Le mécanisme d'attention (mécanisme d'attention) dans l'apprentissage en profondeur est une méthode qui imite le système visuel et cognitif humain, ce qui permet au réseau de neurones de se concentrer sur les parties pertinentes lors du traitement des données d'entrée. En introduisant le mécanisme d'attention, le réseau de neurones peut automatiquement apprendre et se concentrer de manière sélective sur les informations importantes dans l'entrée, améliorant ainsi les performances et la capacité de généralisation du modèle.
Le mécanisme d'attention introduit par le réseau de neurones convolutifs a principalement les méthodes suivantes :
- Ajout d'un mécanisme d'attention dans la dimension spatiale
- Ajouter un mécanisme d'attention sur la dimension du canal
- Ajouter un mécanisme d'attention sur la dimension mixte des deux
Nous expliquerons divers mécanismes d'attention dans cette série et utiliserons pytorch pour les implémenter. Aujourd'hui, nous expliquerons le mécanisme d'attention SENet
Le mécanisme d'attention SENet (Squeeze-and-Excitation Networks) introduit le mécanisme d'attention dans la dimension du canal. Son idée centrale est d'apprendre les poids des caractéristiques à travers le réseau en fonction de la perte, de sorte que la carte de caractéristiques effective ait un poids important, et la carte d'entités non valide ou à faible effet a un .poids L'encastrement du bloc SE dans certains réseaux de classification originaux augmente inévitablement certains paramètres et calculs, mais il reste acceptable en termes d'effets. Le bloc Sequeeze-and-Excitation (SE) n'est pas une structure de réseau complète, mais une sous-structure qui peut être intégrée dans d'autres modèles de classification ou de détection.
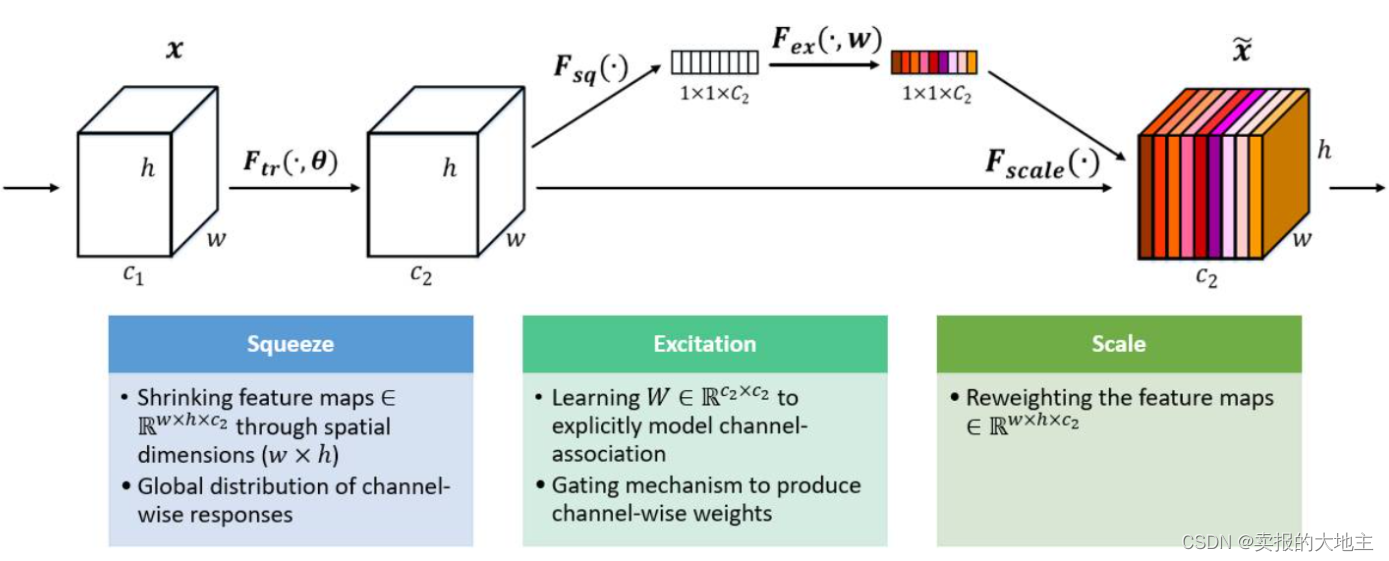
Ce qui précède est un diagramme schématique de la structure de SENet, et ses opérations clés sont la compression et l'excitation. L'importance de la carte des caractéristiques sur chaque canal est obtenue par apprentissage automatique, afin d'attribuer différents poids aux différents canaux et d'améliorer la contribution de canaux utiles.
Mécanisme de mise en œuvre :
- Squeeze : Compressez la grande caractéristique bidimensionnelle (h*w) de chaque canal en un nombre réel à travers la couche de mise en commun moyenne de l'ensemble du jeu, et la dimension change : (C, H, W) -> (C, 1, 1)
- Excitation : attribuez à chaque canal un poids d'entité, puis intégrez et extrayez des informations via deux couches entièrement connectées pour construire l'autocorrélation entre les canaux. Le nombre de poids de sortie est cohérent avec le nombre de canaux de carte d'entités, et la dimension change : (C, 1, 1) -> (C, 1, 1)
- Échelle : Pondérer les poids normalisés sur les caractéristiques de chaque canal. Dans le document, la pondération par multiplication est utilisée et la dimension change : (C, H, W) * (C, 1, 1) -> (C, H, W )
Implémentation de pytorch :
class SENet(nn.Module):
def __init__(self, in_channels, ratio=16):
super(SENet, self).__init__()
self.in_channels = in_channels
self.fgp = nn.AdaptiveAvgPool2d((1, 1))
self.fc1 = nn.Linear(self.in_channels, int(self.in_channels / ratio), bias=False)
self.act1 = nn.ReLU()
self.fc2 = nn.Linear(int(self.in_channels / ratio), self.in_channels, bias=False)
self.act2 = nn.Sigmoid()
def forward(self, x):
b, c, h, w = x.size()
output = self.fgp(x)
output = output.view(b, c)
output = self.fc1(output)
output = self.act1(output)
output = self.fc2(output)
output = self.act2(output)
output = output.view(b, c, 1, 1)
return torch.multiply(x, output)