Mise à l'échelle automatique horizontale du pod Kubernetes (HPA)
Entretien Scofield novice sur le fonctionnement et la maintenance
Introduction à HPA
HAP, le nom complet de l'autoscaler de pod horizontal, peut automatiquement mettre à l'échelle le nombre de pods dans ReplicationController, Deployment et ReplicaSet en fonction de l'utilisation du processeur. En plus de l'utilisation du processeur, une mise à l'échelle automatique peut également être effectuée sur la base de mesures personnalisées fournies par d'autres applications. La mise à l'échelle automatique du pod ne s'applique pas aux objets qui ne peuvent pas être mis à l'échelle, tels que DaemonSet.
La fonctionnalité de mise à l'échelle automatique horizontale du pod est implémentée par les ressources et les contrôleurs de l'API Kubernetes. La ressource détermine le comportement du contrôleur. Le contrôleur ajuste périodiquement le nombre de répliques dans le contrôleur de réplique ou le déploiement afin que l'utilisation moyenne du processeur du pod corresponde à la valeur cible définie par l'utilisateur.
Schéma de principe du mécanisme de fonctionnement du Pod HAP
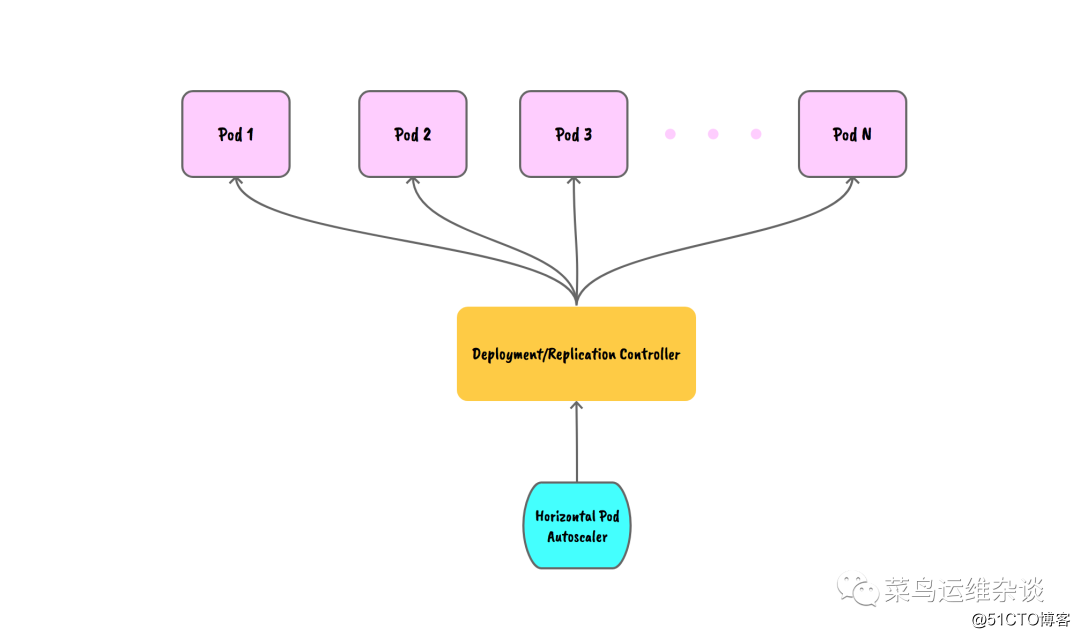
Dans la production réelle, ces quatre types d'indicateurs sont largement utilisés:
1. Mesures de ressources - Indicateurs d'utilisation de la mémoire centrale du processeur.
2. Mesures de pod - telles que l'utilisation du réseau et le trafic.
3. Métriques d'objets pour des objets spécifiques, tels que Ingress. Les conteneurs peuvent être étendus en fonction du nombre de requêtes par seconde.
4. Mesures personnalisées - Surveillance personnalisée, par exemple en définissant le temps de réponse du service, et s'étendant automatiquement lorsque le temps de réponse atteint un certain index
Bon, parlons du concept. Si vous voulez en savoir plus, veuillez consulter le site officiel et commencer le combat maintenant.
Exemple
1. Tout d'abord, nous déployons un nginx, le nombre de copies est de 2 et la ressource CPU demandée est de 200m. Dans le même temps, pour des tests bon marché, utilisez NodePort pour exposer les services. Espace de noms: hpa
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx
name: nginx
namespace: hpa
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx
name: nginx
resources:
requests:
cpu: 200m
memory: 100Mi
---
apiVersion: v1
kind: Service
metadata:
name: nginx
namespace: hpa
spec:
type: NodePort
ports:
- port: 80
targetPort: 80
selector:
app: nginx2. Afficher les résultats du déploiement
[root@k8s-node001 HPA]# kubectl get po -n hpa
NAME READY STATUS RESTARTS AGE
nginx-5c87768685-48b4v 1/1 Running 0 8m38s
nginx-5c87768685-kfpkq 1/1 Running 0 8m38s3. Créez
brièvement HPA : Ici, créez un HPA pour contrôler le déploiement que nous avons créé à l'étape précédente, de sorte que le nombre de copies de pod soit maintenu entre 1 et 10.
HPA augmentera ou diminuera le nombre de copies de pod (via le déploiement) pour maintenir l'utilisation moyenne du processeur de tous les pods à moins de 50%.
Algorithme voir
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: nginx
namespace: hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: nginx
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 504. Afficher les résultats du déploiement
[root@k8s-node001 HPA]# kubectl get hpa -n hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
nginx Deployment/nginx 0%/50% 1 10 2 50s5. Testez la pression, observez le numéro de pod et le changement HPA et
exécutez la commande de test de pression
[root@k8s-node001 ~]# ab -c 1000 -n 100000000 http://192.168.100.185:30792/
This is ApacheBench, Version 2.3 <$Revision: 1843412 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking 192.168.100.185 (be patient)Observez les changements
[root@k8s-node001 HPA]# kubectl get hpa -n hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
nginx Deployment/nginx 303%/50% 1 10 7 12m
[root@k8s-node001 HPA]# kubectl get po -n hpa
NAME READY STATUS RESTARTS AGE
pod/nginx-5c87768685-6b4sl 1/1 Running 0 85s
pod/nginx-5c87768685-99mjb 1/1 Running 0 69s
pod/nginx-5c87768685-cls7r 1/1 Running 0 85s
pod/nginx-5c87768685-hhdr7 1/1 Running 0 69s
pod/nginx-5c87768685-jj744 1/1 Running 0 85s
pod/nginx-5c87768685-kfpkq 1/1 Running 0 27m
pod/nginx-5c87768685-xb94x 1/1 Running 0 69sIl ressort du résultat ci-dessus que hpa TARGETS a atteint 303% et doit être élargi. Le nombre de pods est automatiquement porté à 7.
Continuez à attendre la fin du test de pression ou interrompez directement le test de pression
[root@k8s-node001 ~]# kubectl get hpa -n hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
nginx Deployment/nginx 20%/50% 1 10 7 16m
。。。N分钟后。。。
[root@k8s-node001 ~]# kubectl get hpa -n hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
nginx Deployment/nginx 0%/50% 1 10 7 18m
。。。再过N分钟后。。。
[root@k8s-node001 ~]# kubectl get po -n hpa
NAME READY STATUS RESTARTS AGE
nginx-5c87768685-jj744 1/1 Running 0 11mÀ ce stade, l'utilisation du processeur est tombée à 0, donc HPA réduira automatiquement le nombre de copies à 1.
Ici, nous devons faire attention: pourquoi le nombre de répliques serait-il réduit à 1, au lieu des répliques: 2 spécifiées lors du déploiement?
Parce que lorsque HPA a été créé, le nombre de répliques a été spécifié, voici minReplicas: 1, maxReplicas: 10. Donc HPA a été réduit à 1 lors de la réduction du nombre de copies.
Conseils: La mise à l'échelle automatique peut prendre plusieurs minutes pour terminer la modification du nombre de copies.
Pour résumer

PS: les articles de suivi seront synchronisés avec dev.kubeops.net
Remarque: les images de l'article proviennent d'Internet. En cas d'infraction, veuillez me contacter pour la supprimer à temps.