format de stockage de fichiers
Depuis le site Web officiel de Hive, Apache Hive prend en charge plusieurs formats de fichiers familiers utilisés dans Apache Hadoop, tels que les formats TextFile(文本格式), RCFile(行列式文件), SequenceFile(二进制序列化文件), et AVRO, dont nous utilisons actuellement , et .ORC(优化的行列式文件)ParquetTextFileSequenceFileORCParquet
Examinons de plus près ces deux stockages déterminants.
1、ORC
1.1 Structure de stockage ORC
Nous obtenons d'abord le diagramme du modèle de stockage ORC sur le site officiel
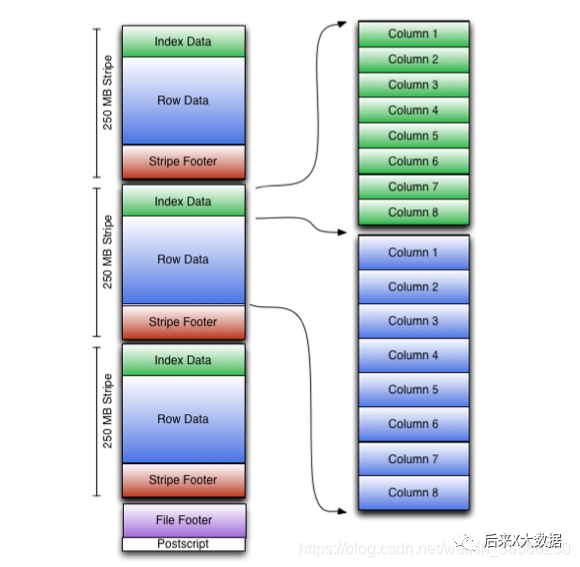
Cela semble un peu compliqué, alors simplifions un peu, j'ai dessiné un schéma simple pour illustrer
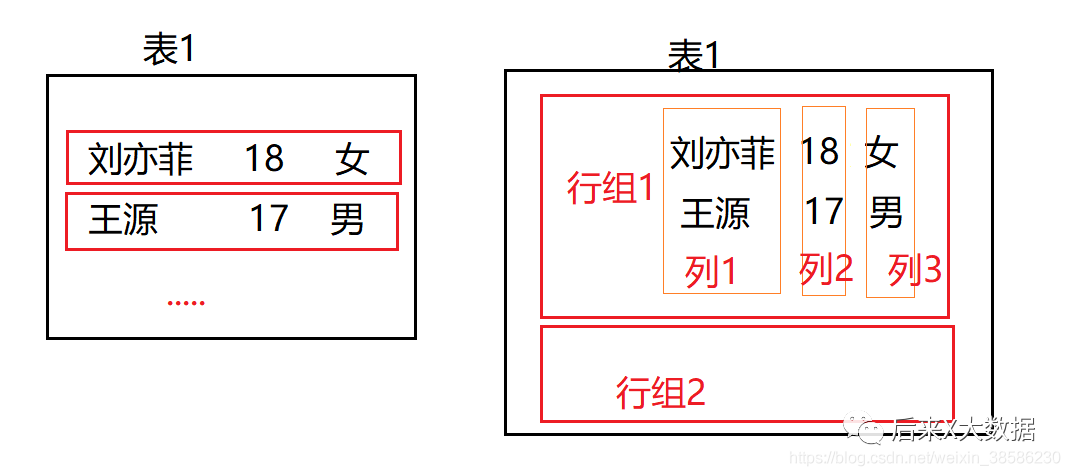
La figure de gauche montre la méthode de stockage de base de données traditionnelle basée sur les lignes, qui est stockée par ligne. S'il n'y a pas d'index de stockage, si vous devez interroger un champ, vous devez rechercher les données de la ligne entière, puis filtrer il, qui consomme plus de ressources IO., donc la méthode d'index a été utilisée pour résoudre ce problème dans Hive au début.
Cependant, en raison du coût élevé des index, "dans le Hive 3.X actuel, les index ont été supprimés" , et bien sûr, le stockage en colonnes a été introduit depuis longtemps.
La méthode de stockage du stockage en colonnes est stockée une colonne à la fois, comme illustré dans la figure de droite de la figure ci-dessus. Dans ce cas, si vous interrogez les données d'un champ, cela équivaut à une requête d'index, ce qui est très efficace. . Cependant, si vous devez rechercher l'intégralité du tableau, cela prendra plus de ressources car il doit prendre toutes les colonnes et les résumer séparément. Ainsi, le stockage des déterminants ORC est apparu.
-
Lorsqu'une analyse complète de la table est requise, elle peut être lue par groupe de lignes
-
Si vous avez besoin d'obtenir des données de colonne, lisez la colonne spécifiée sur la base du groupe de lignes, au lieu des données de toutes les lignes de tous les groupes de lignes et des données de tous les champs d'une ligne.
Après avoir compris la logique de base du stockage ORC, examinons son diagramme de modèle de stockage.
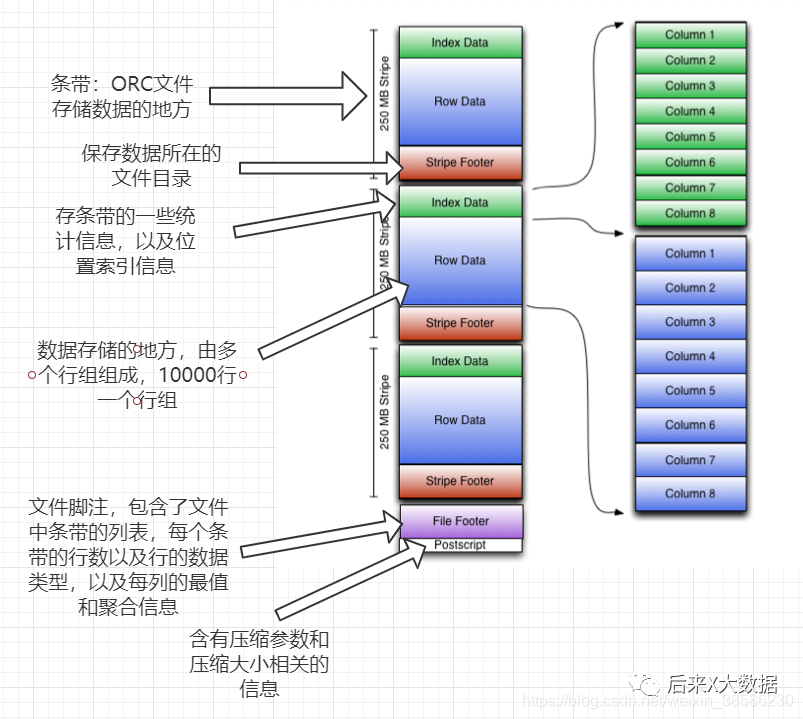
En même temps, j'ai également joint le texte détaillé ci-dessous, afin que vous puissiez le consulter :
-
Bande : là où le fichier ORC stocke des données, chaque bande correspond généralement à la taille de bloc de HDFS. (Contient les 3 parties suivantes)
index data:保存了所在条带的一些统计信息,以及数据在 stripe中的位置索引信息。
rows data:数据存储的地方,由多个行组构成,每10000行构成一个行组,数据以流( stream)的形式进行存储。
stripe footer:保存数据所在的文件目录
-
Pied de page du fichier : contient une liste de sipe dans le fichier, le nombre de lignes dans chaque bande et le type de données de chaque colonne. Il contient également des informations agrégées telles que min, max, nombre de lignes, sommation, etc. pour chaque colonne.
-
postscript : contient des informations sur les paramètres de compression et la taille de compression
Donc, en fait, on constate qu'ORC fournit trois niveaux d'index, niveau fichier, niveau bande et niveau groupe de lignes. Par conséquent, lors de l'interrogation, ces index peuvent être utilisés pour éviter la plupart des fichiers et des blocs de données qui ne répondent pas aux conditions de la requête. .
Cependant, notez que les informations de description de toutes les données dans ORC sont rassemblées avec les données stockées et n'utilisent pas de base de données externe.
"Remarque spéciale : les tables au format ORC prennent également en charge l'ACID de transaction, mais les tables qui prennent en charge les transactions doivent être des tables compartimentées, elles conviennent donc à la mise à jour de gros lots de données. Il n'est pas recommandé de mettre fréquemment à jour de petits lots de données avec des transactions"
#开启并发支持,支持插入、删除和更新的事务
set hive. support concurrency=truei
#支持ACID事务的表必须为分桶表
set hive. enforce bucketing=truei
#开启事物需要开启动态分区非严格模式
set hive.exec,dynamicpartition.mode-nonstrict
#设置事务所管理类型为 org. apache.hive.q1. lockage. DbTxnManager
#原有的org. apache. hadoop.hive.q1.1 eckmar. DummyTxnManager不支持事务
set hive. txn. manager=org. apache. hadoop. hive. q1. lockmgr DbTxnManageri
#开启在相同的一个 meatore实例运行初始化和清理的线程
set hive. compactor initiator on=true:
#设置每个 metastore实例运行的线程数 hadoop
set hive. compactor. worker threads=l
#(2)创建表
create table student_txn
(id int,
name string
)
#必须支持分桶
clustered by (id) into 2 buckets
#在表属性中添加支持事务
stored as orc
TBLPROPERTIES('transactional'='true‘);
#(3)插入数据
#插入id为1001,名字为student 1001
insert into table student_txn values('1001','student 1001');
#(4)更新数据
#更新数据
update student_txn set name= 'student 1zh' where id='1001';
# (5)查看表的数据,最终会发现id为1001被改为 sutdent_1zh
1.2 Configuration de la ruche à propos d'ORC
Propriétés de configuration de la table (configurées lors de la création d'une table, par exemple tblproperties ('orc.compress'='snappy');)
-
orc.compress : Indique le type de compression du fichier ORC. "Les types optionnels sont NONE, ZLB et SNAPPY. La valeur par défaut est ZLIB (Snappy ne prend pas en charge les tranches)" --- Cette configuration est la plus critique.
-
orc.compress.Slze : indique la taille du bloc compressé (morceau), la valeur par défaut est 262144 (256 Ko).
-
orc.stripe.size : écriture stripe, la taille du pool de mémoire tampon pouvant être utilisée, la valeur par défaut est 67108864 (64 Mo)
-
orc.row.index.stride : la taille des données de l'index au niveau du groupe de lignes, la valeur par défaut est 10 000, elle doit être définie sur un nombre supérieur ou égal à 10 000
-
orc.create index : s'il faut créer un index au niveau du groupe de lignes, la valeur par défaut est true
-
orc.bloom filter.columns : les groupes qui doivent créer des filtres bloom.
-
orc.bloom filter fpp : probabilité de faux positif (faux positif) à l'aide du filtre bloom, la valeur par défaut est 0.
Extension : l'utilisation du filtre Bloom dans Hive peut déterminer rapidement si les données sont stockées dans la table avec moins d'espace de fichier, mais il existe également une situation dans laquelle les données qui n'appartiennent pas à cette table sont déterminées comme appartenant à cette table, ce qui est appelée probabilité de faux positif, les développeurs peuvent ajuster la probabilité, mais plus la probabilité est faible, le filtre Bloom a besoin
2、Parquet
Après avoir parlé d'ORC ci-dessus, nous avons également une compréhension de base du stockage ligne-colonne, et Parquet est une autre structure de stockage ligne-colonne hautes performances.
2.1 Structure de stockage du parquet
Étant donné que ORC est si efficace, pourquoi devrait-il y avoir un autre Parquet, c'est parce que "Parquet doit rendre disponible une représentation de données en colonnes compressée et efficace pour tout projet de l'écosystème Hadoop"
❝Parquet est indépendant du langage et n'est lié à aucun cadre de traitement de données. Il convient à une variété de langages et de composants. Les composants qui peuvent fonctionner avec Parquet sont :
Moteurs de requête : Hive, Impala, Pig, Presto, Drill, Tajo, HAWQ, IBM Big SQL
Cadre de calcul : MapReduce, Spark, Cascading, Crunch, Scalding, Kite
Modèles de données : Avro, Thrift, Protocol Buffers, POJO
❞
Jetons un coup d'œil à la structure de stockage de Parquet, premier regard sur le site officiel

Bon, c'est un peu gros, je vais dessiner une version simplifiée
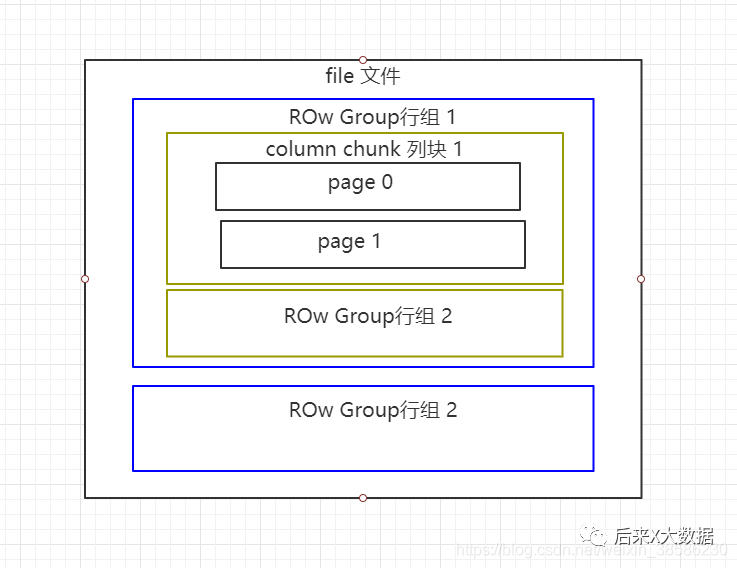
Les fichiers Parquet sont stockés au format binaire, ils ne peuvent donc pas être lus directement. Comme ORC, les métadonnées du fichier sont stockées avec les données, de sorte que les fichiers au format Parquet sont auto-parsés.
-
Groupe de lignes : chaque groupe de lignes contient un certain nombre de lignes, et au moins un groupe de lignes est stocké dans un fichier HDFS, similaire au concept de la bande d'orc.
-
Bloc de colonne : chaque colonne d'un groupe de lignes est stockée dans un bloc de colonnes, et toutes les colonnes du groupe de lignes sont stockées consécutivement dans ce fichier de groupe de lignes. Les valeurs d'un bloc de colonnes sont toutes du même type et différents blocs de colonnes peuvent être compressés à l'aide d'algorithmes différents.
-
Page : chaque bloc de colonnes est divisé en plusieurs pages. Une page est la plus petite unité de codage. Différentes pages d'un même bloc de colonnes peuvent utiliser différentes méthodes de codage.
2.2Propriétés de configuration de la table Parquet
-
parquet.block size : la valeur par défaut est 134217728byte, soit 128 Mo, ce qui indique la taille de bloc du Row Group en mémoire. Si cette valeur est définie sur grande, l'efficacité de lecture des fichiers Parquet peut être améliorée, mais en conséquence, plus de mémoire est consommée lors de l'écriture.
-
parquet.page:size : La valeur par défaut est 1048576byt, soit 1Mo, indiquant la taille de chaque page (page). Cela fait spécifiquement référence à la taille de la page compressée, et les données de la page seront décompressées en premier lors de la lecture. Une page est la plus petite unité de données d'exploitation de Parquet, et une page entière de données doit être lue à chaque fois pour accéder aux données. Si cette valeur est définie trop petite, cela entraînera des problèmes de performances lors de la compression
-
parquet.compression : La valeur par défaut est UNCOMPRESSED, qui indique la méthode de compression de la page. "Les méthodes de compression disponibles sont UNCOMPRESSED, SNAPPY, GZP et LZO" .
-
Parquet enable.dictionnaire : La valeur par défaut est tue, indiquant si l'encodage du dictionnaire est activé.
-
parquet.dictionary page.size : la valeur par défaut est 1048576 octets, soit 1 Mo. Lors de l'utilisation de l'encodage de dictionnaire, une page de dictionnaire est créée dans chaque ligne et colonne dans Parquet. En utilisant le codage par dictionnaire, s'il y a de nombreuses données répétées dans les pages de données stockées, cela peut avoir un bon effet de compression et peut également réduire l'occupation de la mémoire de chaque page.
3. Comparaison ORC et Parquet
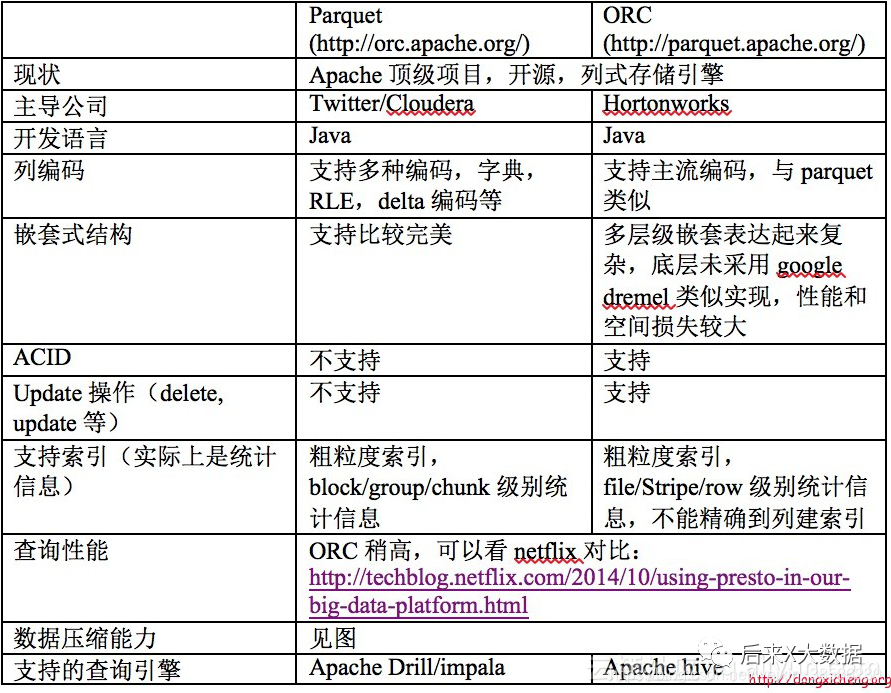
Dans le même temps, à partir du cas de l'auteur de "Hive Performance Tuning in Practice", 2 tables utilisant respectivement les formats de stockage ORC et Parquet, importent les mêmes données, et effectuent une requête sql, "on constate que les lignes lues en utilisant ORC sont beaucoup plus petits que Parquet" , donc en utilisant ORC comme stockage, vous pouvez filtrer davantage de données inutiles à l'aide de métadonnées, et la requête nécessite moins de ressources de cluster que Parquet. (Pour une analyse plus détaillée des performances, veuillez passer à https://blog.csdn.net/yu616568/article/details/51188479)
"Ainsi, ORC a toujours meilleure apparence en termes de stockage"
Méthode de compression
| Format | Divisible | Vitesse de compression moyenne | Efficacité de la compression des fichiers texte | Codec de compression Hadoop | Implémentation Java pur | Originaire de | Remarque |
|---|---|---|---|---|---|---|---|
| gzip | non | rapide | haute | org.apache.hadoop.io.compress.GzipCodec | Oui | Oui | |
| lzo | oui (selon la bibliothèque utilisée) | très vite | moyen | com.hadoop.compression.lzo.LzoCodec | Oui | Oui | Nécessite l'installation de LZO sur chaque nœud |
| bzip2 | Oui | lent | très haut | org.apache.hadoop.io.compress.Bzip2Codec | Oui | Oui | Utiliser Java pur pour la version divisible |
| zlib | non | lent | moyen | org.apache.hadoop.io.compress.DefaultCodec | Oui | Oui | Codec de compression par défaut de Hadoop |
| Snappy | non | très vite | Bas | org.apache.hadoop.io.compress.SnappyCodec | non | Oui | Snappy a un port Java pur, mais il ne fonctionne pas avec Spark/Hadoop |
Comment choisir la combinaison de stockage et de compression ?
Selon les exigences de l'ORC et du parquet, il existe généralement
1. Stockage au format ORC, compression Snappy
create table stu_orc(id int,name string)
stored as orc
tblproperties ('orc.compress'='snappy');
2, stockage au format parquet, compression Lzo
create table stu_par(id int,name string)
stored as parquet
tblproperties ('parquet.compression'='lzo');
3, stockage au format parquet, compression Snappy
create table stu_par(id int,name string)
stored as parquet
tblproperties ('parquet.compression'='snappy');
Étant donné que le SQL de Hive sera converti en tâches MR, si le fichier est stocké dans ORC, Snappy le compresse. Étant donné que Snappy ne prend pas en charge le fractionnement de fichiers, le fichier compressé "ne sera lu que par une seule tâche" . Si le fichier compressé est volumineux, alors le temps nécessaire pour traiter la carte du fichier sera beaucoup plus long que le temps de lecture de la carte du fichier ordinaire, qui est souvent appelé « le biais de données de la carte lisant le fichier » .
Afin d'éviter cette situation, il est nécessaire d'utiliser des algorithmes de compression qui prennent en charge la segmentation des fichiers tels que bzip2 et Zip lors de la compression des données. Cependant, ORC ne prend pas en charge ces méthodes de compression que nous venons de mentionner, c'est donc la raison pour laquelle les gens ne choisissent pas ORC lorsqu'ils peuvent rencontrer des fichiers volumineux pour éviter l'asymétrie des données.
Dans l'approche Hve on Spark, la même chose est vraie. Spark, en tant qu'architecture distribuée, essaie généralement de lire les données de plusieurs machines différentes ensemble. Pour ce faire, chaque nœud de travail doit être en mesure de trouver le début d'un nouvel enregistrement, ce qui nécessite que le fichier soit divisé, mais certains fichiers dans des formats compressés qui ne peuvent pas être divisés nécessitent un seul nœud pour lire toutes les données. Cela peut facilement créer des goulots d'étranglement de performance.