Mécanisme d'attention A2
Le texte original du mécanisme d'attention A2 est "A2-Nets : Double Attention Networks". Le principe est d'utiliser la mise en commun de l'attention de second ordre pour collecter toutes les caractéristiques clés de l'image entière dans une collection, puis d'utiliser un autre mécanisme d'attention pour combiner ces caractéristiques.Chaque emplacement de l'image séparément.
Adresse papier : https://arxiv.org/pdf/1810.11579.pdf
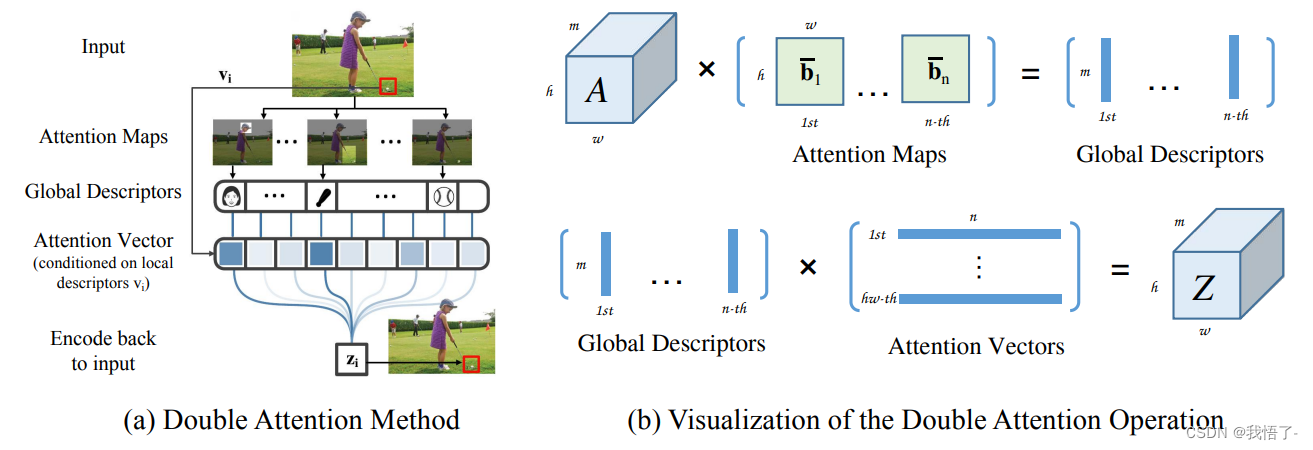
code afficher comme ci-dessous:
import numpy as np
import torch
from torch import nn
from torch.nn import init
from torch.nn import functional as F
class DoubleAttention(nn.Module):
def __init__(self, in_channels,c_m=128,c_n=128,reconstruct = True):
super().__init__()
self.in_channels=in_channels
self.reconstruct = reconstruct
self.c_m=c_m
self.c_n=c_n
self.convA=nn.Conv2d(in_channels,c_m,1)
self.convB=nn.Conv2d(in_channels,c_n,1)
self.convV=nn.Conv2d(in_channels,c_n,1)
if self.reconstruct:
self.conv_reconstruct = nn.Conv2d(c_m, in_channels, kernel_size = 1)
self.init_weights()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
b, c, h,w=x.shape
assert c==self.in_channels
A=self.convA(x) #b,c_m,h,w
B=self.convB(x) #b,c_n,h,w
V=self.convV(x) #b,c_n,h,w
tmpA=A.view(b,self.c_m,-1)
attention_maps=F.softmax(B.view(b,self.c_n,-1))
attention_vectors=F.softmax(V.view(b,self.c_n,-1))
# step 1: feature gating
global_descriptors=torch.bmm(tmpA,attention_maps.permute(0,2,1)) #b.c_m,c_n
# step 2: feature distribution
tmpZ = global_descriptors.matmul(attention_vectors) #b,c_m,h*w
tmpZ=tmpZ.view(b,self.c_m,h,w) #b,c_m,h,w
if self.reconstruct:
tmpZ=self.conv_reconstruct(tmpZ)
return tmpZ
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
a2 = DoubleAttention(512)
output=a2(input)
print(output.shape)