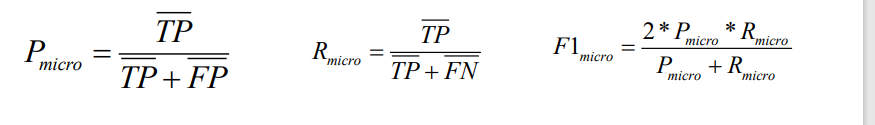Annuaire d'articles
1. Concepts de base
Vrais/vrais positifs (TP) : positifs prédits correctement
Vrais négatifs/vrais négatifs (TF) :
négatifs Faux positifs/faux positifs (FT) : positifs prédits à tort, réels négatifs
Faux négatifs/faux négatifs (FP) : prédits à tort comme négatif, en fait positif
2. Matrice de confusion
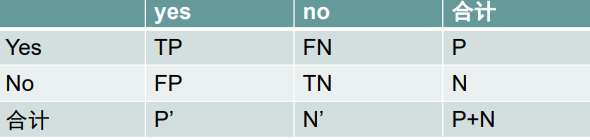
Parmi eux, la première ligne peut être considérée comme le positif réel, la deuxième ligne peut être considérée comme le faux réel,
la première colonne peut être considérée comme le positif prédit et la deuxième colonne peut être considérée comme le faux prédit.
Taux de précision, taux de reconnaissance : (TP + TN) / (TP + FN + FP + TN)
taux d'erreur : (FP + FN) / (TP + FN + FP + TN)
taux de rappel (dans l'exemple positif réel, la prédiction est positif Proportion d'exemples) : TP / (TP + FN)
Taux de précision (proportion d'exemples positifs réels prédits comme exemples positifs) : TP / (TP + FP)
Score F : (2 * rappel * précision) / (précision + rappel )
3. Indice d'évaluation du modèle multi-classification
Moyenne macro :
la moyenne arithmétique de chaque valeur d'indice statistique de toutes les catégories, telles que la précision macro, le rappel macro et la valeur F macro.
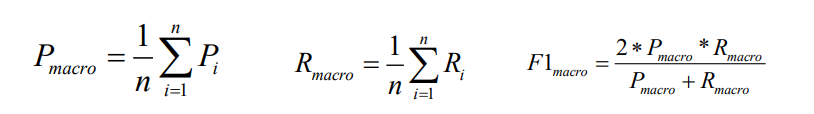
Micro Average (micro moyenne)
combine toutes les catégories de TP, FP, TN et FN respectivement pour établir une matrice de confusion globale, le taux de micro-précision correspondant, le taux de micro-rappel et la valeur micro-F.