Annuaire d'articles
avant-propos
Dans le processus d'exploration du réseau, le travail le plus fondamental et le plus important consiste à comprendre les données. Aujourd'hui, je vais résumer les ensembles de données de tâches de segmentation que j'ai utilisés jusqu'à présent. Cet article de blog présentera en détail les ensembles de données de base : IRSTD-1k (Infrared Small Target Detection, le plus grand ensemble de données de détection d'image unique de cible faible infrarouge réel, prend en charge la segmentation sémantique de classification binaire); Pascal VOC2012 (TPattern Analysis, Stical Modeling and Apprentissage informatique d'un
ensemble de données de défi de vision par ordinateur de niveau mondial, prend en charge la segmentation sémantique multi-classes et la segmentation d'instances multi-classes );
iSAID (un ensemble de données à grande échelle pour la segmentation d'instances dans les images aériennes, le premier ensemble de données de référence pour la segmentation d'images aériennes).
1. IRSTD-1k
IRSTD-1k provient de l'article 2022CVPR "ISNet: Shape Matters for Infrared Small Target Detection", auteur Mingjing Zhang, joignez l' article de lien papier , ensemble de données de liaison de données .
Les ensembles de données de détection et de segmentation de cibles infrarouges faibles et petites présenteront les caractéristiques de "faible" et "petit", où "faible" fait référence au faible rapport signal/bruit de la cible, au faible contraste avec l'arrière-plan et à l'infrarouge faible intensité de rayonnement ; et "petit" fait référence à L'inconvénient est qu'il y a peu de pixels cibles et qu'il est difficile d'obtenir des informations de texture lors de la détection. L'ensemble de données IRSTD-Ik fournit 1 000 images réelles avec diverses formes d'objets, différentes tailles d'objets et un arrière-plan riche en encombrement avec des annotations précises au niveau des pixels. L'ensemble de données est divisé en deux dossiers, IRSTD1k_Img stocke des images réelles et IRSTD1k_Label stocke des masques d'étiquettes. Comme le montre l'image,


Cet ensemble de données peut être utilisé pour des tâches de segmentation d'images d'apprentissage en profondeur, et peut également étudier des algorithmes de détection basés sur le filtrage, des algorithmes de détection basés sur le système visuel humain, des algorithmes de détection basés sur des structures de données d'image et des algorithmes de détection de cibles infrarouges faibles et petites basés sur Algorithmes de détection de cibles d'apprentissage en profondeur.
Deux, Pascal VOC2012
1. Introduction aux données
Le jeu de données Pascal VOC2012 provient du défi PASCAL VOC (The PASCAL Visual Object Classes) est un défi de vision par ordinateur de classe mondiale.Le nom complet de PASCAL : Pattern Analysis, Stical Modeling and Computational Learning est une organisation en réseau financée par l'Union européenne . Le Challenge PASCAL VOC comprend principalement les catégories suivantes : Classification d'objets, Détection d'objets, Segmentation d'objets, Classification d'actions, etc. Un jeu de données peut accomplir 4 tâches. article , jeu de données , introduction .
-
Tâches de classification d'images et de détection d'objets

-
Tâches de segmentation, notez que la segmentation d'image comprend généralement la segmentation sémantique, la segmentation d'instance et la segmentation panoramique. La segmentation d'instance consiste à représenter chaque cible individuelle avec une couleur (l'image au milieu de la figure ci-dessous), tandis que la segmentation sémantique n'est que l'ensemble des même catégorie Les cibles sont représentées par la même couleur (image à droite dans la figure ci-dessous).

-
Tâche de reconnaissance du comportement

-
Tâche de détection de la disposition du corps humain
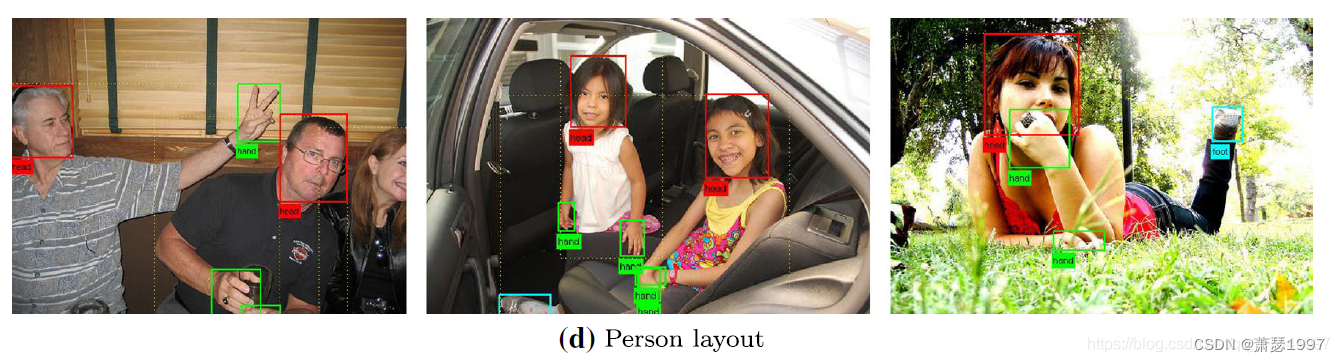
2. Introduction à l'ensemble de données de tâches de segmentation
- Le répertoire de dossiers obtenu en téléchargeant le jeu de données est le suivant
VOCdevkit
└── VOC2012
├── Annotations 所有的图像标注信息(XML文件)
├── ImageSets
│ ├── Action 人的行为动作图像信息
│ ├── Layout 人的各个部位图像信息
│ │
│ ├── Main 目标检测分类图像信息
│ │ ├── train.txt 训练集(5717)
│ │ ├── val.txt 验证集(5823)
│ │ └── trainval.txt 训练集+验证集(11540)
│ │
│ └── Segmentation 目标分割图像信息
│ ├── train.txt 训练集(1464)
│ ├── val.txt 验证集(1449)
│ └── trainval.txt 训练集+验证集(2913)
│
├── JPEGImages 所有图像文件
├── SegmentationClass 语义分割png图(基于类别)
└── SegmentationObject 实例分割png图(基于目标)
- Tâche de segmentation sémantique
Tout d'abord, lisez le fichier txt correspondant dans le fichier Segmentarion. Par exemple, utilisez les données de train.txt pour la formation, puis lisez le fichier txt, analysez chaque ligne et chaque ligne correspond à un index d'image. Utilisez les dossiers Segmentation et SegmentationClass.
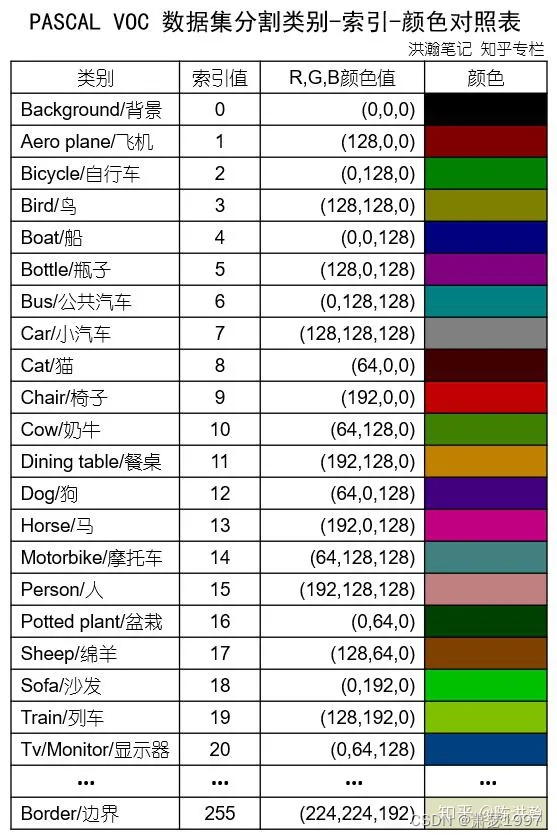
Notez qu'en segmentation sémantique, les couleurs correspondantes de chaque catégorie sont différentes. Par exemple, l'indice cible correspondant à une personne est 15, donc la valeur de pixel de la zone cible est remplie avec (192, 128, 128). Il y a 21 catégories au total. Les bordures ne comptent pas comme des catégories.
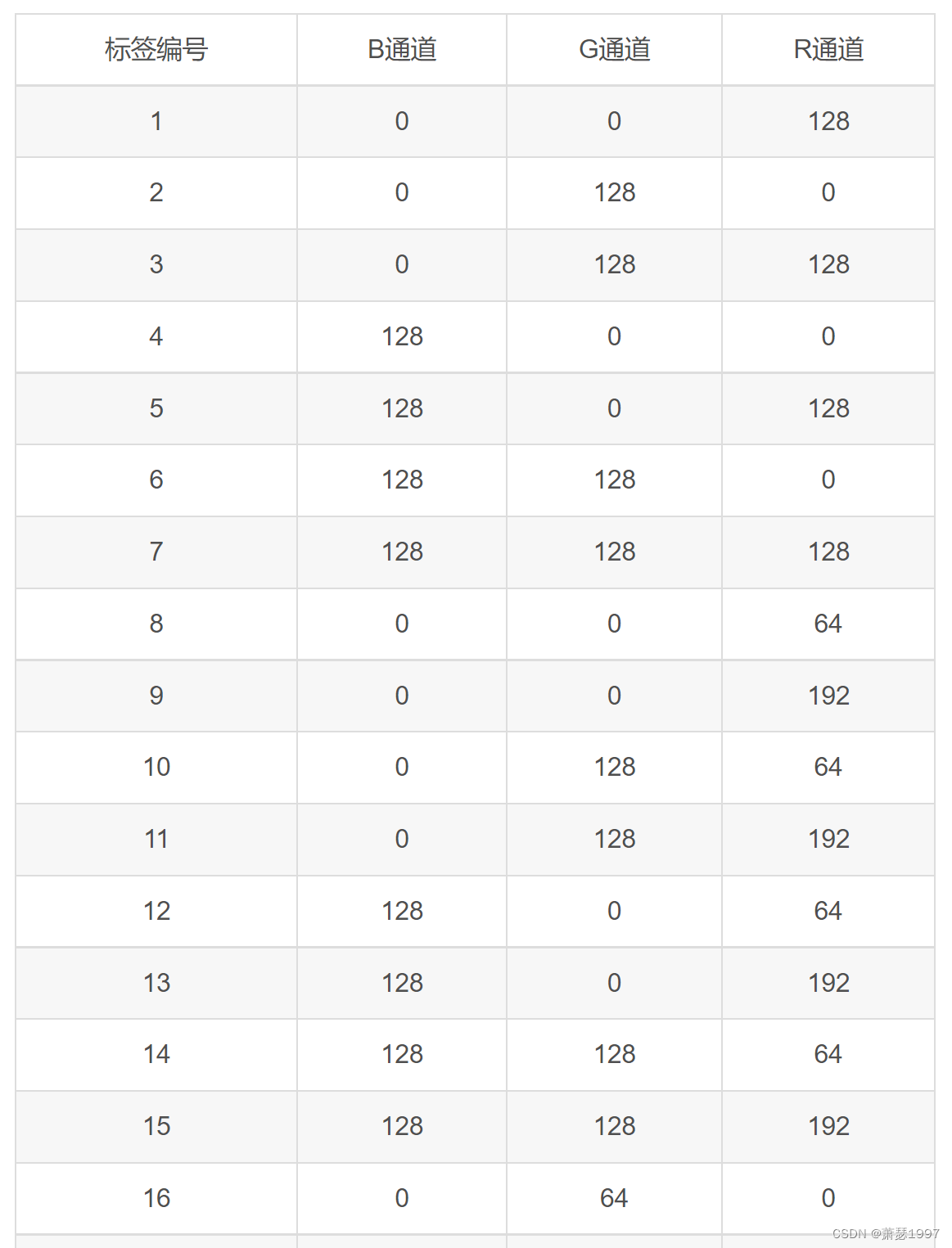
- Les tâches de segmentation d'instance
utilisent les dossiers Segmentation et SegmentationObject.
L'ordre des étiquettes de segmentation des instances correspond à l'étiquette de détection une par une, et les changements de couleur spécifiques sont les suivants :
- Remarques : Une partie du contenu ici est reproduite. Pour plus de détails, veuillez cliquer sur le lien d'origine : https://blog.csdn.net/qq_37541097/article/details/115787033
3. iSAID
L'ensemble de données iSAID et l'ensemble de données bien connu de détection de cibles à cadre rotatif de télédétection sont maintenus par l'équipe de Xia Guisong à l'Université de Wuhan. L'adresse officielle du site Web est : iSAID . iSAID contient 15 catégories, un total de 655 451 instances cibles et le nombre d'images atteint 2 806. Le nombre d'instances dans une seule image peut atteindre jusqu'à 8 000, avec une moyenne de 239. Il s'agit du premier ensemble de données de segmentation d'instance à grande échelle. dans le domaine de la télédétection.
iSAID utilise les images de l'ensemble de données DOTA pour l'annotation au niveau des pixels, corrigeant ainsi les erreurs d'étiquetage dans l'ensemble de données DOTA. Par rapport aux 188 282 instances cibles de DOTA, la taille de l'échantillon et la précision d'étiquetage fournies par iSAID sont considérablement augmentées. Les catégories cibles dans le l'ensemble de données comprend : avion, navire, réservoir de stockage, terrain de baseball, court de tennis, terrain de basket, terrain d'athlétisme, port, pont, gros véhicule, petit véhicule, hélicoptère, rond-point, piscine, terrain de football, couvrant essentiellement l'interprétation de l'urbain cible clé de télédétection. 1/2 des images marquées sont utilisées comme ensemble d'entraînement, 1/6 est utilisé pour l'ensemble de vérification et 1/3 est utilisé pour l'ensemble de test. Les ensembles d'entraînement et de vérification libèrent des images et des annotations gt en même temps, et seules les images peuvent être téléchargées pour l'ensemble de test. Le serveur d'évaluation officiel a été mis en place, qui peut être utilisé pour évaluer les performances de l'algorithme sur l'ensemble de test en ligne.
iSAID incarne pleinement la caractéristique commune et les différences de distribution d'échelle dans les images de télédétection. L'auteur stipule que 10 à 144 pixels sont de petites cibles, 144 à 1024 pixels sont des cibles moyennes et 1024 pixels et plus sont de grandes cibles. Le rapport des cibles de ces trois tailles est de 52,0 : 33,7 : 9,7. La différence de surface entre les objets les plus grands et les plus petits de l'ensemble de données peut aller jusqu'à 20 000 fois. De plus, il existe un grand nombre d'objets avec des rapports d'aspect extrêmes dans l'ensemble de données, jusqu'à 90 avec une moyenne de 2,4.

Le format de l'ensemble de données est relativement simple, il ne sera donc pas soigneusement développé.
- Remarques : une partie du contenu ici est réimprimée. Pour plus de détails, veuillez cliquer sur le lien d'origine : https://zhuanlan.zhihu.com/p/461021557
Résumer
En bref, il est très nécessaire de comprendre l'ensemble de données. Si vous avez des questions, veuillez laisser un message.