avant-propos
- Dans le blog précédent,
MMdetectionen plus d'être adapté aux tâches de détection de cibles, le framework peut également effectuer des tâches de segmentation d'instance. - Cependant,
MMdetectionle fichier de tutoriel sur la tâche de segmentation d'instance dans le projet officiel du framework signalera une erreur lors de l'opération réelle en raison de la mise à jour de la version du framework, donc cet articlecannot import name 'build_dataset' from 'mmdet.datasets'est principalement un tutoriel sur la segmentation d'instance pour la nouvelle version du cadre - Parce que le volume de données de l'
balloonensemble de données officiel est trop petit, l'ensemble de donnéeskagglesur la plate-forme est utilisé ici, l'adresse de donnéesMotorcycle Night Ride - Tous les codes suivants sont exécutés sur
kagglela plate-forme,GPUpourP100l'environnement.
Configuration de l'environnement
- Pour une description détaillée de cette partie, merci de vous référer à la partie configuration de l'environnement du blog MMDetection framework training and testing process , donc je n'entrerai pas dans les détails ici
import IPython.display as display
!pip install openmim
!mim install mmengine==0.7.2
!pip install -q /kaggle/input/frozen-packages-mmdetection/mmcv-2.0.1-cp310-cp310-linux_x86_64.whl
!rm -rf mmdetection
!git clone https://github.com/open-mmlab/mmdetection.git
!git clone https://github.com/open-mmlab/mmyolo.git
%cd mmdetection
!mkdir ./data
%pip install -e .
!pip install wandb
display.clear_output()
- Puisque nous utilisons
wandbla plateforme pour visualiser le processus de formation, nous devons également nous connecterwandbd'abord à la plateforme.
import wandb
wandb.login()
Inférence de modèle pré-entraîné
RTMDet-lNous téléchargeons d'abord les poids du modèle qui doivent être ajustés , puis effectuons une inférence sur l'image de test. Au fait, nous pouvons également vérifier si l'environnement est complet.- En ce qui concerne le numéro de modèle, il se
configs/rtmdettrouve dans les fichiers de projet. Mais il convient de noter qu'ilReadme.mdy a deux tables dans le document sontObject DetectionetInstance Segmentation, puisqu'il s'agit d'une tâche de segmentation d'instance, nous devrions rechercher le modèle de modèle dans la table `Segmentation d'instance``
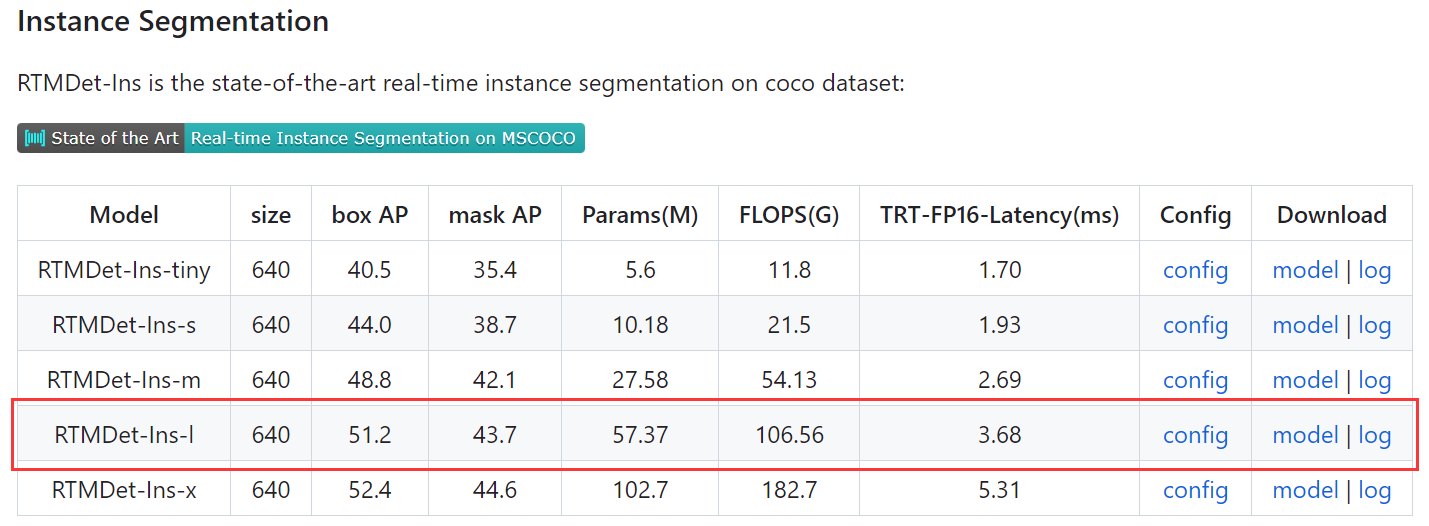
!mkdir ./checkpoints
!mim download mmdet --config rtmdet-ins_l_8xb32-300e_coco --dest ./checkpoints
- Inférence de modèle sur les images de test
import mmcv
import mmengine
from mmdet.apis import init_detector, inference_detector
from mmdet.utils import register_all_modules
config_file = 'configs/rtmdet/rtmdet-ins_l_8xb32-300e_coco.py'
checkpoint_file = 'checkpoints/rtmdet-ins_l_8xb32-300e_coco_20221124_103237-78d1d652.pth'
register_all_modules()
model = init_detector(config_file, checkpoint_file, device='cuda:0')
image = mmcv.imread('demo/demo.jpg',channel_order='rgb')
result = inference_detector(model, image)
from mmdet.registry import VISUALIZERS
visualizer = VISUALIZERS.build(model.cfg.visualizer)
visualizer.dataset_meta = model.dataset_meta
visualizer.add_datasample('result',image,data_sample=result,draw_gt = None,wait_time=0,)
display.clear_output()
visualizer.show()

Exploration et visualisation des données
- Parce que le nom du jeu de données est trop long, copiez le dossier d'image et le fichier d'annotation dans un
datasous-dossier du dossier du projet ici
import os
import shutil
def copy_files(src_folder, dest_folder):
# 确保目标文件夹存在
os.makedirs(dest_folder, exist_ok=True)
# 遍历源文件夹中的所有内容
for root, _, files in os.walk(src_folder):
for file in files:
# 拼接源文件的完整路径
src_file_path = os.path.join(root, file)
# 拼接目标文件的完整路径
dest_file_path = os.path.join(dest_folder, os.path.relpath(src_file_path, src_folder))
# 确保目标文件的文件夹存在
os.makedirs(os.path.dirname(dest_file_path), exist_ok=True)
# 复制文件
shutil.copy(src_file_path, dest_file_path)
source_folder = '/kaggle/input/motorcycle-night-ride-semantic-segmentation/www.acmeai.tech ODataset 1 - Motorcycle Night Ride Dataset'
destination_folder = './data'
copy_files(source_folder, destination_folder)
- Visualisation des données, puisque le graphique visualisé est déjà fourni dans l'ensemble de données, nous comparons le graphique original et le graphique annoté ensemble
import mmcv
import matplotlib.pyplot as plt
img_og = mmcv.imread('data/images/Screenshot (446).png')
img_fuse = mmcv.imread('data/images/Screenshot (446).png___fuse.png')
fig, axes = plt.subplots(1, 2, figsize=(15, 10))
axes[0].imshow(mmcv.bgr2rgb(img_og))
axes[0].set_title('Original Image')
axes[0].axis('off')
axes[1].imshow(mmcv.bgr2rgb(img_fuse))
axes[1].set_title('mask Image')
axes[1].axis('off')
plt.show()

- Utilisez
pycocotoolsla bibliothèque pour lire le fichier d'annotation et générer les informations de catégorie
from pycocotools.coco import COCO
# 初始化COCO对象
coco = COCO('data/COCO_motorcycle (pixel).json')
# 获取所有的类别标签和对应的类别ID
categories = coco.loadCats(coco.getCatIds())
category_id_to_name = {
cat['id']: cat['name'] for cat in categories}
display.clear_output()
# 打印所有类别ID和对应的类别名称
for category_id, category_name in category_id_to_name.items():
print(f"Category ID: {
category_id}, Category Name: {
category_name}")
- sortir:
Category ID: 1329681, Category Name: Rider
Category ID: 1323885, Category Name: My bike
Category ID: 1323884, Category Name: Moveable
Category ID: 1323882, Category Name: Lane Mark
Category ID: 1323881, Category Name: Road
Category ID: 1323880, Category Name: Undrivable
- Vous pouvez voir qu'il y a 6 catégories au total, à savoir : Rider, My bike, Moveable, Lane Mark, Road, Undrivable
Modifier le fichier de configuration
- Pour une explication détaillée du fichier de configuration, j'ai des instructions détaillées sur l'ensemble du processus de formation et de test du framework MMDetection dans le blog , et sur le réglage fin du modèle Mask2Former à l'aide de MMSegmentation .
- La principale modification est le chemin du poids avant l'entraînement, le chemin de l'image, le chemin du fichier d'annotation,
batch_size,epochs, la mise à l'échelle du taux d'apprentissage,nombre de catégories, multi-carte à mono-carte (SyncBN --> BN),Étiquettes de catégorie et palettes。 - Faites très attention aux deux paramètres de numéro de catégorie et d'étiquette de catégorie et de palette, sinon une erreur sera signalée
class EpochBasedTrainLoop in mmengine/runner/loops.py: class CocoDataset in mmdet/datasets/coco.py: need at least one array to concatenate. Ce type d'erreur est très, très courant. Vous devez vérifier si le numéro de catégorie et les informations d'étiquette sont corrects
from mmengine import Config
cfg = Config.fromfile('./configs/rtmdet/rtmdet-ins_l_8xb32-300e_coco.py')
from mmengine.runner import set_random_seed
cfg.load_from = 'checkpoints/rtmdet-ins_l_8xb32-300e_coco_20221124_103237-78d1d652.pth'
cfg.work_dir = './work_dir'
cfg.max_epochs = 100
cfg.stage2_num_epochs = 7
cfg.train_dataloader.batch_size = 4
cfg.train_dataloader.num_workers = 2
scale_factor = cfg.train_dataloader.batch_size / (8 * 32)
cfg.base_lr *= scale_factor
cfg.optim_wrapper.optimizer.lr = cfg.base_lr
# cfg.model.backbone.frozen_stages = 4
cfg.model.bbox_head.num_classes = 6
# 单卡训练时,需要把 SyncBN 改成 BN
cfg.norm_cfg = dict(type='BN', requires_grad=True)
cfg.metainfo = {
'classes': ('Rider', 'My bike', 'Moveable', 'Lane Mark', 'Road', 'Undrivable', ),
'palette': [
(141, 211, 197),(255, 255, 179),(190, 186, 219),(245, 132, 109),(127, 179, 209),(251, 180, 97),
]
}
cfg.data_root = './data'
cfg.train_dataloader.dataset.ann_file = 'COCO_motorcycle (pixel).json'
cfg.train_dataloader.dataset.data_root = cfg.data_root
cfg.train_dataloader.dataset.data_prefix.img = 'images/'
cfg.train_dataloader.dataset.metainfo = cfg.metainfo
cfg.val_dataloader.dataset.ann_file = 'COCO_motorcycle (pixel).json'
cfg.val_dataloader.dataset.data_root = cfg.data_root
cfg.val_dataloader.dataset.data_prefix.img = 'images/'
cfg.val_dataloader.dataset.metainfo = cfg.metainfo
cfg.test_dataloader = cfg.val_dataloader
cfg.val_evaluator.ann_file = cfg.data_root+'/'+'COCO_motorcycle (pixel).json'
cfg.val_evaluator.metric = ['segm']
cfg.test_evaluator = cfg.val_evaluator
cfg.default_hooks.checkpoint = dict(type='CheckpointHook', interval=10, max_keep_ckpts=2, save_best='auto')
cfg.default_hooks.logger.interval = 20
cfg.custom_hooks[1].switch_epoch = 300 - cfg.stage2_num_epochs
cfg.train_cfg.max_epochs = cfg.max_epochs
cfg.train_cfg.val_begin = 20
cfg.train_cfg.val_interval = 2
cfg.train_cfg.dynamic_intervals = [(300 - cfg.stage2_num_epochs, 1)]
# cfg.train_dataloader.dataset = dict(dict(type='RepeatDataset',times=5,dataset = cfg.train_dataloader.dataset))
cfg.param_scheduler[0].end = 100
cfg.param_scheduler[1].eta_min = cfg.base_lr * 0.05
cfg.param_scheduler[1].begin = cfg.max_epochs // 2
cfg.param_scheduler[1].end = cfg.max_epochs
cfg.param_scheduler[1].T_max = cfg.max_epochs //2
set_random_seed(0, deterministic=False)
cfg.visualizer.vis_backends.append({
"type":'WandbVisBackend'})
#------------------------------------------------------
config=f'./configs/rtmdet/rtmdet-ins_l_1xb4-100e_motorcycle.py'
with open(config, 'w') as f:
f.write(cfg.pretty_text)
- Commence l'entraînement
!python tools/train.py {
config}
- Affiche la valeur de l'indicateur avec la meilleure performance du modèle
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.561
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.758
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.614
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.017
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.195
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.633
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.543
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.645
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.649
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.036
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.246
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.721
07/23 19:31:52 - mmengine - INFO - segm_mAP_copypaste: 0.561 0.758 0.614 0.017 0.195 0.633
07/23 19:31:52 - mmengine - INFO - Epoch(val) [98][40/40] coco/segm_mAP: 0.5610 coco/segm_mAP_50: 0.7580 coco/segm_mAP_75: 0.6140 coco/segm_mAP_s: 0.0170 coco/segm_mAP_m: 0.1950 coco/segm_mAP_l: 0.6330 data_time: 0.0491 time: 3.1246
Visualisez le processus de formation
- Nous pouvons nous connecter à
wandbla plateforme pour voir les changements d'indicateurs pendant le processus de formation


- On peut voir
segm_mAPque la valeur continue d'augmenter. En raison de contraintes de temps, je n'ai exécuté que 100.epochSi vous l'essayez vous-même, vous pouvez essayer d'exécuter 300. On estime que l'effet sera meilleur.
Inférence sur les images de test
- Une fois la formation terminée, nous chargeons le modèle le plus performant et effectuons une inférence sur les images de test
from mmengine.visualization import Visualizer
import mmcv
from mmdet.apis import init_detector, inference_detector
import glob
img = mmcv.imread('data/images/Screenshot (446).png',channel_order='rgb')
checkpoint_file = glob.glob('./work_dir/best_coco_segm_mAP*.pth')[0]
model = init_detector(cfg, checkpoint_file, device='cuda:0')
new_result = inference_detector(model, img)
visualizer_now = Visualizer.get_current_instance()
visualizer_now.dataset_meta = model.dataset_meta
visualizer_now.add_datasample('new_result', img, data_sample=new_result, draw_gt=False, wait_time=0, out_file=None, pred_score_thr=0.5)
visualizer_now.show()

Dépannage
- Le fonctionnaire a écrit un document pour résoudre certains problèmes très courants, je mettrai l'adresse ici
- L'erreur la plus fréquente que j'ai rencontrée lors de l'exécution est qu'elle
valueerror-need-at-least-one-array-to-concatenateest également expliquée dans le manuel de dépannage officiel ci-dessus. Pour vérifier le nombre de catégories, de balises et de palettes, mais j'ai vérifié et trouvé qu'il n'y avait pas un tel problème, et j'ai finalement trouvé qu'il y avait un autre facteur qui pouvait causer cette erreur - En raison de la mise à jour du cadre,Étiquettes et palettesLa façon d'écrire a changé, et la mauvaise façon d'écrire est :
cfg.metainfo = {
'CLASSES': ('Rider', 'My bike', 'Moveable', 'Lane Mark', 'Road', 'Undrivable', ),
'PALETTE': [
(141, 211, 197),(255, 255, 179),(190, 186, 219),(245, 132, 109),(127, 179, 209),(251, 180, 97),
]
}
- Les majuscules
CLASSESetPALETTEne sont plus applicables dans la nouvelle version. Si vous souhaitez les mettre en minuscules, elles ne seront pas enregistrées
cfg.metainfo = {
'classes': ('Rider', 'My bike', 'Moveable', 'Lane Mark', 'Road', 'Undrivable', ),
'palette': [
(141, 211, 197),(255, 255, 179),(190, 186, 219),(245, 132, 109),(127, 179, 209),(251, 180, 97),
]
}