Cet article écrit principalement une certaine compréhension des modèles de séquence courants, principalement pour noter que ma propre compréhension de ces modèles est loin d'être suffisante.
Modèle de Markov caché HMM
La propriété de Markov signifie que l'état actuel t est uniquement lié à l'état précédent t-1 (premier ordre), et il n'est pas lié à l'état précédent t-2. Cela peut être considéré comme un modèle de langage à n grammes, le tout dans le but de contrôler la complexité du modèle Degré (d'une part, le modèle est trop complexe et un jeu de données insuffisant entraînera l'échec de la convergence du modèle; d'autre part, si la complexité du modèle augmente de façon exponentielle, le matériel et le temps sont inacceptables).
Le modèle de Markov caché spécifie que l'état caché satisfait le Markov du premier ordre, et l'observation est déterminée par un seul état caché.
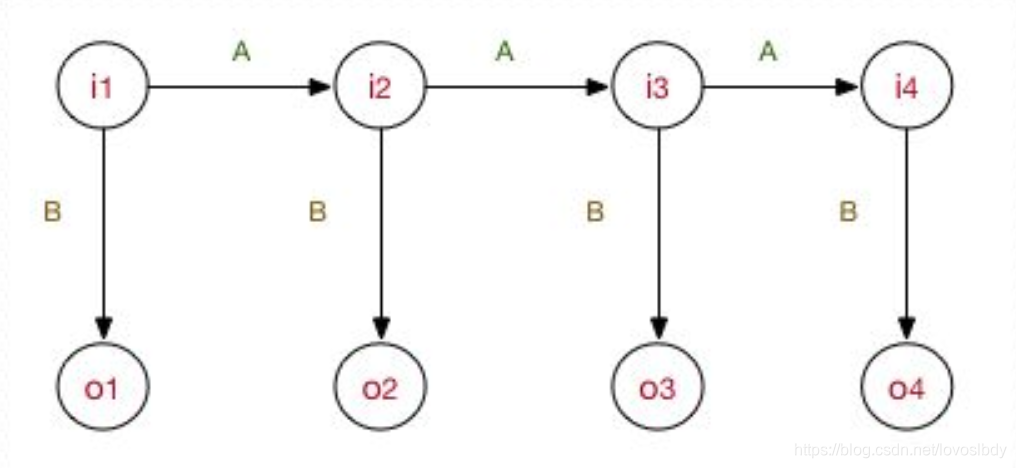
Les principaux paramètres du modèle comprennent: la matrice de transition entre les états cachés, la matrice de probabilité d'émission de l'état caché à la probabilité d'émission et la probabilité initiale de l'état implicite.
Si le problème d'étiquetage de séquence est complètement classé en fonction de la classification, c'est-à-dire d'examiner la classification de chaque mot séparément, puis d'utiliser le modèle génératif pour le modéliser. Ensuite, notre modèle de paramètres inclut toujours la distribution de l'état caché et la probabilité conditionnelle d'observation sous l'état caché.
Pour les tâches séquentielles, i1 et i2 sont évidemment liés. La propriété Markov est utilisée pour simplifier le modèle de séquence de modélisation, et la distribution d'état caché précédente est convertie en matrice de probabilité et de transition initiale d'état caché. La corrélation entre i1 et i2 est considérée en utilisant la matrice de transition. (Par exemple, la matrice de transition de i1 (B_N) à i2 (E_V) est 0, alors il est impossible d'avoir une séquence de "B_N, E_V")
Les problèmes de HMM sont principalement divisés en
- Connaissant le modèle et la séquence d'observation, calculez la probabilité d'une séquence implicite
- Connaître la séquence d'observation, résoudre le modèle
- Connaître le modèle et la séquence d'observation, calculer la séquence cachée la plus probable
Il utilise l'algorithme avant, l'algorithme de Viterbi (utilisant la programmation dynamique pour résoudre les problèmes) de vraisemblance maximale et l'algorithme de Baum-Welch. (L'algorithme Baum-Welch est similaire à l'algorithme EM, je ne comprends pas les détails)
Algorithme MEMM
Le modèle
ME de modèle d' entropie maximale vise principalement à assurer la fonction ffL'espérance de f doit être cohérente avec l'attente des caractéristiques obtenues à partir des données d'apprentissage pour maximiser l'entropie conditionnelle.
min - H (P) = ∑ x, yp ^ (x, y) f (x, y) min -H (P) = \ somme_ (x, y) \ hat (p) (x, y) f (x , y)m je n-H ( P )=x , yΣp^( x ,y ) f ( x ,et )
s. t. ∑ x, yp ^ (x) P (y ∣ x) fi (x, y) = τ i st \ \ \ sum_ {x, y} \ hat {p} (x) P (y | x) f_i (x , y) = \ tau_is . t . x , yΣp^( x ) P ( y ∣ x ) fJe( x ,et )=τJe
∑ x P (y ∣ x) = 1 \ somme_xP (y | x) = 1 XΣP ( y ∣ x )=1
L'algorithme MEMM est illustré dans la figure ci-dessous
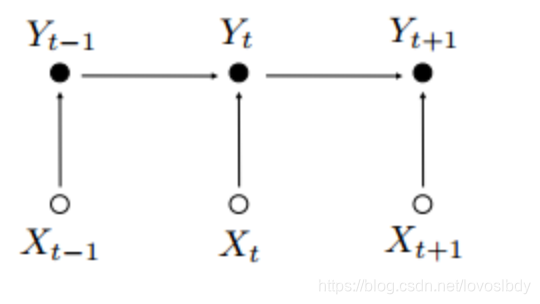
La première différence entre MEMM et HMM est que la flèche pointe ici de la séquence d'observation vers la séquence cachée (ici n'est pas un modèle génératif, il n'y a pas de séquence cachée, c'est-à-dire de X à Y) dans la même tâche d'étiquetage de séquence (X est le mot, Y est le Etiquette correspondante)
Sa probabilité de modélisation est:
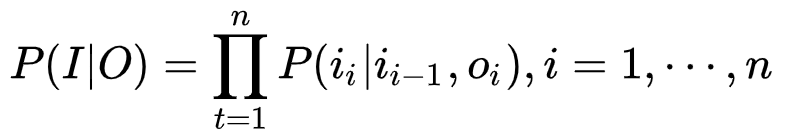
Parmi elles, le
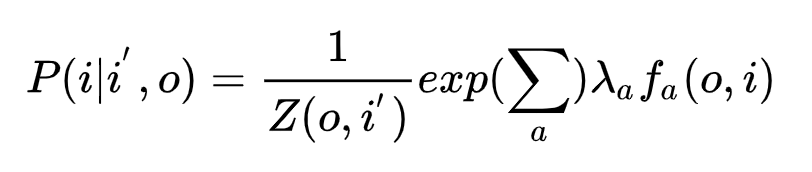
modèle de solution consiste principalement à obtenir λ \ lambdaLe poids de λ . Connaissant le poids, vous pouvez utiliser la formule de la figure ci-dessus pour calculer la matrice de transition de O, I. Ici, la matrice de transition de I est liée à O. De plus, de nombreuses fonctionnalités peuvent être ajoutées ici, telles que i-2, i-3, ce qui garantit certainement un intervalle d'informations plus long.
Pourquoi est-ce appelé entropie maximale?
Je ne l'ai pas compris. Je le sais parce que P (Y | X) utilise la forme du classificateur d'entropie maximale, mais je n'ai pas vu la relation entre cette formule et le modèle d'entropie maximale. .
Calcul spécifique
Plus précisément, sa séquence de solutions étiquetant trois types de problèmes est très similaire à HMM. En raison de sa propriété Markov, il est toujours résolu par l'idée de programmation dynamique.
Ensuite, il y a le problème du décalage d'étiquette.
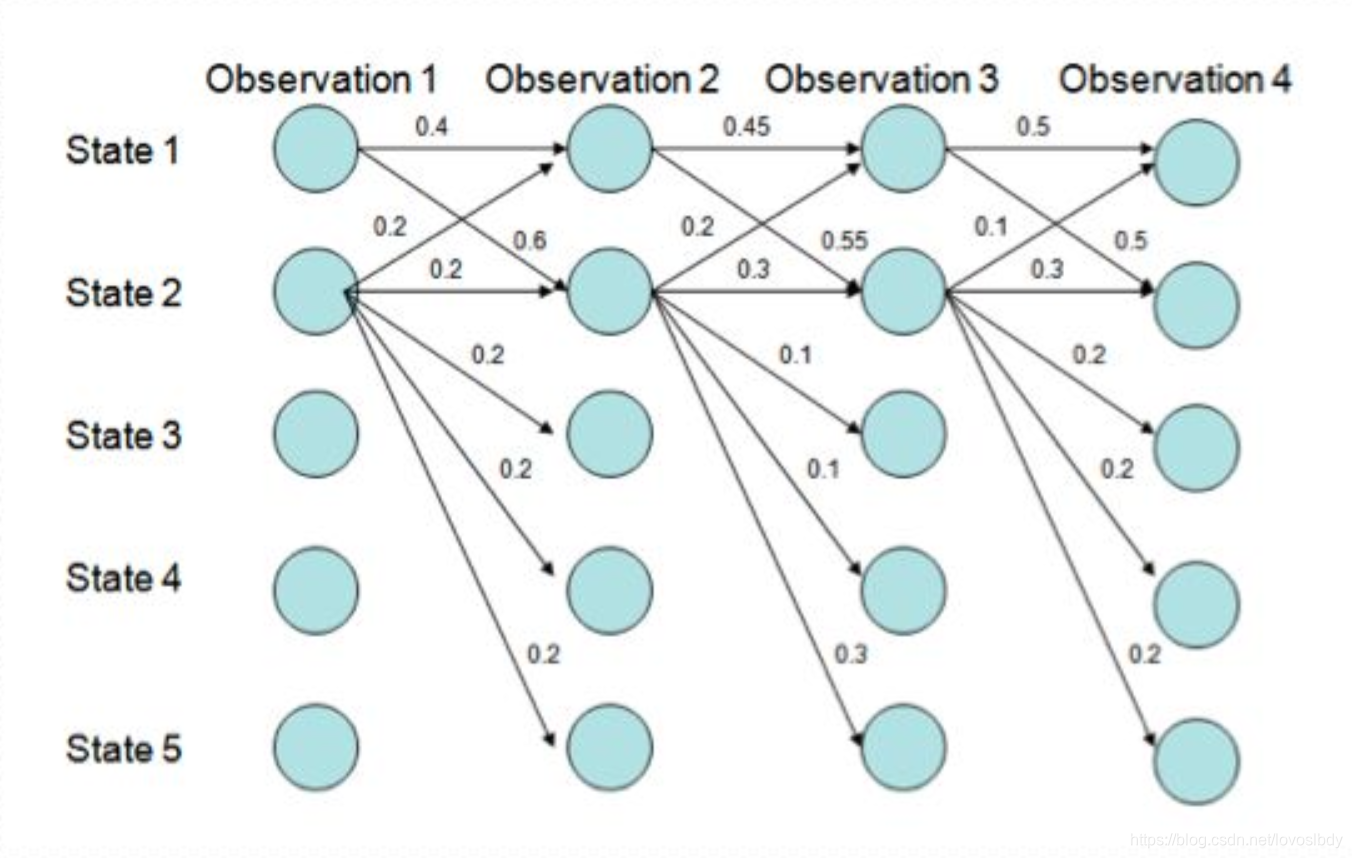
Comme le montre la matrice de transition: l'état 1 a tendance à passer à l'état 2, tandis que l'état 2 a tendance à rester à l'état 2.
Plus précisément, le chemin optimal (la plus grande multiplication cumulée) est calculé comme P (1-> 1-> 1-> 1) = 0,4 x 0,45 x 0,5 = 0,09, et le P
restant
(2-> 2-> 2-> 2) = 0,2 X 0,3 X 0,3 = 0,018,
P (1-> 2-> 1-> 2) = 0,6 X 0,2 X 0,5 = 0,06,
P (1-> 1-> 2-> 2) = 0,4 X 0,55 X 0,3 = 0,066
Alors pourquoi y a-t-il un biais? Normalisation locale? Mais
- L'état 1 a tendance à passer à l'état 2, tandis que l'état 2 a tendance à rester à l'état 2. Qu'est-ce que ça veut dire? Signifie que la fin du chemin optimal doit être 2?
- Est-ce lié à l'optimisation de l'algorithme de Viterbi?
Une capture d'écran de Zhihu est postée ici, mais je ne l'ai pas comprise. . . . Mais je pense que la normalisation locale est problématique.

Algorithme CRF
La plus grande différence entre CRF et le précédent est qu'il s'agit d'un graphe non orienté, donc sa méthode de calcul de la probabilité est différente, ce qui permet d'éviter le problème du biais d'étiquette.

Plus précisément, sa modélisation est
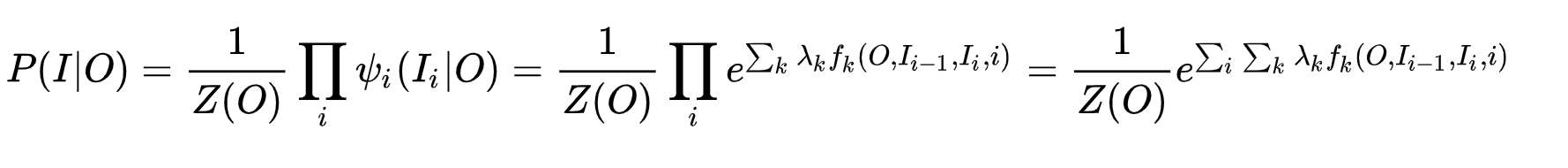
que la plus grande différence entre MEMM et MEMM est qu'il est normalisé à la partie la plus externe, tandis que MEMM est multiplié après normalisation. (En raison de la différence entre les graphes non orientés et les graphes orientés?)
Résoudre spécifiquement pour λ \ lambdaAprès λ , la probabilité de la séquence peut être calculée.
LSTM + CRF
Désormais, le réseau neuronal suivi par CRF est devenu une configuration standard.
Reportez-vous à LSTM + CRF pour
voir le CRF suivi de LSTM. Il traite la sortie d'étiquette par LSTM comme son propre score d'entité (Ii), une matrice de transition (Ii-1 à Ii) sert de score d'entité adjacente et sa fonction objective est la probabilité de séquence réelle. maximum.
Principalement pour enregistrer vos propres pensées, la compréhension est extrêmement incomplète, veuillez me corriger! !