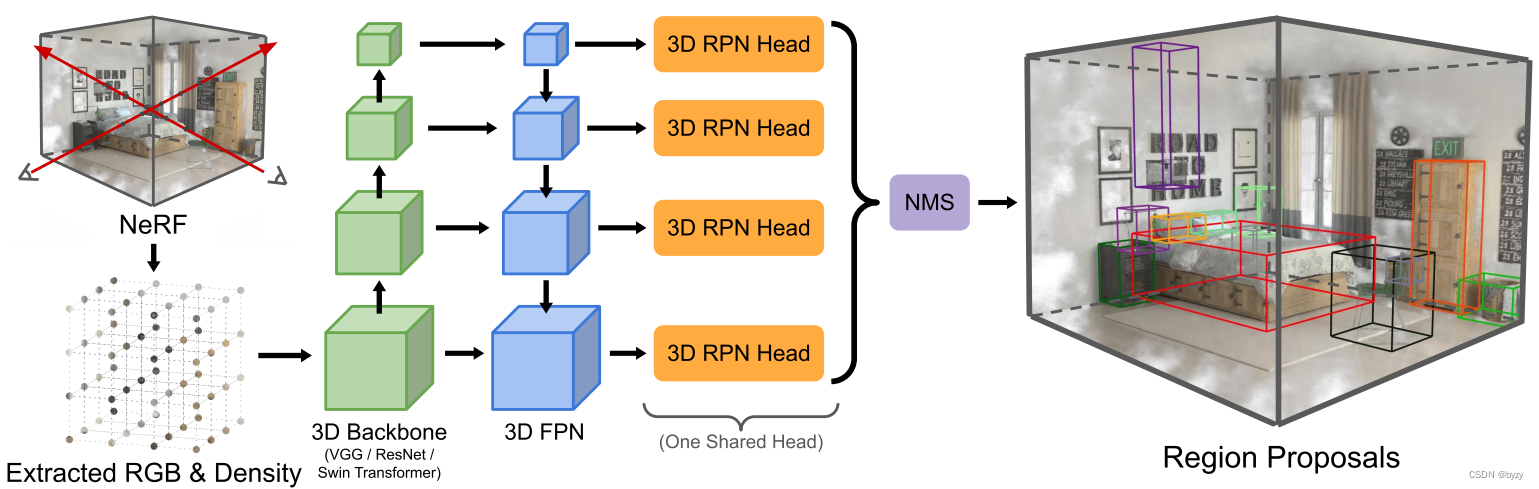
3.1 Échantillonnage à partir de l'entrée NeRF
La première étape consiste à échantillonner uniformément les champs de rayonnement et de densité du modèle NeRF et à établir une grille de volume caractéristique. La résolution de la grille volumique est proportionnelle à la plage de chaque dimension, garantissant ainsi le rapport hauteur/largeur de l'objet. Pour le modèle NeRF qui utilise RVB comme expression de rayonnement, cet article échantillonne et fait la moyenne des résultats de l'ensemble de vues utilisé dans la formation NeRF. Si la pose de la caméra est inconnue, échantillonnez uniformément les directions du ballon. De manière générale, étant donné un échantillon ( r , g , b , α ) (r,g,b,\alpha)( r ,g ,b ,α ) , à l'intérieur( r , g , b ) (r,g,b)( r ,g ,b ) est le rayonnement moyen,α \alphaα est converti à partir de la densité : α = clip ( 1 − exp ( − σ δ ) , 0 , 1 ) \alpha=\text{clip}(1-\exp(-\sigma\delta),0,1 )un=agrafe ( 1−exp ( − σ ré ) ,0 ,1 ) oùδ = 0,01 \delta=0,01d=0,01 est la distance par défaut. Pour le NeRF qui utilise des harmoniques sphériques ou d'autres fonctions de base pour exprimer le rayonnement, les valeurs RVB ou les coefficients des fonctions de base peuvent être utilisés comme informations sur le rayonnement en fonction de la tâche en aval.
3.2 Extracteur de fonctionnalités
En considérant des objets de différentes tailles et des scènes de différentes échelles, FPN est utilisé dans l'extracteur de fonctionnalités de cet article pour générer la pyramide des fonctionnalités.
3.3 Réseau de propositions de régions 3D
3D RPN prend la pyramide des fonctionnalités en entrée et génère un ensemble de cadres de délimitation orientés et leurs scores correspondants. Cet article expérimente deux types de RPN : avec ancre et sans ancre, comme le montre la figure ci-dessous.

RPN basé sur des boîtes d'ancrage : cet article place des boîtes d'ancrage 3D de différents rapports hauteur/largeur et tailles dans chaque couche de la pyramide de caractéristiques, et utilise la convolution pour prédire le décalage et le score des objets dans chaque boîte d'ancrage. Les convolutions entre les couches partagent des poids. Décalage du cadre de délimitation t = ( tx , ty , tz , tw , tl , th , t α , t β ) t=(t_x,t_y,t_z,t_w,t_l,t_h,t_\alpha,t_\beta)t=( tx,toui,tz,tw,tje,th,tun,tb) Spécifie ce qui suit : tx = ( x − xa ) / wa , ty = ( y − ya ) / la , tz = ( z − za ) / hatw = log ( w / wa ) , tl = log ( l / la ) , th = log ( h / ha ) t α = Δ α / w , t β = Δ β / l t_x=(x-x_a)/w_a,t_y=(y-y_a)/l_a, t_z=( z-z_a)/h_a\\t_w=\log(w/w_a),t_l=\log(l/l_a),t_h=\log(h/h_a)\\t_\alpha=\Delta\alpha /w, t_\bêta=\Delta\bêta/ltx=( x−Xun) / wun,toui=( oui−ouiun) / lun,tz=( z−zun) / huntw=journal ( p / p _un) ,tje=journal g ( l / lun) ,th=journal ( h / h _un)tun=D a / w ,tb=Δ β / l oùx , y , z , w , l , h , α , β x,y,z,w,l,h,\alpha,\betax ,oui ,z ,w ,je ,h ,un ,β为实实边圆憆过数,xa , ya , za , wa , la , ha x_a,y_a,z_a,w_a,l_a,h_aXun,ouiun,zun,wun,jeun,hunest le paramètre de la boîte d'ancrage.
Lorsque l'IoU entre une proposition et une boîte englobante réelle est supérieure à 0,35, ou lorsque l'IoU entre une proposition et une boîte englobante réelle est la plus grande parmi toutes les propositions, la proposition est marquée comme positive ; dans une proposition non positive, la IoU avec toutes les boîtes englobantes réelles. Ceux qui sont tous deux inférieurs à 0,2 sont marqués comme négatifs. Les propositions restantes ne participent pas au calcul de la fonction de perte. La fonction de perte est similaire à Faster-RCNN, utilisant la perte d'entropie croisée binaire pour la classification et la perte smoothL1 pour la régression (calculée uniquement pour les boîtes d'ancrage positives) : L = 1 N ∑ i L cls ( pi , pi ∗ ) + λ N pos ∑ ipi ∗ L reg ( ti , ti ∗ ) L=\frac{1}{N}\sum_iL_{cls}(p_i,p_i^*)+\frac{\lambda}{N_{pos}}\sum_ip^* _iL_{reg }(t_i,t_i^*)L=N1je∑Lc l s( p.je,pje∗)+Npos _jeje∑pje∗Lre g( tje,tje∗) convertira la proposition en cuboïde avant le post-traitement.
RPN sans boîtes d'ancrage: similaire au FCOS, score de prédictionppp , centralitéccc et décalage du cadre englobantt = ( x 0 , y 0 , z 0 , x 1 , y 1 , z 1 , Δ α , Δ β ) t=(x_0,y_0,z_0,x_1,y_1,z_1,\ Delta\ alpha,\Delta\bêta)t=( x0,oui0,z0,X1,oui1,z1,D a ,Δ β )。回归目标被定义为: x 0 ∗ = x − x 0 ( i ) , x 1 ∗ = x 1 ( i ) − x , y 0 ∗ = y − y 0 ( i ) , y 1 ∗ = y 1 ( je ) − y , z 0 ∗ = z − z 0 ( je ) , z 1 ∗ = z 1 ( je ) − z Δ α ∗ = vx ( je ) − X , Δ β ∗ = vy ( je ) − y x_0^*=x-x_0^{(i)},x_1^*=x_1^{(i)}-x,y_0^*=y-y_0^{(i)},y_1^*=y_1^ {(i)}-y,z_0^*=z-z_0^{(i)},z_1^*=z_1^{(i)}-z\\\Delta\alpha^*=v_x^{(i) }-x,\Delta\bêta^*=v_y^{(i)}-yX0∗=X−X0( je ),X1∗=X1( je )−x ,oui0∗=oui−oui0( je ),oui1∗=oui1( je )−oui ,z0∗=z−z0( je ),z1∗=z1( je )−zD une*=vX( je )−x ,D b*=voui( je )−y à l'intérieurde x , y , zx,y,zx ,oui ,z représente la position du voxel, exposant(i) (i)( i ) représente le véritable cadre de délimitation, et les indices 0 et 1 représentent les limites inférieure et supérieure du véritable cadre de délimitation aligné sur l'axe dans cette dimension. vx (i) v_x^{(i)}vX( je )Représente le véritable cadre de délimitation à xy xyxxdu sommet le plus élevé dans la projection du plan x yx栐标,vy ( je ) v_y^{(i)}voui( je )Représente l'yy du sommet le plus à droite du véritable cadre de délimitation dans la projection BEVcoordonnée y , comme le montre la figure ci-dessus. La vraie valeur de la centralité est c ∗ = min ( x 0 ∗ , x 1 ∗ ) max ( x 0 ∗ , x 1 ∗ ) × min ( y 0 ∗ , y 1 ∗ ) max ( y 0 ∗ , y 1 ) }{\max(x^*_0,x^*_1)}\times\frac{\min(y^*_0,y^*_1)}{\max(y^*_0,y^* _1)} \times\frac{\min(z^*_0,z^*_1)}{\max(z^*_0,z^*_1)}}c*=maximum ( x0∗,X1∗)min ( x0∗,X1∗)×maximum ( y0∗,oui1∗)min ( y0∗,oui1∗)×maximum ( z0∗,z1∗)min ( z0∗,z1∗)总损失为L i = 1 N ∑ i L cls ( pi , pi ∗ ) + λ N pos ∑ ipi ∗ L reg ( ti , ti ∗ ) + 1 N pos ∑ ipi ∗ L ctr ( ci , ci ∗ ) L_i= \frac{1}{N}\sum_iL_{cls}(p_i,p_i^*)+\frac{\lambda}{N_{pos}}\sum_ip^*_iL_{reg}(t_i,t_i^*)+\ frac{1}{N_{pos}}\sum_ip^*_iL_{ctr}(c_i,c_i^*)Lje=N1je∑Lc l s( p.je,pje∗)+Npos _jeje∑pje∗Lre g( tje,tje∗)+Npos _1je∑pje∗Lc t r( cje,cje∗) où la perte de classification est la perte focale, la perte de régression est la perte IoU de la boîte englobante pivotée et la perte de centralité est la perte d'entropie croisée binaire. pi ∗ ∈ { 0 , 1 } p_i^*\in\{0,1\}pje∗∈{
0 ,1 } est la véritable étiquette du voxel, déterminée par le processus d'échantillonnage central et de prédiction multi-niveaux dans FCOS. N pos N_{pos}Npos _Pour pi ∗ = 1 p^*_i=1pje∗=Nombre de voxels de 1 . Les propositions seront également converties en cuboïdes avant le post-traitement.
3.4 Fonction de perte supplémentaire

Classification des objets : Bien que l'objectif principal du NeRF-RPN soit d'obtenir un taux de rappel élevé, un faible taux de FP est parfois également important. Cet article ajoute un réseau de classification binaire pour réaliser la segmentation de premier plan/arrière-plan, saisit le RoI de la région d'intérêt généré par RPN et la pyramide de fonctionnalités générée par l'extracteur de fonctionnalités, et génère le score de classification et le décalage raffiné du RoI, comme indiqué dans le figure ci-dessus. Cet article fait référence au RPN orienté, par rotation du pooling RoI, pour chaque proposition (xr, yr, zr, wr, lr, hr, θ r) (x_r, y_r, z_r, w_r, l_r, h_r,\theta_r)( xr,ouir,zr,wr,jer,hr,jer) pour extraire des fonctionnalités avec invariance de rotation. Tout d'abord, le cadre de délimitation est agrandi et divisé en grilles de volumes de caractéristiques, puis une interpolation trilinéaire est utilisée pour calculer la valeur de chaque grille et l'entrer dans la couche de regroupement, ce qui donneN × 3 × 3 × 3 N\times3\times3\times3.N×3×3×3 branches de taille, de classification d'entrée et de régression. Le décalage du cadre de délimitation icig = ( gx , gy , gz , gw , gl , gh , g θ ) g=(g_x,g_y,g_z,g_w,g_l,g_h,g_\theta)g=( gx,goui,gz,gw,gje,gh,gje) Définir : gx = ( ( x − xr ) cos θ r + ( y − yr ) sin θ r ) / wr , gy = ( ( y − yr ) cos θ r − ( x − xr ) sin θ r ) / lr , gz = ( z − zr ) / hrgw = log ( w / wr ) , gl = log ( l / lr ) , gh = log ( h / h ) , g θ = ( θ − θ r ) / 2 π g_x=((x-x_r)\cos\theta_r+(y-y_r)\sin\theta_r)/w_r,g_y=((y-y_r)\cos\theta_r-(x-x_r) \sin \theta_r)/l_r,g_z=(z-z_r)/h_r\\g_w=\log(w/w_r),g_l=\log(l/l_r),g_h=\log(h/h_r),g_ \theta =(\theta-\theta_r)/2\pigx=(( x−Xr)parce quejer+( oui−ouir)péchéjer) / wr,goui=(( oui−ouir)parce quejer−( x−Xr)péchéjer) / lr,gz=( z−zr) / hrgw=journal ( p / p _r) ,gje=journal g ( l / lr) ,gh=journal ( h / h _r) ,gje=( je−jer) /2 π Le RoI dont l'IoU avec n'importe quelle boîte englobante de vérité terrain est supérieur à 0,25 est marqué comme un objet, et les autres sont des non-objets. La fonction de perte est similaire àla section RPN basée sur la boîte d'ancrage, seul le décalage de la boîte englobante est remplacé parg, g ∗ g, g^*g ,g* .
Perte de projection 2D : coordonnées du cadre de délimitation 3Dbi = (xi, yi, zi) b_i=(x_i,y_i,z_i)bje=( xje,ouije,zje) projection en 2Dbi ′ = ( xi ′ , yi ′ ) b'_i=(x'_i,y'_i)bje′=( xje′,ouije′) , obtenez la perte de projection 2D : L 2 d proj = 1 N cam N box L reg ( bi ′ , bi ′ ∗ ) L_{2d\ proj}=\frac{1}{N_{cam}N_{box}} L_ {reg}(b'_i,{b'_i}^*)L2 j p ro j=Nje suisNboîte _ _1Lre g( bje′,bje′* )
5. Expérimentez
5.1 Formation et tests
Entraînement : Pendant l'entraînement, la scène d'entrée est dessinée aléatoirement le long de x, yx, yx ,Retourner le long de l' axe y et le long dezzRotation de l'axe Z π / 2 \pi/2Angle π /2 . De plus, la scène suivra aussi aléatoirementle zzL' axe z pivote d'un petit angle. Pour le RPN basé sur des boîtes d'ancrage, 256 boîtes d'ancrage sont échantillonnées de manière aléatoire à chaque fois (le rapport positif et négatif est de 1 : 1) pour le calcul des pertes.
Test : filtrez d'abord les boîtes englobantes en dehors de la scène, puis sélectionnez 2 500 propositions pour chaque échelle de fonctionnalités pour une suppression non maximale, et sélectionnez les 2 500 propositions avec les scores les plus élevés.
5.2 Etudes d'ablation
Tronc et cou : Après avoir fixé le tronc et le cou, le RPN sans boîtes d'ancrage a de meilleures performances, car la prédiction de centralité peut supprimer ces propositions distantes, et le rapport hauteur/largeur fixe et la taille de la boîte d'ancrage limitent sa taille. Détection d'un objet.
Stratégie d'échantillonnage NeRF : le champ de densité de NeRF est indépendant de la vue, tandis que le champ de rayonnement est lié à la direction de la vue et dispose de diverses méthodes de codage. Les expériences dans le matériel supplémentaire montrent que l'utilisation seule de la densité est la stratégie optimale.
Perte de régression : des expériences utilisant la perte IoU, la perte DIoU et leurs variantes agissant sur des boîtes englobantes orientées montrent que la perte IoU peut avoir de meilleures performances.
5.3 Résultats
Les expériences montrent que les reconstructions NeRF de mauvaise qualité peuvent sérieusement affecter les prédictions du cadre de délimitation.
Application : montage de scènes . Étant donné une proposition générée par NeRF-RPN, la scène NeRF peut être modifiée, par exemple en définissant la densité dans la proposition sur 0 lors du rendu.
Matériel complémentaire
2. Étude d'ablation sur la stratégie d'échantillonnage NeRF
Afin d'explorer l'impact des informations de rayonnement liées à la vue NeRF sur les performances de détection, cet article expérimente les méthodes d'échantillonnage suivantes :
- Utilisez uniquement la densité ;
- Utiliser une luminance moyenne fixe + densité de 18 vues ;
- éclat moyen + densité sur toutes les vues de caméra à l'aide de l'entraînement ;
- Sur la base de 3, seules les vues d'entraînement contenant des points d'échantillonnage dans le tronc de vue sont sélectionnées ;
- Utilisez les coefficients d'harmoniques sphériques (SH) jusqu'au 3ème ordre (la fonction SH est obtenue en échantillonnant uniformément le rayonnement de 300 directions sur une sphère) + densité.
Les expériences montrent que 1 a les meilleures performances, ce qui montre que les informations sur le rayonnement affectent les performances.
3. Classement des objets
Les expériences montrent que l'utilisation de la perte de classification d'objets dégrade les performances. Cela peut être dû à la résolution limitée de la grille de volume caractéristique et à l'interpolation rotationnelle conduisant à des erreurs de rééchantillonnage élevées. Mais pour certaines tâches en aval qui nécessitent des fonctionnalités RoI, la perte de classification des objets peut toujours être utile.
4. Projection 2D
Les expériences montrent que la supervision 3D fournit déjà suffisamment d’informations et que l’utilisation de la supervision 2D ne peut pas améliorer les performances. Mais lorsque la supervision 3D n’est pas présente, la perte de projection 2D peut quand même s’avérer utile.