Mise à l'échelle automatique des pods
J'ai mentionné précédemment que l'expansion et la contraction peuvent être réalisées en exécutant manuellement kubectl scaledes commandes et Dashboarden opérant sur Internet, mais après tout, elles doivent être actionnées manuellement une fois à chaque fois, et il n'est pas certain que le volume de demandes commerciales soit important, donc si il ne peut pas être automatisé PodC'est aussi une chose très gênante à agrandir et à rétrécir. Ce serait formidable si Kubernetesle système pouvait Podaugmenter et diminuer automatiquement en fonction des changements de charge actuels, car ce processus n'est pas fixe et se produit fréquemment, de sorte que la méthode manuelle n'est pas très réaliste.
Heureusement, Kubernetesnous avons mis à notre disposition un tel objet ressource : Horizontal Pod Autoscaling(Pod horizontal auto-scaling), abréviation HPA. C'est le principe le plus fondamental pour déterminer si le nombre de répliques doit être ajusté HAPen surveillant, analysant RCou Deploymentcontrôlant tous Podles changements de charge .PodHPA
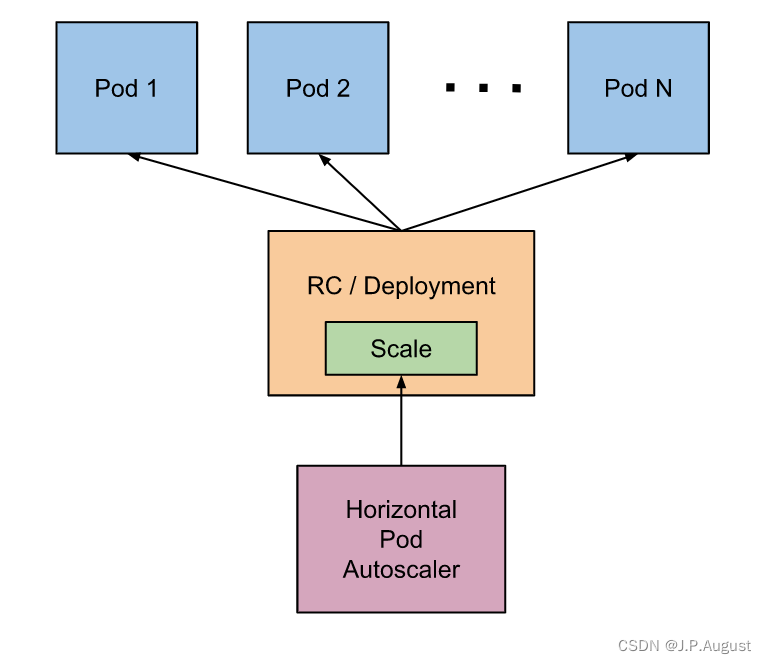
HPAkubernetesIl est conçu comme un seul dans le cluster , controllernous pouvons simplement kubectl autoscalecréer un HPAobjet de ressource via la commande, HPA Controllerle temps d'interrogation par défaut est de 30 secondes (peut être défini par kube-controller-managerle drapeau --horizontal-pod-autoscaler-sync-period), interroger l'utilisation des ressources dans la ressource spécifiée (RC ou déploiement) Pod, et Par rapport à la valeur et à l'index définis au moment de la création, la fonction de mise à l'échelle automatique peut être réalisée.
Après l'avoir créé HPA, vous obtiendrez la valeur moyenne de chaque taux d'utilisation ou valeur d'origine HPAà partir Heapsterdu terminal défini par l'utilisateur , puis le comparerez avec les indicateurs qui y sont définis, puis calculerez la valeur spécifique qui doit être mise à l'échelle et effectuerez les opérations correspondantes. . Actuellement, les données peuvent être obtenues à partir de deux endroits :RESTClientPodHPAHPA
- Heapster : ne prend en charge que
CPUl'utilisation - Surveillance personnalisée : Nous vous expliquerons comment utiliser cette partie dans l'article de surveillance suivant
Introduisons maintenant Heapsterla méthode d'expansion et de contraction automatique à partir de l'acquisition des données de surveillance, nous devons donc d'abord l'installer Heapster. Dans l' kubeadmarticle précédent sur la construction d'un cluster, nous avons en fait Heapstertiré les images pertinentes vers les nœuds par défaut, donc Ensuite, nous n'avons qu'à déployer. Nous utilisons Heapsterici la version 1.4.2. Allez Heapsterà githubla page :
https://github.com/kubernetes/heapster
Nous yamlenregistrons les fichiers sous ce répertoire dans notre cluster, puis utilisons kubectll'outil de ligne de commande pour les créer. De plus, une fois la création terminée, si nous avons besoin d' Dashboardy voir le graphique de surveillance, nous devons également Dashboardy configurer notre heapster-host.
De même, créons un pod Deploymentgéré Nginxet utilisons-le HPApour la mise à l'échelle automatique. DeploymentLe fichier défini YAMLest le suivant : (hap-deploy-demo.yaml)
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: hpa-nginx-deploy
labels:
app: nginx-demo
spec:
revisionHistoryLimit: 15
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
Créez ensuite Deployment:
$ kubectl create -f hpa-deploy-demo.yaml
Créons-en un maintenant HPA, qui peut être kubectl autoscalecréé avec la commande :
$ kubectl autoscale deployment hpa-nginx-deploy --cpu-percent=10 --min=1 --max=10
deployment "hpa-nginx-deploy" autoscaled
···
$ kubectl get hpa
NAME REFERENCE TARGET CURRENT MINPODS MAXPODS AGE
hpa-nginx-deploy Deployment/hpa-nginx-deploy 10% 0% 1 10 13s
Cette commande crée une ressource associée hpa-nginx-deploy HPA, le nombre minimum de réplicas de pod est 1 et le maximum est 10. HPALe nombre de pods sera dynamiquement augmenté ou diminué en fonction du taux d'utilisation du processeur défini (10 %).
Bien sûr, en plus d'utiliser kubectl autoscaledes commandes pour créer, nous pouvons toujours YAMLcréer HPAdes objets de ressource sous la forme de création de fichiers. Si nous ne savons pas comment l'écrire, nous pouvons vérifier le fichier créé par la HPAligne de commande ci-dessus YAML:
$ kubectl get hpa hpa-nginx-deploy -o yaml
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
creationTimestamp: 2017-06-29T08:04:08Z
name: nginxtest
namespace: default
resourceVersion: "951016361"
selfLink: /apis/autoscaling/v1/namespaces/default/horizontalpodautoscalers/nginxtest
uid: 86febb63-5ca1-11e7-aaef-5254004e79a3
spec:
maxReplicas: 5 //资源最大副本数
minReplicas: 1 //资源最小副本数
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment //需要伸缩的资源类型
name: nginxtest //需要伸缩的资源名称
targetCPUUtilizationPercentage: 50 //触发伸缩的cpu使用率
status:
currentCPUUtilizationPercentage: 48 //当前资源下pod的cpu使用率
currentReplicas: 1 //当前的副本数
desiredReplicas: 2 //期望的副本数
lastScaleTime: 2017-07-03T06:32:19Z
YAMLOk, maintenant nous pouvons créer un fichier de description basé YAMLsur le fichier ci-dessus HPA.
Maintenant, augmentons la charge à tester, créons-en un busyboxet parcourons les services créés ci-dessus.
$ kubectl run -i --tty load-generator --image=busybox /bin/sh
If you don't see a command prompt, try pressing enter.
/ # while true; do wget -q -O- http://172.16.255.60:4000; done
Comme vous pouvez le voir sur la figure ci-dessous, HPA a commencé à fonctionner.
$ kubectl get hpa
NAME REFERENCE TARGET CURRENT MINPODS MAXPODS AGE
hpa-nginx-deploy Deployment/hpa-nginx-deploy 10% 29% 1 10 27m
En même temps, nous vérifions le nombre de copies de la ressource associée hpa-nginx-deploy, et le nombre de copies est passé de 1 à 3.
$ kubectl get deployment hpa-nginx-deploy
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
hpa-nginx-deploy 3 3 3 3 4d
Dans le même temps, vérifiez à nouveau HPA, en raison de l'augmentation du nombre d'exemplaires, le taux d'utilisation est également resté aux alentours de 10 %.
$ kubectl get hpa
NAME REFERENCE TARGET CURRENT MINPODS MAXPODS AGE
hpa-nginx-deploy Deployment/hpa-nginx-deploy 10% 9% 1 10 35m
En même temps, éteignons-le busyboxpour réduire la charge, puis attendons un moment pour observer HPAet Deploymentobjecter
$ kubectl get hpa
NAME REFERENCE TARGET CURRENT MINPODS MAXPODS AGE
hpa-nginx-deploy Deployment/hpa-nginx-deploy 10% 0% 1 10 48m
$ kubectl get deployment hpa-nginx-deploy
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
hpa-nginx-deploy 1 1 1 1 4d
Vous pouvez voir que le nombre de copies est passé de 3 à 1.
Cependant, l'indicateur actuel HPAn'est que le taux d'utilisation, ce qui n'est pas très flexible. Dans les articles suivants, nous allons automatiquement étendre et réduire la capacité CPUen fonction de notre suivi personnalisé .Pod