16. Résolution des problèmes d'application Redis
16.1 Pénétration du cache
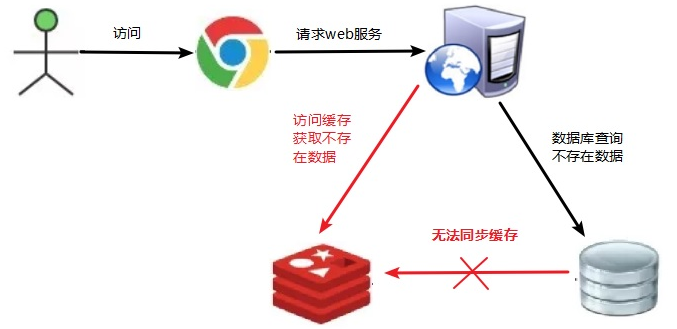
16.1.1 Description du problème
Les données correspondant à la clé n'existent pas dans la source de données. Chaque fois qu'une demande pour cette clé ne peut pas être obtenue à partir du cache, la demande sera pressée vers la source de données, ce qui peut submerger la source de données. Par exemple, en utilisant un identifiant utilisateur inexistant pour obtenir des informations sur l'utilisateur, ni le cache ni la base de données, si des pirates exploitent cette vulnérabilité pour attaquer, la base de données peut être submergée.
16.1.2 Solutions
Une donnée qui ne doit pas exister dans le cache et ne peut pas être interrogée, car le cache est écrit passivement lorsqu'il manque, et pour la tolérance aux pannes, si les données ne peuvent pas être trouvées à partir de la couche de stockage, elles ne seront pas écrites dans le cache, ce qui se traduira par ces données inexistantes. Chaque requête doit aller à la couche de stockage pour interroger, ce qui perd le sens de la mise en cache.
solution:
Mise en cache des valeurs nulles : si les données renvoyées par une requête sont vides (que les données n'existent pas ou non), nous mettons toujours en cache le résultat vide (null), et le délai d'expiration du résultat nul sera défini très court, non plus de cinq minutes
Définissez la liste accessible (liste blanche) :
Utilisez le type bitmaps pour définir une liste accessible. L'identifiant de la liste est utilisé comme décalage des bitmaps. Chaque visite est comparée à l'identifiant dans le bitmap. Si l'identifiant d'accès n'est pas dans les bitmaps, il sera intercepté et l'accès sera interdit.
Adoptez le filtre Bloom : (le filtre Bloom (Bloom Filter) a été proposé par Bloom en 1970. Il s'agit en fait d'un vecteur binaire très long (bitmap) et d'une série de fonctions de mappage aléatoires (fonctions de hachage).
Les filtres Bloom peuvent être utilisés pour déterminer si un élément se trouve dans un ensemble. Son avantage est que l'efficacité de l'espace et le temps de requête sont bien supérieurs à ceux de l'algorithme général, et l'inconvénient est qu'il existe un certain taux d'erreur d'identification et de difficulté de suppression. )
Hachez toutes les données possibles dans des bitmaps suffisamment grands, et une donnée qui ne doit pas exister sera interceptée par ces bitmaps, évitant ainsi la pression des requêtes sur le système de stockage sous-jacent.
Surveillance en temps réel : lorsqu'il est constaté que le taux de réussite de Redis commence à baisser rapidement, il est nécessaire de vérifier les objets d'accès et les données consultées, et de coopérer avec le personnel d'exploitation et de maintenance pour définir une liste noire afin de restreindre les services.
16.2 Répartition du cache
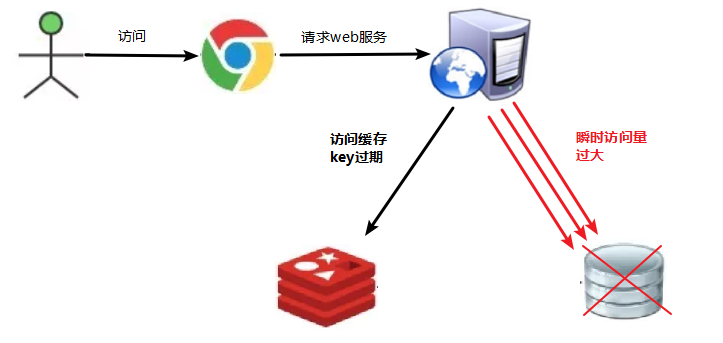
16.2.1 Description du problème
16.2.2 Solution
La clé peut être accessible à un certain moment avec une forte simultanéité, qui est une donnée très "chaude". À ce stade, un problème doit être pris en compte : le problème du cache "en panne".
Résoudre le problème:
(1) Données populaires prédéfinies : avant l'accès au pic de redis, stockez à l'avance certaines données populaires dans redis et augmentez la durée de ces clés de données populaires
(2) Ajustement en temps réel : surveillez les données les plus populaires sur le site et ajustez le délai d'expiration de la clé en temps réel
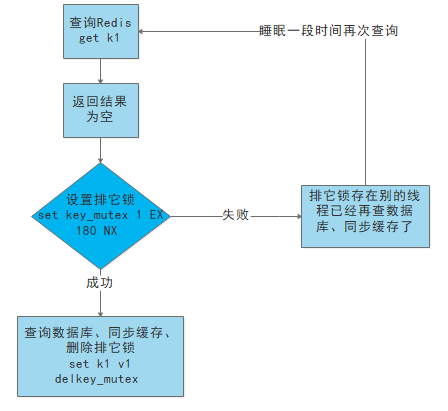
(3) Utilisez des serrures :
- C'est-à-dire que lorsque le cache est invalide (en jugeant que la valeur extraite est vide), il ne faut pas charger db immédiatement.
- Utilisez d'abord certaines opérations de l'outil de cache avec une valeur de retour d'opération réussie (comme SETNX de Redis) pour définir une clé mutex
- Lorsque l'opération revient avec succès, effectuez l'opération load db, réinitialisez le cache et enfin supprimez la clé mutex ;
- Lorsque l'opération échoue, cela prouve qu'il existe une base de données de chargement de thread et que le thread actuel dort pendant un certain temps avant de réessayer toute la méthode get cache.
16.3 Avalanche de cache
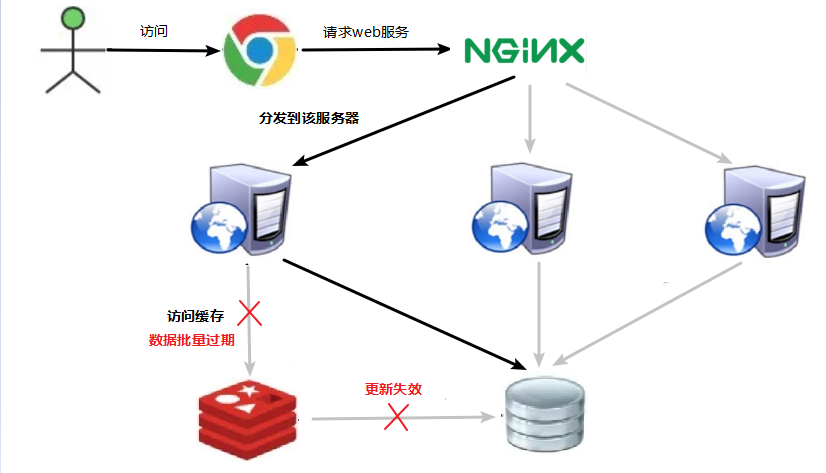
16.3.1 Description du problème
Les données correspondant à la clé existent, mais elles expirent dans redis. S'il y a un grand nombre de requêtes simultanées à ce moment, ces requêtes chargeront généralement les données de la base de données principale et les remettront dans le cache lorsqu'elles constateront que le cache a expiré. La base de données principale est écrasée.
La différence entre l'avalanche de cache et la panne de cache est qu'ici, c'est pour de nombreux caches de clés, tandis que le premier est l'accès normal d'une certaine clé

moment d'invalidation du cache
16.3.2 Solution
L'impact de l'effet d'avalanche sur le système sous-jacent lorsque le cache est invalide est terrible !
solution:
Créez une architecture de cache à plusieurs niveaux :
cache nginx + cache redis + autres caches (ehcache, etc.)
Utilisez des verrous ou des files d'attente :
Utilisez des verrous ou des files d'attente pour vous assurer qu'il n'y aura pas un grand nombre de threads lisant et écrivant dans la base de données en même temps, afin d'éviter qu'un grand nombre de demandes simultanées ne tombent sur le système de stockage sous-jacent en cas de panne. Ne convient pas à la haute simultanéité
Définissez l'indicateur d'expiration pour mettre à jour le cache :
Enregistrez si les données mises en cache expirent (définissez le montant de l'avance). Si elles expirent, elles déclencheront une notification à un autre thread pour mettre à jour le cache de clé réel en arrière-plan.
Étalez les délais d'expiration du cache :
Par exemple, nous pouvons ajouter une valeur aléatoire basée sur l'heure d'expiration d'origine, telle que 1 à 5 minutes aléatoires, de sorte que le taux de répétition de l'heure d'expiration de chaque cache sera réduit et qu'il sera difficile de déclencher des événements d'échec collectifs. .
16.4 Serrures distribuées
16.4.1 Description du problème
Avec les besoins du développement commercial, une fois le système de déploiement original sur une seule machine transformé en un système de cluster distribué, car le système distribué est multi-thread, multi-processus et distribué sur différentes machines, cela verrouillera le contrôle de la concurrence dans le situation de déploiement autonome d'origine La stratégie échoue et l'API Java pure ne peut pas fournir la possibilité de distribuer des verrous. Afin de résoudre ce problème, un mécanisme d'exclusion mutuelle inter-JVM est nécessaire pour contrôler l'accès aux ressources partagées. C'est le problème à résoudre par les verrous distribués !
L'implémentation standard des verrous distribués :
1. Réaliser un verrou distribué basé sur la base de données
2. Basé sur le cache (Redis, etc.)
3. Basé sur Zookeeper
Chaque solution de serrure distribuée a ses propres avantages et inconvénients :
1. Performances : Redis est le meilleur
2. Fiabilité : le gardien du zoo est le plus élevé
Ici, nous implémentons des verrous distribués basés sur redis.
16.4.2 Solution : Utiliser redis pour implémenter des verrous distribués
redis : commande
# set sku:1:info "OK" NX PX 10000
EX seconde : Réglez le délai d'expiration de la clé sur secondes secondes. La valeur de la clé SET EX seconde est équivalente à la valeur de la seconde clé SETEX.
PX milliseconde : Définissez le délai d'expiration de la clé en millisecondes millisecondes. La valeur de la clé SET en millisecondes PX est équivalente à la valeur en millisecondes de la clé PSETEX.
NX : Définissez la clé uniquement si la clé n'existe pas. La valeur de clé SET NX est équivalente à la valeur de clé SETNX.
XX : Définissez la clé uniquement si la clé existe déjà.
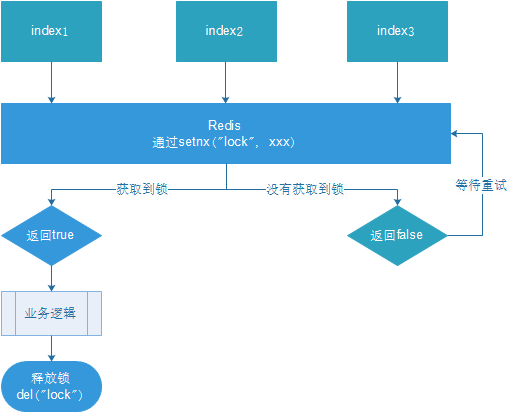
1. Plusieurs clients acquièrent simultanément des verrous (setnx)
2. L'acquisition est réussie, exécutez la logique métier {obtenir les données de la base de données, les mettre en cache}, relâchez le verrou (del) une fois l'exécution terminée
3. D'autres clients attendent une nouvelle tentative
16.4.3 Écriture de code
Renvoie : définit si 0
@GetMapping("testLock")
public void testLock(){
//1获取锁,setne
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", "111");
//2获取锁成功、查询num的值
if(lock){
Object value = redisTemplate.opsForValue().get("num");
//2.1判断num为空return
if(StringUtils.isEmpty(value)){
return;
}
//2.2有值就转成成int
int num = Integer.parseInt(value+"");
//2.3把redis的num加1
redisTemplate.opsForValue().set("num", ++num);
//2.4释放锁,del
redisTemplate.delete("lock");
}else{
//3获取锁失败、每隔0.1秒再获取
try {
Thread.sleep(100);
testLock();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
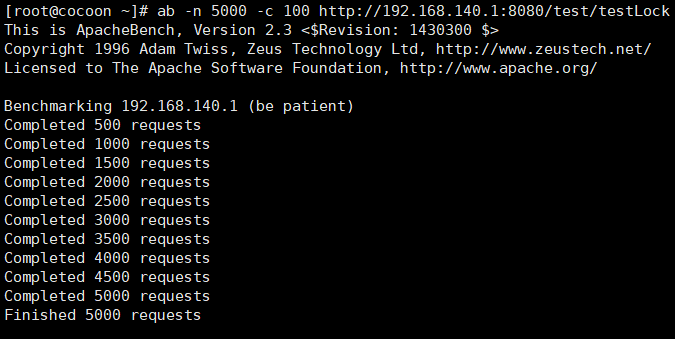
}Redémarrez, servez le cluster et réussissez le test de résistance de la passerelle :
ab -n 10 00 -c 100 http://192.168.140.1:8080/test/testLock
Affichez la valeur de num dans redis :
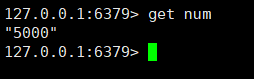
Fondamentalement réalisé.
Problème : setnx vient d'acquérir le verrou et la logique métier est anormale, ce qui fait que le verrou n'est pas libéré
Solution : Définissez le délai d'expiration et libérez automatiquement le verrou.
16.4.4 Optimisation pour définir le délai d'expiration du verrou
Il existe deux manières de définir le délai d'expiration :
1. Pensez d'abord à définir le délai d'expiration jusqu'à expire (manque d'atomicité : si une exception se produit entre setnx et expire, le verrou ne peut pas être libéré)
2. Spécifiez le délai d'expiration lors du réglage (recommandé)
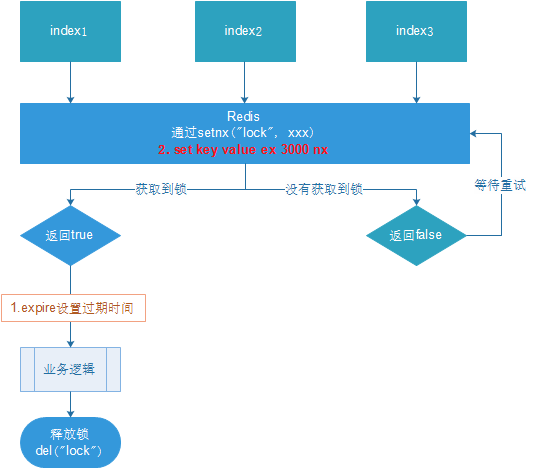
Définir l'heure d'expiration :
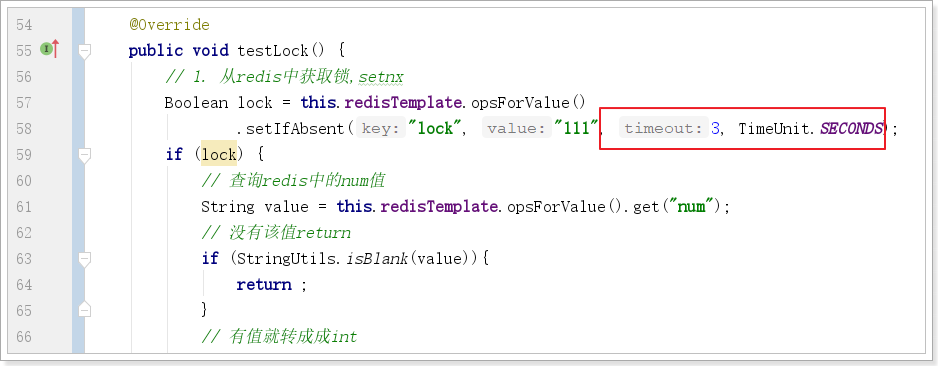
Le test d'effort n'est certainement pas un problème non plus. auto-test
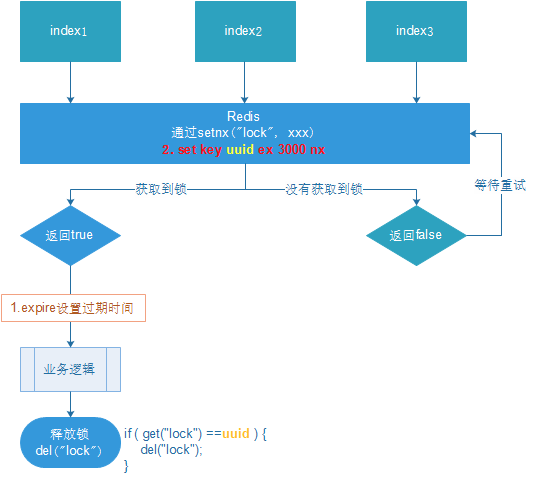
Problème : les verrous d'autres serveurs peuvent être libérés.
Scénario : Si le temps d'exécution de la logique métier est de 7 s. Le processus d'exécution est le suivant
- La logique métier index1 n'a pas été exécutée et le verrou est automatiquement relâché après 3 secondes.
- index2 acquiert le verrou, exécute la logique métier et le verrou est automatiquement libéré après 3 secondes.
- index3 acquiert le verrou et exécute la logique métier
- Une fois l'exécution de la logique métier de l'index1 terminée, del est appelée pour libérer le verrou. À ce moment, le verrou de l'index3 est libéré, provoquant la libération de l'activité de l'index3 par d'autres après seulement une seconde d'exécution.
En fin de compte, cela équivaut à la situation sans verrouillage.
Solution : lorsque setnx acquiert un verrou, définissez une valeur unique spécifiée (par exemple : uuid) ; obtenez cette valeur avant de la libérer et jugez s'il s'agit de son propre verrou
16.4.5 UUID optimisé pour éviter une suppression accidentelle
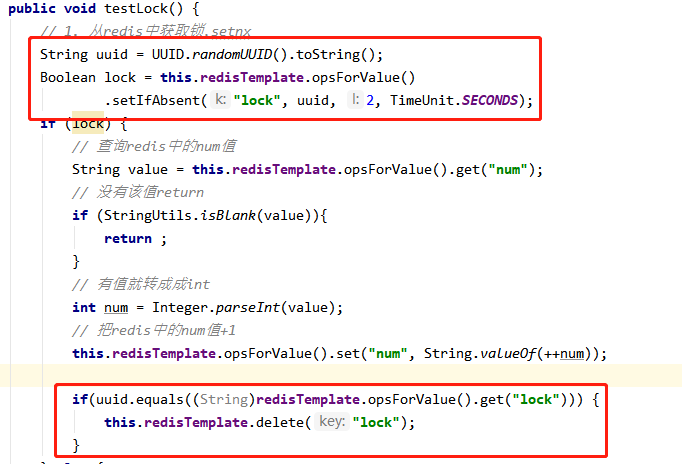
16.4.6 Le script LUA optimisé garantit l'atomicité de la suppression
@GetMapping("testLockLua")
public void testLockLua() {
//1 声明一个uuid ,将做为一个value 放入我们的key所对应的值中
String uuid = UUID.randomUUID().toString();
//2 定义一个锁:lua 脚本可以使用同一把锁,来实现删除!
String skuId = "25"; // 访问skuId 为25号的商品 100008348542
String locKey = "lock:" + skuId; // 锁住的是每个商品的数据
// 3 获取锁
Boolean lock = redisTemplate.opsForValue().setIfAbsent(locKey, uuid, 3, TimeUnit.SECONDS);
// 第一种: lock 与过期时间中间不写任何的代码。
// redisTemplate.expire("lock",10, TimeUnit.SECONDS);//设置过期时间
// 如果true
if (lock) {
// 执行的业务逻辑开始
// 获取缓存中的num 数据
Object value = redisTemplate.opsForValue().get("num");
// 如果是空直接返回
if (StringUtils.isEmpty(value)) {
return;
}
// 不是空 如果说在这出现了异常! 那么delete 就删除失败! 也就是说锁永远存在!
int num = Integer.parseInt(value + "");
// 使num 每次+1 放入缓存
redisTemplate.opsForValue().set("num", String.valueOf(++num));
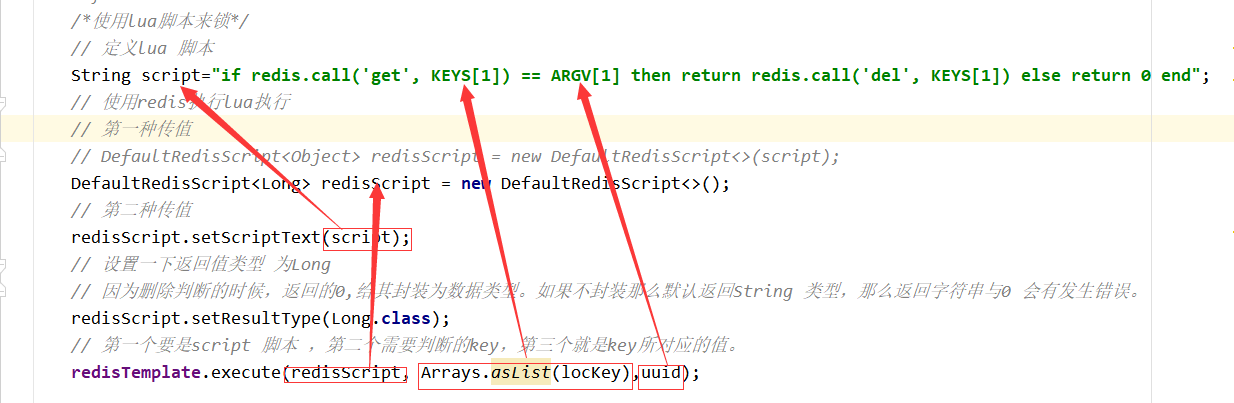
/*使用lua脚本来锁*/
// 定义lua 脚本
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
// 使用redis执行lua执行
DefaultRedisScript<Long> redisScript = new DefaultRedisScript<>();
redisScript.setScriptText(script);
// 设置一下返回值类型 为Long
// 因为删除判断的时候,返回的0,给其封装为数据类型。如果不封装那么默认返回String 类型,
// 那么返回字符串与0 会有发生错误。
redisScript.setResultType(Long.class);
// 第一个要是script 脚本 ,第二个需要判断的key,第三个就是key所对应的值。
redisTemplate.execute(redisScript, Arrays.asList(locKey), uuid);
} else {
// 其他线程等待
try {
// 睡眠
Thread.sleep(1000);
// 睡醒了之后,调用方法。
testLockLua();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
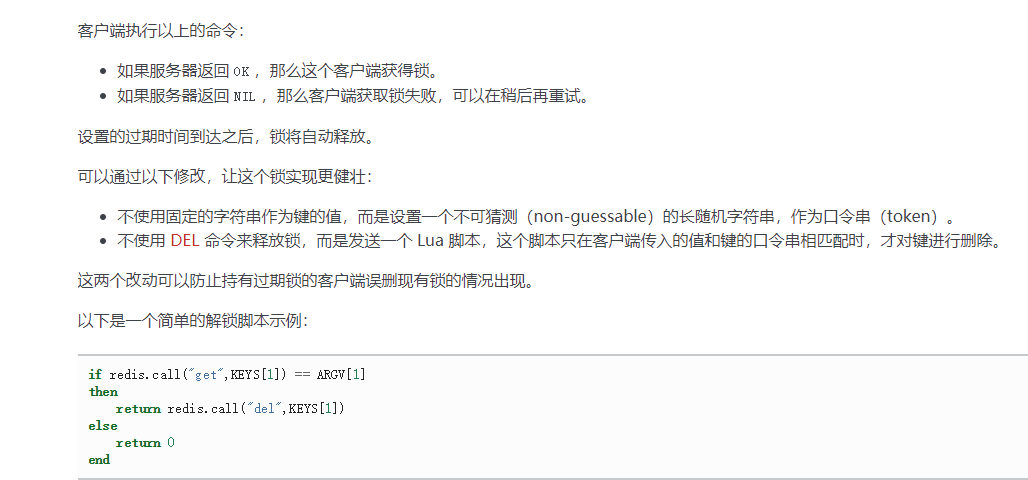
}Explication détaillée du script Lua :
Correctement utilisé dans le projet :
- Définissez la clé, la clé doit être définie pour chaque sku, c'est-à-dire que chaque sku a un verrou.
String locKey= "lock:" +skuId; // Les données de chaque produit sont verrouillées
Verrou booléen = redisTemplate .opsForValue().setIfAbsent(locKey, uuid, 3 ,TimeUnit.SECONDS ) ;
16.4.7 Résumé
1. Verrouiller
// 1.从redis中获取锁,set k1 v1 px 20000 nx
String uuid = UUID. randomUUID ().toString();
Verrou booléen = this . redisTemplate .opsForValue()
.setIfAbsent( "lock" , uuid, 2 , TimeUnit. SECONDS );
2. Utilisez lua pour libérer le verrou
// 2. Libérez le verrou del
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end " ;
// Définit le type de données renvoyé par le script lua DefaultRedisScript<Long> redisScript = new DefaultRedisScript<>(); // Définit le type de retour du script lua sur Long redisScript.setResultType(Long.class ); redisScript.setScriptText( script) ; redisTemplate .execute(redisScript, Arrays.asList ( " lock" ),uuid);
3. Réessayez
Fil de discussion. dormir ( 500 );
testVerrou();
Afin de s'assurer que les verrous distribués sont disponibles, il faut au moins s'assurer que l'implémentation des verrous respecte les quatre conditions suivantes :
- Exclusion mutuelle. À tout moment, un seul client peut détenir le verrou.
- Aucun blocage ne se produira. Même si un client tombe en panne alors qu'il maintient le verrou et ne le déverrouille pas activement, il peut garantir que d'autres clients pourront le verrouiller ultérieurement.
- Les ennuis devraient y mettre fin. Le verrouillage et le déverrouillage doivent être le même client, et le client lui-même ne peut pas déverrouiller le verrou ajouté par d'autres.
- Le verrouillage et le déverrouillage doivent être atomiques.