1. Pénétration du cache
1.1. Description du problème
Lorsque le cache Redis est introduit dans le système, après l'arrivée d'une demande, il sera d'abord interrogé à partir du cache Redis, et s'il y a un cache, il sera renvoyé directement. S'il n'y a pas de cache, il sera interrogé dans la base de données. Certaines clés correspondent à plus de données qui n'existent pas dans la base de données. Chaque fois qu'une demande pour cette clé ne peut pas être obtenue à partir du cache, la demande sera pressée vers la base de données, ce qui peut submerger la base de données.
Par exemple, en utilisant un identifiant utilisateur inexistant pour obtenir des informations sur l'utilisateur, qu'il y ait un cache ou une base de données, si les pirates utilisent un grand nombre de ces attaques, la base de données peut être submergée.
1.2 Solutions
1.2.1. Cache pour les valeurs nulles
Si les données renvoyées par une requête sont vides (que la base de données existe ou non), nous mettons toujours en cache le résultat (null) et définissons un délai d'expiration court, jusqu'à cinq minutes.
1.2.2. Définir la liste accessible (liste blanche)
Utilisez le type bitmaps dans redis pour définir une liste accessible. L'identifiant de la liste est utilisé comme décalage des bitmaps. Chaque fois que l'exemple de texte est comparé à l'identifiant dans le bitmap, si l'identifiant consulté n'est pas dans les bitmaps, il sera être intercepté et l'accès n'est pas autorisé.
1.2.3, en utilisant le filtre Bloom
Le filtre Bloom (Bloom Filter) a été proposé par Bloom en 1970. Il s'agit en fait d'un vecteur binaire très long (bitmap) et d'une série de fonctions de mappage aléatoires (fonctions de hachage).
Le filtre Bloom peut être utilisé pour détecter si un élément se trouve dans une collection. Ses avantages sont que son efficacité spatiale et sa portée de requête dépassent de loin celles des algorithmes généraux. L'inconvénient est qu'il présente un certain taux d'erreur d'identification et des difficultés de suppression.
Hachez toutes les données possibles dans des bitmaps suffisamment grands, et une donnée qui ne doit pas exister sera interceptée par ces bitmaps, évitant ainsi la pression des requêtes sur le système de stockage sous-jacent.
1.2.4, Surveillance en temps réel
Lorsqu'il est constaté que le taux de réussite de redis commence à diminuer rapidement, il est nécessaire de vérifier les objets d'accès et les données consultées, de coopérer avec le personnel d'exploitation et de maintenance et de définir une liste noire pour restreindre le service qui lui est fourni (par exemple : liste noire IP)
2. Répartition du cache
2.1. Description du problème
Un raccourci clavier dans redis (une clé avec un volume d'accès élevé) expire. À ce moment, un grand nombre de requêtes arrivent en même temps, et il s'avère qu'il n'y a pas de réponse dans le cache. Ces requêtes sont toutes traitées sur le db, provoquant une augmentation instantanée de la pression sur la base de données, ce qui peut casser la base de données. Cette condition est appelée panne de cache.
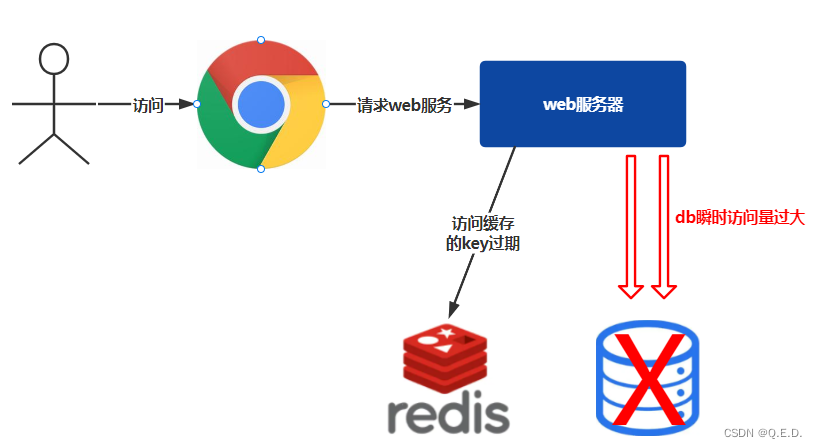
Phénomène de panne de cache
- Augmentation instantanée de la pression d'accès à la base de données
- Il n'y a pas un grand nombre d'expirations de clés dans redis
- Redis fonctionne normalement
2.2 Solutions
La clé peut être accessible avec une forte simultanéité à un moment donné, et il s'agit de données très "chaudes". À ce stade, un problème doit être pris en compte : le problème du cache étant "en panne". Les solutions courantes sont les suivantes : suit
2.2.1. Préréglez les données populaires et ajustez le délai d'expiration en temps voulu
Avant le pic de redis, stockez à l'avance certaines données populaires dans redis, surveillez ces données populaires dans le cache et ajustez le délai d'expiration en temps réel.
2.2.2. Utilisation des verrous
Lorsque les données ne sont pas disponibles dans le cache, au lieu d'interroger immédiatement la base de données, il s'agit d'obtenir un verrou distribué (tel que setnx dans redis), d'obtenir le verrou et de charger les données dans la base de données ; le thread qui n'obtient pas le verrou dort Réessayez toute la méthode de récupération des données après un certain temps.
3. Avalanche de cache
3.1. Description du problème
Les données correspondant à la clé existent, mais un grand nombre de clés expirent dans un laps de temps très court. À ce stade, si un grand nombre de requêtes simultanées arrivent et qu'il n'y a pas de données dans le cache, un grand nombre de requêtes tombera sur la base de données pour charger les données, et la base de données sera écrasée, provoquant le blocage du service.
La différence entre l'avalanche de cache et la panne de cache est que la première est l'expiration centralisée d'un grand nombre de clés, tandis que la seconde est l'expiration d'un certain raccourci clavier.
3.2 Solutions
L'impact de l'effet d'avalanche sur le système sous-jacent lorsque le cache est invalide est très terrible.Les solutions courantes sont les suivantes
3.2.1. Construire un cache à plusieurs niveaux
cache nginx + cache redis + autres caches (ehcache, etc.)
3.2.2. Utiliser des verrous ou des files d'attente
Utilisez des verrous ou des files d'attente pour vous assurer qu'il n'y aura pas un grand nombre de threads lisant et écrivant dans la base de données en même temps, afin d'éviter qu'un grand nombre de requêtes simultanées ne tombent sur le système de stockage sous-jacent en cas d'échec, ce qui n'est pas approprié. pour les situations de forte concurrence.
3.2.3. Surveiller l'expiration du cache et mettre à jour à l'avance
Surveillez le cache, signalez que le cache est sur le point d'expirer et mettez à jour le cache à l'avance.
3.2.4. Répartir l'heure d'invalidation du cache
Par exemple, nous pouvons ajouter une valeur aléatoire basée sur l'heure d'expiration d'origine, telle que 1 à 5 minutes aléatoires, afin que le taux de répétition de l'heure d'expiration du cache soit réduit et qu'il soit difficile de déclencher des événements d'échec collectifs.
4. Serrure distribuée
4.1. Description du problème
Avec les besoins du développement commercial, une fois le système de déploiement original sur une seule machine transformé en un système de cluster distribué, puisque le système distribué est multi-thread, multi-processus et distribué sur différentes machines, cela verrouillera le contrôle de la concurrence dans le situation de déploiement autonome d'origine La stratégie échoue et l'API Java pure ne peut pas fournir la capacité de verrous distribués. Pour résoudre ce problème, un mécanisme d'exclusion mutuelle entre JVM est nécessaire pour contrôler l'accès aux ressources partagées. C'est le problème que les serrures doivent résoudre.
4.2 Mise en œuvre généralisée des verrous distribués
- Réaliser un verrou distribué basé sur une base de données
- Basé sur le cache (redis, etc.)
- Basé sur le gardien de zoo
Chaque solution de serrure distribuée a ses propres avantages et inconvénients
- Performances : redis est le plus élevé
- Fiabilité : le gardien du zoo est le plus élevé
Ici, nous implémentons des verrous distribués basés sur redis.
4.3. Solution : utiliser redis pour implémenter des verrous distribués
Vous devez utiliser la commande suivante pour implémenter des verrous distribués
set key value NX PX 有效期(毫秒)
Cette commande signifie : lorsque la clé n'existe pas, définissez sa valeur sur valeur et définissez sa période de validité en même temps
exemple
set sku:1:info "ok" NX PX 10000Indique que lorsque sku:1:info n'existe pas, la valeur du paramètre est ok et la période de validité est de 10 000 millisecondes.
4.3.1. Le processus de verrouillage
Le processus est comme indiqué dans la figure ci-dessous. Exécutez la commande set key value NX PX validité period (milliseconds), retournez ok pour indiquer que l'exécution est réussie et que le verrou est acquis avec succès. Lorsque plusieurs clients exécutent cette commande simultanément, redis peut garantir qu'un seul peut s'exécuter avec succès.

4.3.2. Pourquoi le délai d'expiration doit-il être défini ?
Une fois que le client a acquis le verrou, en raison de problèmes système, tels qu'un temps d'arrêt du système, le verrou ne peut pas être libéré et les autres clients ne peuvent pas utiliser le verrou. Par conséquent, il est nécessaire de spécifier une durée de vie pour le verrou.
4.3.3. Que dois-je faire si la période de validité est trop courte ?
Par exemple, la période de validité est fixée à 10 secondes, mais 10 secondes ne suffisent pas pour le côté commercial.Dans ce cas, le client doit mettre en œuvre la fonction de prolongation de la durée de vie, ce qui peut résoudre ce problème.
4.3.4. Résoudre le problème de suppression accidentelle de verrous
Il existe un cas de suppression accidentelle du verrou : la suppression dite accidentelle consiste à supprimer le verrou détenu par d'autres.
Par exemple, lorsque le thread A acquiert le verrou, la période de validité définie est de 10 secondes, mais lors de l'exécution de l'activité, le programme A se bloque soudainement pendant plus de 10 secondes. À ce stade, le verrou peut être acquis par d'autres threads, tels que le thread B. , puis A récupère du gel et continue d'exécuter l'entreprise. Une fois l'entreprise exécutée, il exécute l'opération de libération du verrou. À ce moment, A exécute la commande del. À ce moment, le verrou est accidentellement supprimé, et le résultat est que le verrou détenu par B est libéré, puis d'autres threads acquerront à nouveau le verrou, ce qui est très grave.
Comment le résoudre?
Avant d'acquérir le verrou, générez un identifiant unique au monde et jetez cet identifiant dans la valeur correspondant à la clé. Avant de libérer le verrou, prenez l'identifiant de redis et comparez-le avec l'identifiant local pour voir s'il s'agit de votre propre identifiant. Si Oui, puis exécutez del pour libérer le verrou.
4.3.5. Il y a toujours la possibilité d'une suppression accidentelle (problème de fonctionnement atomique)
Comme mentionné ci-dessus, avant del, l'identifiant sera d'abord lu à partir de redis, puis comparé à l'identifiant local, s'ils sont cohérents, la suppression sera exécutée.Le pseudo-code est le suivant
step1:判断 redis.get("key").id==本地id 是否相当,如果是则执行step2
step2:del key;
A ce moment, si le propriétaire de la carte système est exécuté lors de l'exécution de l'étape 2, par exemple, le propriétaire de la carte attend 10 secondes, puis redis le reçoit. Pendant cette période, le verrou peut être acquis par d'autres threads, et une erreur accidentelle l'opération de suppression se produit à ce moment.
La cause première de ce problème est la suivante : les deux étapes de jugement et de suppression ne sont pas causées par des opérations atomiques pour redis, comment le résoudre ?
Besoin d'utiliser le script Lua pour résoudre.
4.3.6, la solution ultime : le script Lua pour libérer le verrou
Écrivez une opération redis complexe ou en plusieurs étapes sous forme de script et soumettez-la à redis pour exécution en une seule fois, réduisant ainsi le nombre de connexions répétées à redis et améliorant les performances.
Les scripts Lua sont similaires aux transactions Redis, ont une certaine atomicité, ne seront pas mis en file d'attente par d'autres commandes et peuvent effectuer certaines opérations de transaction Redis.
Mais faites attention à la fonction de script LUA de redis, qui ne peut être utilisée que dans redis2.6 ou supérieur.
code afficher comme ci-dessous:
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.script.DefaultRedisScript;
import org.springframework.http.MediaType;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.Arrays;
import java.util.UUID;
import java.util.concurrent.TimeUnit;
/**
* @className LockTest
* @date 2022/6/21
**/
@RestController
public class LockTest {
@Autowired
private RedisTemplate<String, String> redisTemplate;
@RequestMapping(value = "/lock", produces = MediaType.TEXT_PLAIN_VALUE)
public String lock() {
String lockKey = "k1";
String uuid = UUID.randomUUID().toString();
// 1.获取锁,有效期10秒
if (this.redisTemplate.opsForValue().setIfAbsent(lockKey, uuid, 10, TimeUnit.SECONDS)) {
// 2.执行业务
// todo 业务
//3.使用Lua脚本释放锁(可防止误删)
String script = "if redis.call('get',KEYS[1])==ARGV[1] then returnredis.call('del', KEYS[1]) else return 0 end ";
DefaultRedisScript<Long> redisScript = new DefaultRedisScript<>();
redisScript.setScriptText(script);
redisScript.setResultType(Long.class);
Long result = redisTemplate.execute(redisScript, Arrays.asList(lockKey), uuid);
System.out.println(result);
return "获取锁成功!";
} else {
return "加锁失败!";
}
}
}4.3.7 Résumé des verrous distribués
Afin de s'assurer que les verrous distribués sont disponibles, nous devons nous assurer que la mise en œuvre des verrous distribués répond aux quatre conditions suivantes en même temps
- Exclusion mutuelle, un seul client peut détenir le cadenas à tout moment
- Un blocage sans ambiguïté se produit, même si un client tombe en panne tout en maintenant le verrou et ne libère pas le verrou, cela peut également garantir que d'autres clients peuvent se verrouiller plus tard
- L'expéditeur doit être envoyé pour déverrouiller. Le même client doit être utilisé pour le verrouillage et le déverrouillage. Le client ne peut pas déverrouiller les serrures d'autres personnes.
- Le verrouillage et le déverrouillage doivent être atomiques