1. Introduction
Prometheus fournit une méthode de stockage de base de données de séries chronologiques de stockage local (TSDB). Après la version 2.0, la capacité de compresser les données a été considérablement améliorée (chaque donnée échantillonnée ne prend que de l'espace à gauche et à droite), et un seul nœud peut répondre aux exigences de 3.5byteexigences de la plupart des utilisateurs , mais le stockage local entrave la réalisation du clustering prometheus, de sorte que d'autres données de séries temporelles doivent être utilisées à la place dans le cluster, telles que influxdb.
Prometheus est divisé en trois parties : explorer les données , stocker les données et interroger les données .
Au début, il y avait un projet séparé appelé TSDB, mais dans 2.1.xune certaine version de , ce projet n'est plus maintenu séparément, et ce projet est directement fusionné dans le prometheustronc de .
Défauts de stockage Prometheus :
- L'agrégation entre les clusters n'est pas prise en charge
- Par exemple, dans notre environnement K8S actuel, les applications peuvent être déployées dans plusieurs clusters, ce qui créera plusieurs instances prometheus (projet + cluster crée une instance Prometheus), en supposant que chaque cluster a l'indicateur QPS, je veux maintenant comparer les trois Le Le QPS du cluster est moyenné (il s'agit d'une exigence normale), mais cela ne peut pas être fait et vous devez l'encapsuler dans votre propre code
- Solution : Il peut être résolu en déployant un cluster fédéré
- Ne prend pas en charge le stockage à long terme (notre stockage qke par défaut est de 90 jours)
2. Solution de stockage à long terme Promretheus
Avant l'émergence du stockage à long terme Prometheus, si les utilisateurs ont besoin d'agréger des données informatiques sur plusieurs clusters, la communauté propose une méthode de fédération.
Il existe un Global Prometheus sur la couche supérieure de plusieurs instances de Prometheus, qui est responsable de la récupération des données et du calcul dans chaque instance, afin de résoudre le problème du calcul agrégé inter-cluster. Cependant, si le volume de données de chaque cluster est important, l'instance unique de GlobalPrometheus rencontrera également des goulots d'étranglement.

En 2017, Prometheus a ajouté l'API de lecture/écriture à distance.Depuis lors, un grand nombre de solutions de stockage à long terme ont vu le jour dans la communauté, telles que Thanos, Grafana Cortex/Mimir, VictoriaMetrics, Wavefront, Splunk, Sysdig, SignalFx, InfluxDB , Graphite, etc...
À l'heure actuelle, la communauté Prometheus fournit également une prise en charge du stockage à distance pour les bases de données tierces :

Source : Section 5 : Stockage - Documentation chinoise Prometheus
Résumer:
- VictoriaMetrics est un meilleur choix pour conserver des données sur le disque dur, mais il convient de noter que VictoriaMetrics ne dispose pas d'une fonction de sous-échantillonnage open source. Si vous devez agréger et interroger sur une longue plage de temps, cela prendra beaucoup de temps.
- Dans la solution de la persistance des données au stockage d'objets, Thanos est plus populaire et Grafana Mimir a plus de potentiel.
- Thanos peut utiliser les données d'inventaire locales au lieu du stockage d'objets (Cortex/Mimir à vérifier).
- Grafana Fork Cortex, a créé Mimir et modifié la licence en AGPL-3.0. Le niveau d'investissement dans Grafana et la communauté à l'avenir est douteux, et il n'est pas recommandé de continuer à utiliser Cortex.
- Thanos/Cortex/Mimir s'empruntent les uns aux autres et ont des architectures similaires. Cortex/Mimir emprunte l'accès au stockage d'objets et la persistance de Thanos. Thanos emprunte à QueryFrontend de Cortex. En tant que version open source de Grafana Cloud, Mimir a fait plus d'optimisations basées sur l'architecture Thanos et Cortex.
De manière générale, si la licence ne vous dérange pas, vous pouvez utiliser Mimir.Si vous souhaitez une licence plus détendue, Thanos du projet d'incubation CNCF est un meilleur choix.
S'il n'y a pas de stockage d'objets, il est recommandé d'utiliser VictoriaMetrics (certaines fonctions importantes ne sont pas open source), et s'il y a du stockage d'objets, essayez d'utiliser Thanos ou Mimir.
Essayez de ne pas utiliser M3 sans raisons particulières.
3. Grafana Mimir
Source : [Grafana] Optimisation de Grafana Mimir dans les indicateurs de séries chronologiques massives
Recherche sur Grafana Mimir - Programmeur recherché
Grafan donne quelques raisons d'utiliser Mimir :
- 100 % compatible avec prometheus ;
- Copies multiples de haute disponibilité
- Expansion horizontale et partitionnement pour obtenir une requête rapide
- Multilocation et isolement des ressources
- Architecture distribuée, expansion dynamique
Depuis Grafana Mimir Fork Cortex, son architecture est très similaire à Cortex et Thanos.
Bien que Grafana Mimir s'appuie également sur la passerelle de magasin, le compacteur et la règle de Thanos, la différence avec Cortex est qu'un planificateur de requête de composant supplémentaire est ajouté entre le requêteur et l'interface de requête, ce qui satisfait mieux l'évolutivité du composant de requête.
L'évolutivité horizontale des composants Mimir (y compris le compacteur, la passerelle de magasin, la requête, la règle, etc.) est bonne. Il convient de mentionner que Mimir prend en charge la multi-location et l'expansion horizontale d'Alertmanage.
Désavantages:
- Licence : Grafana Mimir est basé sur la licence AGPL v3, qui n'est pas assez conviviale, car la licence nécessite : Si le projet introduit ce composant open source et modifie le code source, alors votre logiciel doit également être open source
- Les problèmes liés aux performances n'ont pas été entièrement vérifiés et l'heure de l'open source est relativement tardive
4. Mesures de Victoria
source:
Stockage distribué des données Prometheus à l'aide de VictoriaMetrics - Programmeur recherché
VictoriaMetrics — Motianlun Wiki
introduire
VictoriaMetrics est une base de données de séries chronologiques rapide, efficace et évolutive qui peut être utilisée comme stockage à long terme pour prometheus.
VictoriaMetrics présente les avantages suivants :
- Fournit une compression élevée des données
- Nécessite jusqu'à 7 fois moins de stockage que Prometheus, Thanos ou Cortex.
- requête vitesse de la lumière
- Il utilise efficacement tous les cœurs de processeur disponibles pour le traitement parallèle de milliards de lignes par seconde.
- Il est 20 fois supérieur à InfluxDB et TimescaleDB.
- Fournit une vue de requête globale
- Plusieurs instances Prometheus ou toute autre source de données peuvent ingérer des données dans VictoriaMetrics. Ces données peuvent ensuite être interrogées avec une seule requête.
- moins d'utilisation de la mémoire
- Il utilise 10 fois moins de RAM qu'InfluxDB et 7 fois moins que Prometheus, Thanos ou Cortex.
- VictoriaMetrics est une solution idéale pour le stockage à long terme de Prometheus
- Il implémente un langage de requête de type PromQL - MetricsQL , qui fournit des fonctionnalités améliorées en plus de PromQL.
Composants
La version cluster de victoriametrics comporte 3 types de processus, c'est-à-dire 3 types de microservices :
- vmstorage : nœud de stockage de données, responsable du stockage des données de séries chronologiques ;
- vmselect : nœud de requête de données, chargé de recevoir les requêtes des utilisateurs et d'interroger les données de séries chronologiques à partir de vmstorage ;
- Sans état, évolutif horizontalement
- vminsert : nœud d'insertion de données, chargé de recevoir les demandes d'insertion d'utilisateurs et d'écrire des données de séries chronologiques dans vmstorage ;
- Sans état, évolutif horizontalement
Lors du déploiement, différentes copies de différents microservices peuvent être déployées en fonction des besoins pour répondre aux besoins de l'entreprise :
- Si la quantité de données est relativement importante, déployez davantage de copies de vmstorage ;
- S'il y a beaucoup de demandes de requête, déployez plus de copies de vmselect ;
- S'il y a de nombreuses demandes d'insertion, déployez plus de copies de vminsert ;
déployer
La version à nœud unique
exécute directement un fichier binaire et peut être exécutée. La recommandation officielle est de collecter des points de données (points de données) inférieurs à 100 w/s. La version à nœud unique VM est recommandée. Elle est simple et facile à entretenir. , mais ne prend pas en charge les alarmes.
La version cluster
prend en charge le fractionnement horizontal des données et divise les fonctions en vmstorage, vminsert et vmselect. Si vous souhaitez remplacer Prometheus, vous avez également besoin de vmagent et de vmalert .
Les principales fonctionnalités de la version cluster :
- Toutes les fonctionnalités de la version à nœud unique sont prises en charge.
- Les performances et la capacité évoluent horizontalement.
- Prise en charge de plusieurs espaces de noms indépendants (multilocation) pour les données de séries chronologiques.
- Plusieurs copies sont prises en charge.
- Les graphiques sont plus puissants que les Proms
architecture
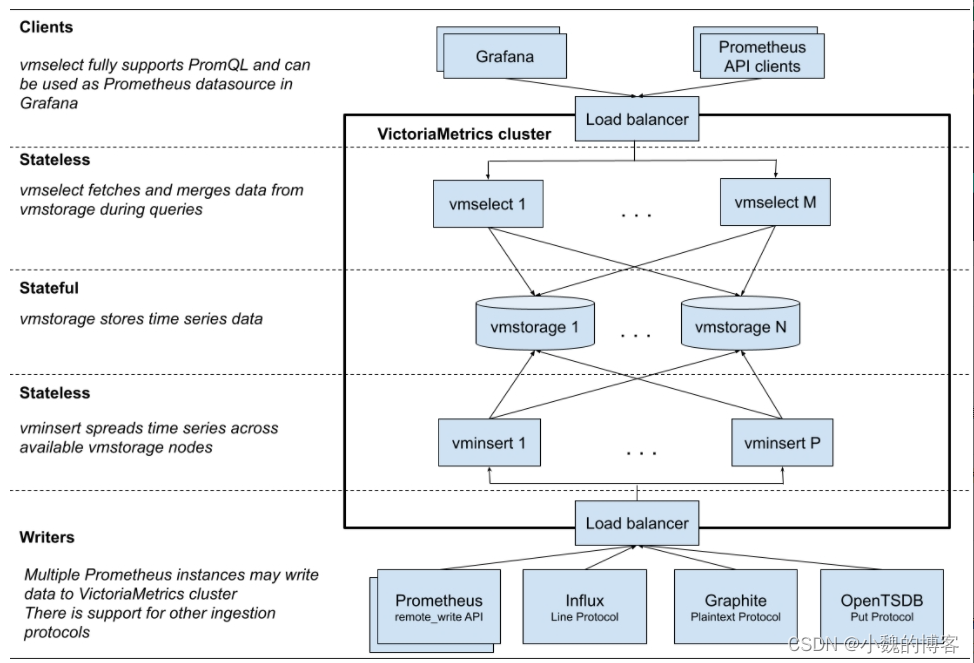
Données de requête VictoriaMetrics
Source : principe du cluster prometheus-VictoriaMetrics-article personnel-SegmentFault 思否
Prenons l'exemple des données de requête PromQL, combinées au code source pour analyser le processus d'interrogation des données dans la version de cluster victoriametrics.
Les données de requête sont traitées dans le service vmselect, en supposant que --replicationFactor=2, c'est-à-dire, data copy=2 :

Five, cluster Prometheus et haute disponibilité
Source : [Prometheus] Cluster Prometheus et haute disponibilité_cluster Prometheus_Young's Blog-CSDN Blog
Prometheus dispose d'une base de données de séries temporelles intégrée basée sur le stockage local. Dans la conception de Prometheus, l'utilisation du stockage local peut réduire la complexité du déploiement et de la gestion de Prometheus et réduire la complexité de la haute disponibilité (HA).
Par défaut, les utilisateurs doivent uniquement déployer plusieurs ensembles de Prometheus et collecter les mêmes cibles pour obtenir une haute disponibilité de base . Dans le même temps, grâce à la capacité de traitement des données efficace de Prometheus, un seul serveur Prometheus peut essentiellement répondre aux exigences d'échelle de surveillance de la plupart des utilisateurs.
Bien entendu, le stockage local apporte également quelques inconvénients :
- Tout d'abord : le problème de la persistance des données, en particulier dans un environnement de cluster dynamique comme Kubernetes, si l'instance de Promthues est replanifiée, toutes les données de surveillance historiques seront perdues.
- Deuxièmement : le stockage local signifie également que Prometheus n'est pas adapté pour sauvegarder une grande quantité de données historiques (généralement Prometheus recommande de ne conserver les données que quelques semaines ou mois). Enfin, le stockage local empêche également l'expansion élastique de Prometheus.
Afin de répondre aux besoins dans ce domaine, Prometheus fournit les fonctionnalités de remote_write et remote_read, qui prennent en charge le stockage des données à l'extrémité distante et la lecture des données à partir de l'extrémité distante. En séparant la surveillance des données, Prometheus est mieux à même d'évoluer de manière élastique.
En plus du problème de stockage local, puisque Prometheus est basé sur le modèle pull, lorsqu'un grand nombre de cibles doivent être échantillonnées, une seule instance de Prometheus peut rencontrer des problèmes de performances lors de la capture de données.
- Les caractéristiques du cluster fédéré permettent à Prometheus de diviser les tâches de collecte d'échantillons en différentes instances Prometheus et de les agréger via un nœud central unifié, de sorte que Prometheus puisse être étendu en fonction de l'échelle.
stockage à distance
La conception du stockage local de Prometheus peut réduire la complexité de son propre fonctionnement, de sa maintenance et de sa gestion, tout en répondant aux besoins de la plupart des utilisateurs en matière de surveillance de l'échelle. Mais le stockage local signifie également que Prometheus ne peut pas conserver les données, stocker une grande quantité de données historiques et ne peut pas se développer et migrer de manière flexible.
Afin de garder Prometheus simple, Prometheus n'essaie pas de résoudre les problèmes ci-dessus en lui-même, mais définit deux interfaces standard (remote_write/remote_read), permettant aux utilisateurs d'enregistrer des données sur n'importe quel stockage tiers basé sur ces deux interfaces Dans le service, cette méthode s'appelle le stockage à distance dans Promthues.
Écriture à distance
Les utilisateurs peuvent spécifier l'adresse URL de l'écriture à distance dans le fichier de configuration Prometheus. Une fois cet élément de configuration défini, Prometheus enverra les exemples de données collectés à l'adaptateur (Adaptor) sous la forme HTTP. L'utilisateur peut se connecter à n'importe quel service externe dans l'adaptateur. Le service externe peut être un système de stockage réel, un service de stockage en nuage public ou toute forme telle qu'une file d'attente de messages.
Lecture à distance
La lecture à distance de Promthues est également réalisée via un adaptateur. Dans le processus de lecture à distance, lorsque l'utilisateur lance une requête de requête, Promthues lancera une requête de requête (correspondants, plages) à l'URL configurée dans remote_read, et l'adaptateur obtiendra les données de réponse du service de stockage tiers selon les conditions de la demande. Dans le même temps, les données sont converties en exemples de données d'origine de Promthues et renvoyées au serveur Prometheus.
cluster fédéré
Grâce au stockage à distance, la surveillance de la collecte d'échantillons et le stockage des données peuvent être séparés pour résoudre le problème de persistance de Prometheus.
Cette partie se concentrera sur la façon d'utiliser la fonctionnalité de cluster fédéré pour étendre Promthues afin de s'adapter aux changements dans différentes échelles de surveillance.
Pour la plupart des échelles de surveillance, nous n'avons besoin d'installer qu'une seule instance de Prometheus Server dans chaque centre de données (par exemple : zone de disponibilité EC2, cluster Kubernetes), et nous pouvons gérer des milliers de clusters dans chaque centre de données. Dans le même temps, le déploiement de Prometheus Server dans différents centres de données peut éviter la complexité de la configuration du réseau.
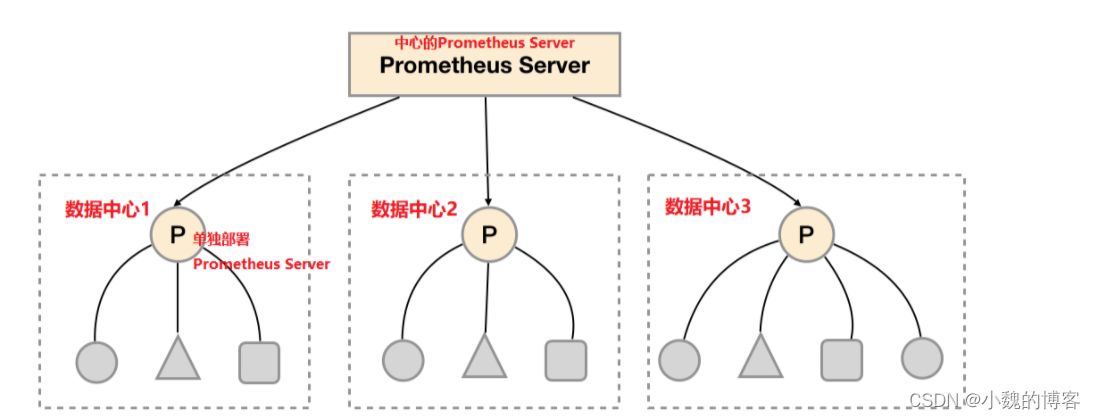
Comme illustré dans la figure ci-dessus, un serveur Prometheus distinct est déployé dans chaque centre de données pour collecter les données de surveillance actuelles du centre de données. Et un serveur Prometheus central est responsable de l'agrégation des données de surveillance de plusieurs centres de données. Cette fonctionnalité est appelée clustering fédéré dans Promthues.
Le cœur du cluster fédéré est que chaque serveur Prometheus inclut une interface/un fédéré pour obtenir des échantillons de surveillance dans l'instance actuelle . Pour le serveur Prometheus central, il n'y a en fait aucune différence si les données sont obtenues à partir d'autres instances Prometheus ou d'instances Exporter.
scrape_configs:
- job_name: 'federate'
scrape_interval: 15s
honor_labels: true
metrics_path: '/federate'
params:
'match[]':
- '{job="prometheus"}'
- '{__name__=~"job:.*"}'
- '{__name__=~"node.*"}'
static_configs:
- targets:
- '192.168.77.11:9090'
- '192.168.77.12:9090'Les caractéristiques des clusters fédérés peuvent aider les utilisateurs à ajuster l'architecture de déploiement de Promthues selon différentes échelles de surveillance. Par exemple, comme indiqué ci-dessous, plusieurs instances du serveur Prometheus peuvent être déployées dans chaque centre de données. Chaque instance Prometheus Server n'est responsable que de la collecte d'une partie des tâches (Jobs) dans le centre de données actuel. Par exemple, différentes tâches de surveillance peuvent être séparées dans différentes instances Prometheus, puis agrégées par l'instance centrale Prometheus.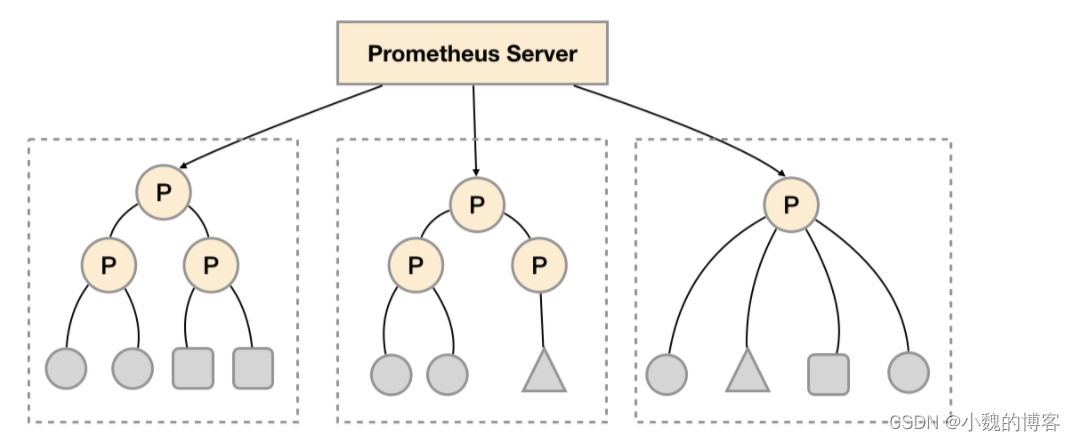
Le partitionnement fonctionnel, qui divise les tâches de collecte Prometheus au niveau des tâches selon les caractéristiques des clusters fédérés pour prendre en charge l'expansion de l'échelle.
Scénarios applicables pour les clusters fédérés :
- Scénario 1 : Centre de données unique + un grand nombre de tâches de collecte
- Dans ce scénario, le goulot d'étranglement des performances de Promthues réside principalement dans un grand nombre de tâches de collecte.Par conséquent, les utilisateurs doivent utiliser les caractéristiques des clusters fédérés Prometheus pour diviser différents types de tâches de collecte en différents sous-services Promthues afin d'obtenir un partitionnement fonctionnel.
- Scénario 2 : plusieurs centres de données
- Lorsque le serveur Promthues ne peut pas communiquer directement avec l'exportateur dans le centre de données, la fédération peut être utilisée
- Scénario 3 : Agrégation de données
- Lorsqu'une application est déployée sur plusieurs clusters Prometheus, lorsque les données de l'application doivent être interrogées, les données doivent être agrégées
Résumé de la haute disponibilité de Prometheus
Le stockage local de Prometheus apporte une expérience simple et efficace à Prometheus, permettant à Promthues de répondre aux besoins de surveillance de la plupart des utilisateurs dans le cas d'un seul nœud.
Cependant, le stockage local limite également l'évolutivité de Prometheus, ce qui entraîne une série de problèmes tels que la persistance des données. Cette série de problèmes peut être résolue grâce à la fonctionnalité de stockage à distance de Prometheus , y compris l'expansion dynamique de Promthues et le stockage des données historiques.
Outre le problème de la persistance des données, un autre facteur important affectant les performances de Promthues est la quantité de tâches de collecte de données et le nombre de séries chronologiques pouvant être traitées par un seul Promthues. Par conséquent, lorsque l'échelle de surveillance est si grande qu'un seul Promthues ne peut pas être géré efficacement, vous pouvez choisir d' utiliser les caractéristiques du cluster fédéré de Promthues pour diviser les tâches de surveillance de Promthues en différentes instances .
- Les utilisateurs n'ont qu'à déployer plusieurs ensembles de Prometheus et à collecter les mêmes cibles pour obtenir une haute disponibilité de base
- La persistance des données et l'évolutivité de Prometheus peuvent être résolues grâce à la fonction de stockage à distance de Prometheus
- Étendez Promthues en utilisant les caractéristiques des clusters fédérés , surveillez et traitez des volumes de données à grande échelle et réalisez une amélioration illimitée des capacités de traitement des données de Promthues
Cette partie se concentrera sur l'architecture haute disponibilité de Prometheus et présentera une solution haute disponibilité commune selon différents scénarios d'utilisation.
6. Cas
Notre prometheus s'applique actuellement à trois systèmes de fichiers NFS, un système de fichiers existe dans le cluster d'hébergement et un autre système de fichiers existe dans le cluster QKE, tous stockés dans le cloud (StorageClass).
Méthode de stockage : chaque instance de prometheus correspond à un répertoire, et s'il y a plusieurs instances de prometheus, cela correspond à plusieurs répertoires.
De plus, notez que chaque système de fichiers correspond à un objet libre StorageClass.
En prenant le cluster géré prometheus comme exemple, voici comment créer une StorageClass
Les deux fichiers clés :
Créez un objet de ressource StorageClass :
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: prometheus-data-03
provisioner: prometheus-data-03/nfs
reclaimPolicy: Retain
Une fois la StorageClass créée, le plug-in de stockage K8S est également requis pour le travail de stockage réel :
nfs-client-provisioner peut fournir dynamiquement des volumes pv pour kubernetes. Il s'agit de l'approvisionneur externe du NFS simple de Kubernetes. Il ne fournit pas NFS lui-même et a besoin du serveur NFS existant pour fournir le stockage. Les règles de nommage du répertoire de volume persistant sont : ${namespace}-${pvcName}-${pvName}.
kind: Deployment
apiVersion: apps/v1
metadata:
name: nfs-provisioner-03
spec:
selector:
matchLabels:
app: nfs-provisioner-03
replicas: 1
strategy:
type: Recreate
template:
metadata:
labels:
app: nfs-provisioner-03
spec:
serviceAccount: nfs-provisioner
containers:
- name: nfs-provisioner
image: docker-registry.xxx.virtual/hubble/nfs-client-provisioner:v3.1.0-k8s1.11
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME
value: prometheus-data-03/nfs
- name: NFS_SERVER
value: hubble-587ceb02-5e85e802.cnhz1.qfs.xxx.storage
- name: NFS_PATH
value: /hubble-wuhan-lkg
volumes:
- name: nfs-client-root
nfs:
server: hubble-587ceb02-5e85e802.cnhz1.qfs.xxx.storage
path: /hubble-wuhan-lkg
L'adresse du serveur ci-dessus est en fait l'adresse fournie par le stockage cloud :
Déployez prometheus :
kind: Service
apiVersion: v1
metadata:
name: prometheus-headless
namespace: example-nfs
labels:
app.kubernetes.io/name: prometheus
spec:
type: ClusterIP
clusterIP: None
selector:
app.kubernetes.io/name: prometheus
ports:
- name: web
protocol: TCP
port: 9090
targetPort: web
- name: grpc
port: 10901
targetPort: grpc
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
namespace: example-nfs
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: prometheus-example-nfs
subjects:
- kind: ServiceAccount
name: prometheus
namespace: example-nfs
roleRef:
kind: ClusterRole
name: prometheus
apiGroup: rbac.authorization.k8s.io
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: prometheus
namespace: example-nfs
labels:
app.kubernetes.io/name: prometheus
spec:
serviceName: prometheus-headless
podManagementPolicy: Parallel
replicas: 2
selector:
matchLabels:
app.kubernetes.io/name: prometheus
template:
metadata:
labels:
app.kubernetes.io/name: prometheus
spec:
serviceAccountName: prometheus
securityContext:
fsGroup: 1000
runAsUser: 0
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app.kubernetes.io/name
operator: In
values:
- prometheus
topologyKey: kubernetes.io/hostname
containers:
- name: prometheus
image: docker-registry.xxx.virtual/hubble/prometheus:v2.34.0
args:
- --config.file=/etc/prometheus/config_out/prometheus.yaml
- --storage.tsdb.path=/prometheus
- --storage.tsdb.retention.time=30d
- --web.external-url=/example-nfs/prometheus
- --web.enable-lifecycle
- --storage.tsdb.no-lockfile
- --storage.tsdb.min-block-duration=2h
- --storage.tsdb.max-block-duration=1d
ports:
- containerPort: 9090
name: web
protocol: TCP
livenessProbe:
failureThreshold: 6
httpGet:
path: /example-nfs/prometheus/-/healthy
port: web
scheme: HTTP
periodSeconds: 5
successThreshold: 1
timeoutSeconds: 3
readinessProbe:
failureThreshold: 120
httpGet:
path: /example-nfs/prometheus/-/ready
port: web
scheme: HTTP
periodSeconds: 5
successThreshold: 1
timeoutSeconds: 3
resources:
requests:
memory: 1Gi
limits:
memory: 30Gi
volumeMounts:
- mountPath: /etc/prometheus/config_out
name: prometheus-config-out
readOnly: true
- mountPath: /prometheus
name: prometheus-storage
- mountPath: /etc/prometheus/rules
name: prometheus-rules
- name: thanos
image: docker-registry.xxx.virtual/hubble/thanos:v0.25.1
args:
- sidecar
- --tsdb.path=/prometheus
- --prometheus.url=http://127.0.0.1:9090/example-nfs/prometheus
- --reloader.config-file=/etc/prometheus/config/prometheus.yaml.tmpl
- --reloader.config-envsubst-file=/etc/prometheus/config_out/prometheus.yaml
- --reloader.rule-dir=/etc/prometheus/rules/
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
ports:
- name: http-sidecar
containerPort: 10902
- name: grpc
containerPort: 10901
livenessProbe:
httpGet:
port: 10902
path: /-/healthy
readinessProbe:
httpGet:
port: 10902
path: /-/ready
volumeMounts:
- name: prometheus-config-tmpl
mountPath: /etc/prometheus/config
- name: prometheus-config-out
mountPath: /etc/prometheus/config_out
- name: prometheus-rules
mountPath: /etc/prometheus/rules
- name: prometheus-storage
mountPath: /prometheus
volumes:
- name: prometheus-config-tmpl
configMap:
defaultMode: 420
name: prometheus-config-tmpl
- name: prometheus-config-out
emptyDir: {}
- name: prometheus-rules
configMap:
name: prometheus-rules
volumeClaimTemplates:
- metadata:
name: prometheus-storage
labels:
app.kubernetes.io/name: prometheus
spec:
storageClassName: prometheus-data-03
accessModes:
- ReadWriteOnce
volumeMode: Filesystem
resources:
requests:
storage: 100Gi
limits:
storage: 300Gi
--storage.tsdb.min-block-duration : contrôle le temps de stockage des données, c'est-à-dire que le temps de stockage minimum est de 2 heures
--storage.tsdb.min-block-duration : contrôle le temps de placement des données, c'est-à-dire que le temps de placement maximum est de 1 jour
--storage.tsdb.retention.time Configurer la rétention locale de 30 jours de données pour réduire l'occupation de l'espace ;
Comme ci-dessus, volumeClaimTemplates consiste à définir un PVC, comment créer un PV ? Utilisez le modèle défini par StorageClass pour créer PV.
Alors, comment prometheus vérifie-t-il lors de l'interrogation des données ?
En fait, pour prometheus, il s'agit d'interroger des données à partir de l'interface fournie par l'instance de prometheus. Comme les conteneurs ordinaires, qu'il s'agisse d'un stockage en nuage, d'un stockage de nœud ou d'un autre stockage, il est transparent pour le conteneur, et c'est du montage à Le répertoire à interroger, donc l'extrémité distante doit vérifier le fichier de répertoire local pour prometheus.
7. Principe de stockage
Prometheus enregistre les échantillons collectés en séries temporelles dans la mémoire (base de données de séries temporelles TSDB) et les enregistre sur le disque dur à intervalles réguliers.
Différent de zabbix, zabbix enregistrera toutes les données, tandis que le stockage local prometheus sera enregistré pendant 15 jours et les données de plus de 15 jours seront supprimées.Il existe deux façons de stocker des données de manière permanente :
- Méthode 1 : Modifier le paramètre de configuration "storage.tsdb.retention.time=10000d" de prometheus ;
- Méthode 2 : stocker à distance les données dans Influcdb, VictoriaMetrics, etc.
- Méthode 3 : sous-échantillonnage
Prometheus stocke les données sous forme de blocs. Toutes les 2 heures est une unité de temps. Elle sera d'abord stockée dans la mémoire, et sera automatiquement écrite sur le disque lorsqu'elle atteindra 2 heures.
Afin d'éviter la perte de données causée par des exceptions de programme, le mécanisme WAL est adopté, c'est-à-dire que tandis que les données enregistrées dans les 2 heures sont stockées dans la mémoire, un journal est également enregistré et stocké dans le répertoire wal sous le bloc. Lorsque le programme redémarre, les données du répertoire wal seront écrites dans le bloc correspondant, de manière à obtenir l'effet de récupération des données.
Lors de la suppression de données, l'entrée supprimée est enregistrée dans les tombes au lieu d'être supprimée immédiatement.
La méthode de stockage utilisée par prometheus est appelée " time slicing ", et chaque bloc est une base de données indépendante. L'avantage est qu'il peut améliorer l'efficacité de la requête. Pour vérifier les données de quelle période, il vous suffit d'ouvrir le bloc correspondant, et il n'est pas nécessaire d'ouvrir des données redondantes.
8. Sauvegarde des données
1. Sauvegarde complète
La sauvegarde du répertoire de données de prometheus peut atteindre l'objectif d'une sauvegarde complète, mais l'efficacité est faible.
2. Sauvegarde d'instantanés
Prometheus fournit une fonction pour sauvegarder rapidement les données via l'API. Méthode à réaliser :
- Tout d'abord, modifiez les paramètres de démarrage de prometheus et ajoutez les deux paramètres suivants :
--storage.tsdb.path=/usr/local/share/prometheus/data \
--web.enable-admin-api- Ensuite, redémarrez prometheus
- Enfin, appelez l'interface backup :
# 不跳过内存中的数据,即同时备份内存中的数据
curl -XPOST http://127.0.0.1:9090/api/v2/admin/tsdb/snapshot?skip_head=false
# 跳过内存中的数据
curl -XPOST http://127.0.0.1:9090/api/v2/admin/tsdb/snapshot?skip_head=trueLe rôle de skip_head : s'il faut ignorer les données stockées dans la mémoire qui n'ont pas été écrites sur le disque, et les données qui sont toujours dans le bloc de bloc, la valeur par défaut est fausse
3. Restauration des données
Après avoir utilisé la méthode api pour créer un instantané, écrasez les fichiers de l'instantané dans le répertoire de données lors de la restauration et redémarrez prometheus !
Ajouter une tâche de sauvegarde planifiée ( sauvegarde tous les dimanches à 3 heures)
crontable -e #注意时区,修改完时区后,需要重启 crontab systemctl restart cron
0 3 * * 7 sudo /usr/bin/curl -XPOST -I http://127.0.0.1:9090/api/v1/admin/tsdb/snapshot >> /home/bill/prometheusbackup.log