1. Brève introduction du document
1. Premier auteur : Rui Li
2. Année de publication : 2023
3. Revue publiée : CVPR
4. Mots-clés : flux optique, deep learning, PatchMatch, recherche locale
5. Motivation pour l'exploration : outre la précision, les performances et la mémoire sont également des défis pour l'apprentissage profond, en particulier lors de la prévision du flux optique à haute résolution. Pour réduire la complexité de calcul et l'utilisation de la mémoire, les méthodes précédentes utilisent une stratégie grossière à fine, mais peuvent souffrir de problèmes de récupération d'erreur de basse résolution. Afin de maintenir une grande précision sur les grands déplacements, en particulier sur les petits objets se déplaçant rapidement, RAFT construit un volume de corrélation 4D toutes paires et utilise des blocs GRU convolutifs pour la recherche. Cependant, il existe également des problèmes de mémoire lors de la prévision du flux optique haute résolution.
6. Objectif du travail : Afin de réduire la mémoire tout en conservant une haute précision, PatchMatch est introduit pour lutter contre le calcul de redondance élevée du volume de corrélation 4D All Paired de RAFT.
7. Idée de base : introduire l'idée de Patchmatch dans le calcul de corrélation, au lieu d'utiliser une stratégie de corrélation globale aussi clairsemée pour provoquer une perte de précision.
- Nous concevons un cadre efficace qui introduit pour la première fois Patchmatch dans la prédiction de flux optique de bout en bout. Il peut améliorer la précision du flux optique tout en réduisant la mémoire du volume de corrélation.
- Nous proposons un nouveau module de propagation inverse. Par rapport à la propagation, elle peut réduire efficacement les calculs tout en conservant des performances considérables.
8. Résultats expérimentaux :
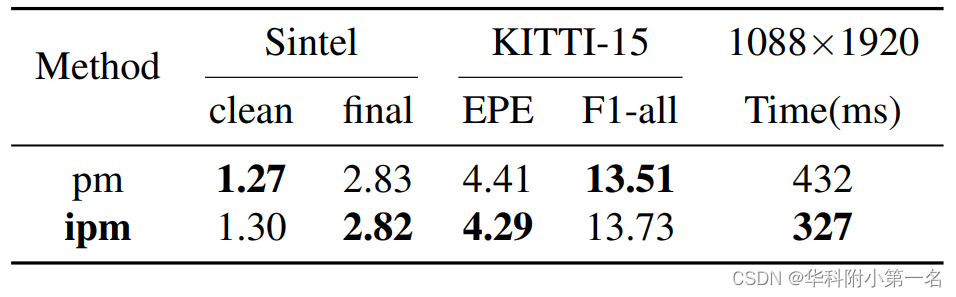
Au moment de la soumission, notre méthode se classe 1ère sur toutes les mesures du populaire benchmark KITTI2015, et se classe 2ème sur EPE sur le benchmark Sintel clean parmi les méthodes de flux optique publiées. L'expérience montre que notre méthode a une forte capacité de généralisation d'ensembles de données croisées que le F1-all atteint 13,73 %, soit une réduction de 21 % par rapport au meilleur résultat publié de 17,4 % sur KITTI2015. De plus, notre méthode montre un bon résultat en préservant les détails sur l'ensemble de données haute résolution DAVIS et consomme 2 fois moins de mémoire que RAFT.
9. Téléchargement papier :
https://github.com/zihuazheng/DIP
2. Processus de mise en œuvre
1. Comparaison des objets associés
Volume de corrélation locale. Dans la méthode moderne du flux optique basée sur le volume de corrélation local, la formule de calcul est la suivante :

Dans la formule, F1 est la carte des caractéristiques source, F2 est la carte des caractéristiques cible et d est le déplacement dans la direction x ou y. X = [0,H)x[0,w), D=[−dmax,Dmax]2, h est la hauteur de la carte des fonctionnalités et w est la largeur de la carte des fonctionnalités. Par conséquent, la mémoire et le calcul du volume pertinent sont linéaires avec hw(2dmax + 1)2 et quadratiques avec le rayon de l’espace de recherche. Limité par la taille du rayon de recherche, il est difficile d’obtenir un flux optique de haute précision dans des scènes difficiles à haute résolution.
Volume de corrélation global. Récemment, RAFT [36] propose un volume de corrélation toutes paires, qui atteint des performances de pointe. Le calcul de corrélation globale de la position (i, j) dans F1 et de la position (k, l) dans F2 est défini comme suit :

Où m est le nombre de couches de la pyramide. 2 m est la taille du noyau de pooling. Comparé au volume corrélatif local, le volume corrélatif global contient N2 éléments, où N = hw. Lorsque le h ou le w de F augmente, la quantité de mémoire et de calcul augmentera de façon exponentielle. Par conséquent, les méthodes globales souffrent d’une mémoire insuffisante pour l’inférence haute résolution.
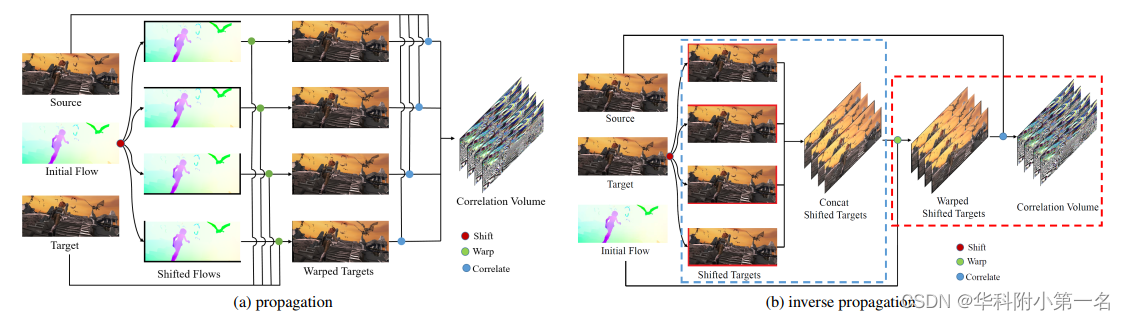
Correspondance de blocs (méthode Patchmatch). Patchmatch est utilisé pour trouver une correspondance dense entre les images pour une édition structurée. L’idée clé derrière tout cela est qu’il est possible d’obtenir de bonnes suppositions en effectuant un grand nombre d’échantillonnages aléatoires. Et en fonction de la localité de l'image, une fois qu'un bon point de correspondance est trouvé, les informations peuvent être propagées efficacement aux images adjacentes. Par conséquent, une stratégie de propagation est proposée pour réduire le rayon de recherche et une recherche locale est utilisée pour améliorer encore la précision. La complexité de la méthode Patchmatch est hw(n + r2), où n est le nombre de propagations et r est le rayon de recherche local. Les deux valeurs sont petites et ne changent pas avec l'augmentation du déplacement et de la résolution.
2. Patchmatch du flux optique
L'approche traditionnelle de Patchmatch comporte trois composants principaux. 1) Initialisation aléatoire. Obtenez de bonnes suppositions avec de nombreux échantillonnages aléatoires. 2) Répandre. En fonction de la localité de l'image, une fois qu'un bon point de correspondance est trouvé, les informations peuvent être propagées efficacement à partir de ses voisins. 3) Recherche aléatoire. Il est utilisé dans les propagations ultérieures pour empêcher l'optimisation locale, lui permettant ainsi d'obtenir une bonne correspondance lorsqu'aucune bonne correspondance n'existe dans son voisinage.
La propagation et la recherche itératives sont la clé pour résoudre le problème du flux optique. Lors de la phase de propagation, un point de la carte de caractéristiques est considéré comme un patch et 4 points de départ adjacents sont sélectionnés. Par conséquent, chaque point peut obtenir des flux optiques candidats de ses voisins en déplaçant la carte de flux optique vers les 4 voisins. Un volume de corrélation 5D est ensuite calculé à partir des flux optiques candidats voisins et de leurs flux optiques. Étant donné le déplacement ∆p de tous les flux optiques, le calcul de corrélation de propagation peut être défini comme :
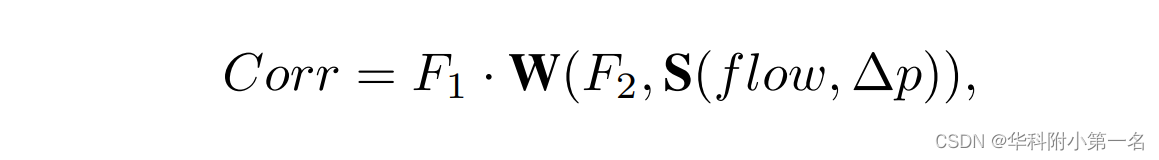
S(flow,∆p) est le flux optique de déplacement selon ∆p. W est F2 modifié avec le flux optique en mouvement. Sans aucun doute, plus il y a de points de départ sélectionnés, plus d’opérations sont nécessaires. Lorsque la propagation itère m fois pour sélectionner n points de départ, la propagation nécessite que le flux optique se déplace n × m fois et que les entités sources changent n × m fois. Cela augmente les opérations de mémoire et les calculs d'interpolation, en particulier lors de la prévision du flux optique haute résolution. Afin de réduire le nombre d'options, pour la première fois, la rétropropagation est utilisée à la place de la propagation. Dans la phase de recherche, la recherche aléatoire est remplacée par une méthode de recherche locale plus adaptée au réseau de bout en bout, et un taux de précision plus élevé est obtenu.
3. Correspondance profonde des blocs inversés
rétropropagation. Lors de la propagation, le déplacement du flux optique et la déformation des caractéristiques sont couplés en série, puisque le processus de déformation dépend du déplacement du flux optique. De plus, chaque itération doit effectuer plusieurs déplacements de flux optique, ce qui augmente la quantité de calcul. En théorie, déplacer le flux vers le bas à droite a la même position spatiale relative que déplacer la cible vers le haut à gauche. Les corrélogrammes des deux méthodes ont un décalage de pixels en coordonnées spatiales absolues. Nous appelons la façon dont la cible se déplace la rétropropagation, qui peut être exprimée comme suit :

Puisque ∆p est petit, le processus de rétropropagation est ignoré dans l’implémentation. c'est-à-dire obtenir :

Lors de la rétropropagation, les points caractéristiques cibles sont dispersés vers ses points de départ et déformés par le flux optique des points de départ. Par conséquent, les caractéristiques cibles peuvent être décalées et empilées à l'avance, puis déformées une seule fois à chaque itération pour obtenir les caractéristiques cibles après la déformation.
Dans ce travail, le point de départ est statique et ne change pas avec les itérations croissantes. Par conséquent, les entités cibles ne doivent être déplacées vers le point de départ qu’une seule fois, et les entités cibles déplacées peuvent être réutilisées à chaque itération. De cette façon, s'il y a n points de départ pour m itérations de propagation, il suffit de déplacer l'entité cible n fois et de modifier l'entité cible déplacée m fois. La phase de rétropropagation peut être divisée en deux sous-phases :
Phase d'initialisation : fonctionnalités source d'entrée, fonctionnalités cibles. Les caractéristiques d'objet sont décalées en fonction des points de départ, puis les caractéristiques d'objet décalées sont empilées en tant que caractéristiques d'objet partagées le long de la dimension de profondeur.
Phase d'exécution : saisissez un flux et calculez la corrélation entre les fonctionnalités source et les fonctionnalités cibles de distorsion en fonction des fonctionnalités cibles partagées par la distorsion de flux.
recherche locale. En raison de la plage très clairsemée de valeurs de flux optique initialisées de manière aléatoire, il est difficile d'obtenir un flux optique très précis uniquement par propagation de blocs. Par conséquent, dans ce travail, une recherche de voisinage local est effectuée après chaque propagation de bloc. Contrairement à Patchmatch, il effectue une recherche aléatoire après chaque propagation et diminue le rayon de recherche à mesure que les itérations augmentent. Dans cet article, seule une recherche fixe à petit rayon est effectuée après chaque propagation, appelée recherche locale. Etant donné un incrément de flux optique ∆f, la recherche locale peut être exprimée par la formule :

Dans ce travail, le rayon de recherche final est fixé à 2 en fonction des résultats expérimentaux. A cet effet, le module Patchmatch inverse se compose principalement d'un bloc de rétropropagation et d'un bloc de recherche locale. À chaque itération, la rétropropagation est suivie d'une recherche locale. Il convient de noter que les deux blocs sont regroupés en utilisant le coût GRU.
4. Structure du réseau
Pour obtenir un flux optique de haute précision sur des images haute résolution, un nouveau cadre de prédiction de flux optique DIP est conçu. Un aperçu est présenté dans la figure ci-dessous. Il est principalement divisé en deux étapes : (1) extraction de fonctionnalités ; (2) mise à jour itérative multi-échelle.

extraction de caractéristiques. Tout d’abord, un réseau d’encodeurs de fonctionnalités est utilisé sur l’image d’entrée pour extraire une carte de fonctionnalités à résolution 1/4. Contrairement aux travaux précédents, ils utilisent la branche du réseau contextuel pour extraire le contexte. DIP active directement les cartes de fonctionnalités sources en tant que cartes contextuelles. Les cartes de fonctionnalités sont ensuite réduites à une résolution de 1/16 à l'aide d'un module de pooling moyen. Pour une résolution 1/4 et une résolution 1/16, utilisez la même structure et les mêmes paramètres. Par conséquent, DIP peut être formé en deux étapes et utiliser davantage d’étapes pour l’inférence lorsqu’il s’agit de grandes images.
Mise à jour itérative multi-échelle. La méthode est basée sur la propagation de voisinage et doit mettre à jour de manière itérative le flux optique. Le réseau se compose de deux modules, un module de rétropropagation et un module de recherche locale. Dans la phase de formation, le réseau est démarré avec un flux optique aléatoire de taille 1/16, puis le flux optique de taille 1/16 et 1/4 est optimisé de manière itérative à l'aide d'une méthode pyramidale. Dans la phase d'inférence, le même processus que la phase de formation peut être effectué. Afin d'obtenir un flux optique plus précis, le flux optique peut également être amélioré à l'échelle 1/8, puis le résultat peut être optimisé à l'échelle 1/4.
Le réseau accepte également le flux optique initialisé comme entrée pour l’étape d’inférence. Dans ce cas, le nombre de couches déduites de la pyramide est ajusté en fonction de la valeur maximale du flux optique initial. Par exemple, lors du traitement du flux optique d'une image vidéo, l'interpolation directe du flux optique de l'image précédente est utilisée comme entrée de l'image actuelle. En utilisant les informations de flux optique précédentes, deux pyramides ou plus peuvent être utilisées pour les grands déplacements afin de garantir la précision, et une pyramide pour les petits déplacements peut être utilisée pour réduire le temps d'inférence.
5. Perte
La fonction de perte est similaire à RAFT. DIP génère deux flux optiques par itération. Lorsque vous utilisez N itérations à des résolutions 1/16 et 1/4, la prédiction des nombres de sortie sur l'ensemble du processus de formation est N = itérations × 2 × 2. Étant donné que la supervision a plusieurs sorties, une séquence pondérée est calculée et additionnée sur la perte de la séquence prédite, en utilisant une stratégie similaire à RAFT. La perte totale peut être exprimée comme suit :

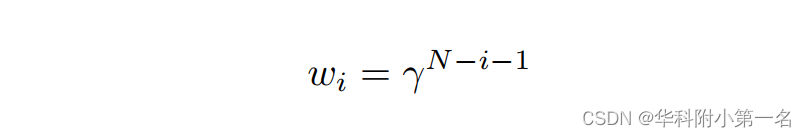
Où N est la longueur de la séquence prédite, M(x) représente la valeur moyenne de la matrice x, wi peut être calculé et γ=0,8 est utilisé dans l'entraînement.
6. Expérimentez
6.1. Détails de mise en œuvre
Utilisation de 16 GPU RTX 2080 Ti, AdamW et OneCycle.
6.2. Comparaison avec les technologies avancées

6.3. Expériences d'ablation