Renforcement ChatGPT apprentissage grand tueur - optimisation de la stratégie proximale (PPO)
L'optimisation de la politique proximale ( Proximal Policy Optimization ) provient de l'article Proximal Policy Optimization Algorithms (Schulman et. al., 2017), qui est actuellement l'algorithme d'apprentissage par renforcement (RL) le plus avancé . Cet algorithme élégant peut être utilisé pour diverses tâches et a été appliqué dans de nombreux projets. Le chatGPT récemment populaire a adopté cet algorithme.
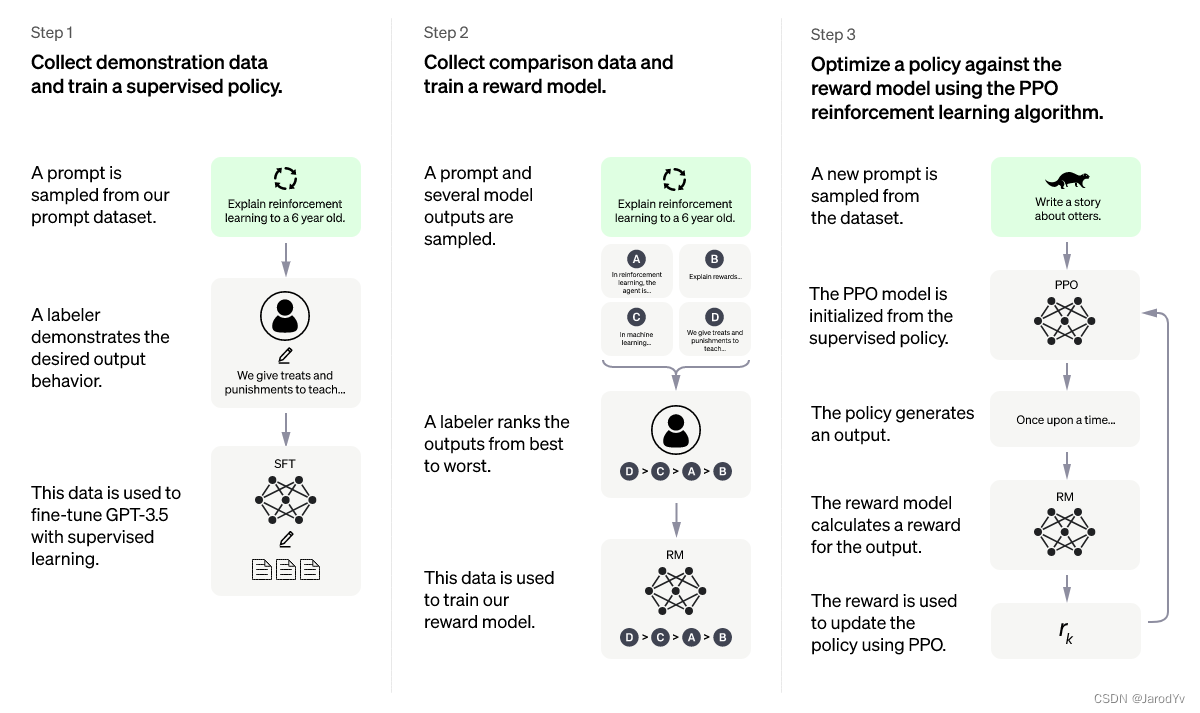
Il existe de nombreux articles sur Internet expliquant l'algorithme ChatGPT et le processus de formation, mais peu de gens expliquent en profondeur l'algorithme clé d'optimisation de la stratégie proximale . Dans cet article, je vais me concentrer sur l'explication de l'algorithme d'optimisation de la stratégie proximale et l'implémenter à partir de zéro avec PyTorch.
Annuaire d'articles
apprentissage par renforcement
En tant qu'algorithme avancé d'apprentissage par renforcement, l'optimisation de la stratégie proximale nécessite une compréhension de l'apprentissage par renforcement. Il existe de nombreux articles sur l’apprentissage par renforcement, je n’en présenterai pas trop ici, mais ici nous pouvons voir comment ChatGPT l’explique :

L'explication donnée par ChatGPT est relativement facile à comprendre. Plus académiquement parlant, le processus d'apprentissage par renforcement est le suivant :

Dans la figure ci-dessus, l'environnement renvoie les récompenses à l'agent à chaque instant et surveille l'état actuel. Avec ces informations, l'agent prend des mesures dans l'environnement, puis de nouvelles récompenses, états, etc. sont renvoyés à l'agent, formant une boucle. Ce cadre est très général et peut être appliqué dans divers domaines.
Notre objectif est de créer un agent qui maximise les récompenses. Habituellement, cette récompense de maximisation est la somme des récompenses de remise de temps individuelles.
G = ∑ t = 0 T γ trt G = \sum_{t=0}^T\gamma^tr_tg=t = 0∑Tct rt
Ici γ \gammaγ est un facteur d'actualisation, généralement compris entre [0,95, 0,99],rt r_trtest la récompense au temps t.
algorithme
Alors, comment résoudre les problèmes d'apprentissage par renforcement ? Il existe une variété d'algorithmes, qui peuvent (pour les processus décisionnels de Markov, ou MDP) se diviser en deux catégories : basé sur un modèle (crée un modèle de l'environnement) et sans modèle (apprend uniquement en fonction d'un état).
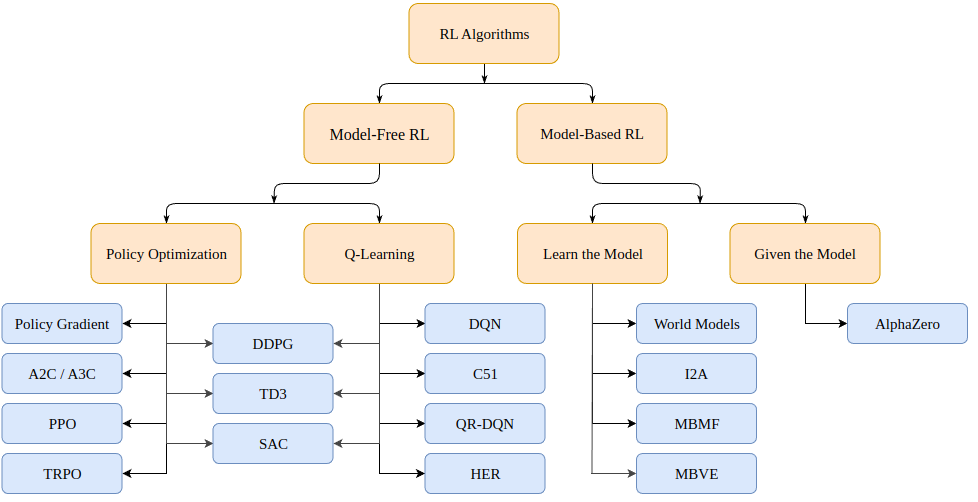
Les algorithmes basés sur des modèles créent un modèle de l'environnement et utilisent ce modèle pour prédire les états et les récompenses futurs. Le modèle est soit donné (par exemple un échiquier), soit appris.
Les algorithmes sans modèle apprennent directement comment agir sur les états rencontrés lors de la formation (optimisation de politique ou PO), et quelles actions d'état donnent de bonnes récompenses (Q-Learning).
Les algorithmes d'optimisation de politique proximale dont nous discutons aujourd'hui appartiennent à la famille des algorithmes PO. Par conséquent, nous n'avons pas besoin d'un modèle de l'environnement pour conduire l'apprentissage. La principale différence entre les algorithmes PO et Q-Learning est que l'algorithme PO peut être utilisé dans des environnements avec des espaces d'action continus (c'est-à-dire que nos actions ont de vraies valeurs) et peut trouver une stratégie optimale ; et l'algorithme Q-Learning ne peut pas faire les deux. C'est une autre raison pour laquelle l'algorithme PO est plus populaire. D'autre part, les algorithmes de Q-Learning ont tendance à être plus simples, plus intuitifs et plus faciles à former.
Optimisation des politiques (basée sur le gradient)
Les algorithmes d'optimisation des politiques peuvent apprendre directement les politiques. À cette fin, l'optimisation des politiques peut utiliser des algorithmes sans gradient tels que des algorithmes génétiques ou des algorithmes basés sur des gradients plus courants.
Par méthodes basées sur le gradient, nous entendons toutes les méthodes qui tentent d'estimer le gradient de la politique apprise par rapport à la récompense cumulée. Si nous connaissons ce gradient (ou une approximation de celui-ci), nous pouvons simplement déplacer les paramètres de la politique dans le sens du gradient pour maximiser la récompense.
La méthode du gradient de politique estime à plusieurs reprises le gradient g : = ∇ θ E [ ∑ t = 0 ∞ rt ] g:=\nabla_\theta\mathbb{E}[\sum_{t=0}^{\infin}r_t]g:=∇jeEt [ ∑t = 0∞rt] pour maximiser la récompense totale attendue. Il existe plusieurs expressions apparentées différentes pour le gradient de politique, qui sont de la forme :
g = E [ ∑ t = 0 ∞ Ψ t ∇ θ log π θ ( à ∣ st ) ] (1) g=\mathbb{E}\Bigg\lbrack \sum_{t=0}^{\infin} \Psi_t \nabla_\theta log\pi_\theta(a_t \mid s_t) \Bigg\rbrack \tag{1}g=Et [t = 0∑∞PSt∇jel o g πje( unt∣st) ]( 1 )
où Ψ t \Psi_tPStPeut être le suivant :
- ∑ t = 0 ∞ rt \sum_{t=0}^\infin r_t∑t = 0∞rt: la récompense totale de la trajectoire
- ∑ t ′ = t ∞ rt ′ \sum_{t'=t}^\infin r_{t'}∑t′ =t∞rt': prochaine action à a_tuntrécompense
- ∑ t = 0 ∞ rt − b ( st ) \sum_{t=0}^\infin r_t - b(s_t)∑t = 0∞rt−b ( st) : la version de base de la formule ci-dessus
- Q π ( st , à ) Q^\pi(s_t, a_t)Qπ (st,unt) : fonction état-action valeur
- A π ( s t , a t ) A^\pi(s_t, a_t) UNπ (st,unt) : fonction d'avantage
- rt + V π ( st + 1 ) + V π ( st ) r_t+V^\pi(s_{t+1})+V^\pi(s_{t})rt+DANSπ (st + 1)+DANSπ (st) : TD résiduel
Les définitions spécifiques des trois formules suivantes sont les suivantes :
V π ( st ) : = E st + 1 : ∞ , at : ∞ [ ∑ l = 0 ∞ rt + l ] Q π ( st , at ) : = E st + 1 : ∞ , à + 1 : ∞ [ ∑ l = 0 ∞ rt + l ] (2) V^\pi(s_t) := \mathbb{E}_{s_{t+1:\infin}, a_ {t : \infin}}\Bigg\lbrack\sum_{l=0}^\infin r_{t+l} \Bigg\rbrack \\ Q^\pi(s_t, a_t) := \mathbb{E}_ {s_{ t+1 :\infin}, a_{t+1 :\infin}}\Bigg\lbrack\sum_{l=0}^\infin r_{t+l} \Bigg\rbrack \tag{2}DANSπ (st):=ETst + 1 : ∞, unt : ∞[l = 0∑∞rt + l]Qπ (st,unt):=ETst + 1 : ∞, unt + 1 : ∞[l = 0∑∞rt + l]( 2 )
A π ( st , à ) : = Q π ( st , à ) − V π ( st ) (3) A^\pi(s_t, a_t) := Q^\pi(s_t, a_t) - V^\pi (s_t) \tag{3}UNπ (st,unt):=Qπ (st,unt)−DANSπ (st)( 3 )
Notez qu'il existe plusieurs façons d'estimer les gradients. Ici, nous énumérons 6 valeurs différentes : la récompense totale, la récompense de l'action ultérieure, la récompense moins la version de référence, la fonction de valeur d'état-action, la fonction de dominance (utilisée dans l'article original du PPO) et la différence de temps ( TD) Différence résiduelle. Nous pouvons choisir ces valeurs comme objectif de maximisation. En principe, ils fournissent tous les deux une estimation du véritable gradient qui nous intéresse.
optimisation de la stratégie proximale
L'optimisation de politique proximale, ou PPO en abrégé, est un algorithme (sans modèle) basé sur des gradients d'optimisation de politique. L'algorithme vise à apprendre une politique qui maximise la récompense cumulée obtenue en fonction de l'expérience pendant la formation.
Il consiste en un acteur π θ ( . ∣ st ) \pi\theta(. \mid st)π θ ( .∣s t ) et uncritique (critique) V ( st ) V(st)V ( s t ) composition. L'ancien au tempsttAffiche la distribution de probabilité de l'action suivante à t , qui estime la récompense cumulée attendue (scalaire) pour cet état. Étant donné que les acteurs et les critiques prennent l'état en entrée, l'architecture dorsale peut être partagée entre les deux réseaux pour extraire des fonctionnalités de haut niveau.
L'OPP vise à faire en sorte que la politique choisisse des actions avec un "avantage" plus élevé, c'est-à-dire avec une récompense cumulée beaucoup plus élevée que celle prédite par l'évaluateur. En même temps, nous ne voulons pas mettre à jour trop de stratégies à la fois, ce qui peut entraîner des problèmes d'optimisation. Enfin, si la politique a une entropie élevée, nous avons tendance à donner des récompenses supplémentaires pour inciter à plus d'exploration.
La fonction de perte totale se compose de trois termes : un terme CLIP, un terme de fonction de valeur (VF) et un terme de récompense d'entropie. Le but final est le suivant :
L t CLIP + VF + S ( θ ) = E ^ t [ L t CLIP ( θ ) − c 1 L t VF ( θ ) + c 2 S [ π θ ] ( st ) ] L_t ^{CLIP +VF+S}(\theta) = \hat{\mathbb{E}}_t \Big\lbrack L_t^{CLIP}(\theta) - c_1L_t^{VF}(\theta)+c_2S[\ pi_\theta ](s_t)\Big\rbrackLtC L I P + V F + S( je )=ET^t[ LtC L I P( je )−c1LtVF _( je )+c2S [ πje] ( st) ]
oùc 1 c_1c1et c 2 c_2c2sont des hyperparamètres qui mesurent l'importance de la précision de l'évaluation des politiques (critique) et de l'exploration (exploration), respectivement.
CLIP article
Comme nous l'avons dit, la fonction de perte motive la maximisation (ou la minimisation) de la probabilité d'action, ce qui conduit à l'action avantage positif (ou avantage négatif)
LCLIP ( θ ) = E ^ t [ min ( rt ( θ ) A t ^ , clip ( rt ( θ ) , 1 − ϵ , 1 + ϵ ) UNE ^ t ) ] L^{CLIP}(\theta) = \hat{\mathbb{E}}_t\Big\lbrack min \Big\lparen r_t (\theta )\hat{A_t},clip \big\lparen r_t(\theta),1-\epsilon, 1+\epsilon\big\rparen \hat{A}_t \Big\rparen \Big\rbrackLC L I P (θ)=ET^t[ mon ( rt( je )UNt^,c l je p ( rt( je ) ,1−ϵ ,1+) _UN^t) ]
Ouvert :
rt ( θ ) = π θ ( à ∣ st ) π θ old ( à ∣ st ) r_t(\theta) = \frac{\pi_\theta(a_t \mid s_t)}{\pi_{\theta_ {ancien}}(a_t\mid s_t)}rt( je )=Pijeo l d( unt∣st)Pije( unt∣st)
est le ratio qui mesure la probabilité que nous ayons maintenant (politique mise à jour) d'effectuer cette action précédente par rapport à avant. En principe, nous ne voulons pas que ce coefficient soit trop grand, car trop grand signifie un changement soudain de stratégie. C'est pourquoi on prend sa somme minimale [ 1 − ϵ , 1 + ϵ ] [1-\epsilon, 1+\epsilon][ 1−ϵ ,1+ϵ ] , oùϵ \epsilonϵ est un hyperparamètre.
La formule de calcul de l'avantage est la suivante :
A ^ t = − V ( st ) + rt + γ rt + 1 + γ 2 rt + 2 + ⋯ + γ ( T − t + 1 ) r T − 1 + γ T − t V ( s T ) \hat{A}_t = -V(s_t)+r_t+\gamma r_{t+1}+\gamma^2 r_{t+2}+\dots+\gamma^{(T-t +1 )} r_{T-1} + \gamma^{Tt}V(s_T)UN^t=− V ( st)+rt+γ rt + 1+c2 rt + 2+⋯+c( T - t + 1 ) rT − 1+cT − t V(sT)
où :A t ^ \hat{A_t}UNt^est l'avantage estimé, − V ( st ) -V(s_t)− V ( st) est la valeur estimée de l'état initial,γ T − t V ( s T ) \gamma^{Tt}V(s_T)cT − t V(sT) est la valeur estimée de l'état terminal, et la partie médiane est la récompense cumulée observée au cours du processus.
On voit qu'il mesure simplement la réponse de l'évaluateur à un état donné st s_tstdegré d'erreur. Si nous obtenons une récompense cumulée plus élevée, l'estimation des cotes sera positive et nous serons plus susceptibles d'agir dans cet état. L'inverse est également vrai, si nous nous attendons à une récompense plus élevée mais que nous obtenons une récompense plus petite, l'estimation des cotes sera négative et nous réduirons la probabilité d'agir à cette étape.
Notez que si nous allons jusqu'à l'état terminal s T s_TsT, nous n'avons plus besoin de nous fier à l'évaluateur, nous pouvons simplement comparer l'évaluateur à la récompense cumulée réelle. Dans ce cas, l'estimation de l'avantage est l'avantage réel.
terme de la fonction valeur
Pour avoir une bonne estimation de l'avantage, nous avons besoin d'un évaluateur capable de prédire la valeur d'un état donné. Le modèle est un apprentissage supervisé avec une simple perte MSE :
L t VF = MSE ( rt + γ rt + 1 + ⋯ + γ ( T − t + 1 ) r T − 1 + V ( s T ) , V ( st ) ) = ∣ ∣ UNE ^ t ∣ ∣ 2 L_t^{VF} = MSE(r_t+\gamma r_{t+1}+\dots+\gamma^{(T-t+1)} r_{T-1}+V( s_T),V(s_t)) = ||\hat{A}_t||_2LtVF _=MSE ( rt+γ rt + 1+⋯+c( T - t + 1 ) rT − 1+V ( sT) ,V ( st))=∣∣UN^t∣ ∣2
A chaque itération, nous mettons également à jour l'évaluateur pour qu'il nous donne des valeurs d'état de plus en plus précises au fur et à mesure de l'apprentissage.
terme de récompense d'entropie
Enfin, nous encourageons une petite exploration de récompense de l'entropie de la distribution de sortie politique. L'entropie standard est :
S [ π θ ] ( st ) = − ∫ π θ ( at ∣ st ) log ( π θ ( at ∣ st ) ) dat S[\pi_\theta](s_t) = -\int \pi_ \ theta(a_t \mid s_t) log(\pi_\theta(a_t \mid s_t))da_tS [ πje] ( st)=−∫Pije( unt∣st) journal ( p _ _je( unt∣st) ) _t
Implémentation de l'algorithme
Si l'explication ci-dessus n'est pas assez claire, ne vous inquiétez pas, ce qui suit vous amènera à mettre en œuvre l'algorithme d'optimisation de la stratégie proximale étape par étape à partir de zéro.
code d'outil
Importez d'abord les bibliothèques requises
from argparse import ArgumentParser
import gym
import numpy as np
import wandb
import torch
import torch.nn as nn
from torch.optim import Adam
from torch.optim.lr_scheduler import LinearLR
from torch.distributions.categorical import Categorical
import pytorch_lightning as pl
Les hyperparamètres importants de PPO sont le nombre d'acteurs, l'horizon, epsilon, le nombre d'époques dans chaque étape d'optimisation, le taux d'apprentissage, le facteur d'actualisation gamma et les constantes c1 et c2 pour peser différents éléments de perte. On passe dans ces hyperparamètres par des paramètres.
def parse_args():
"""解析参数"""
parser = ArgumentParser()
parser.add_argument("--max_iterations", type=int, help="训练迭代次数", default=100)
parser.add_argument("--n_actors", type=int, help="actor数量", default=8)
parser.add_argument("--horizon", type=int, help="每个actor的时间戳数量", default=128)
parser.add_argument("--epsilon", type=float, help="Epsilon", default=0.1)
parser.add_argument("--n_epochs", type=int, help="每次迭代的训练轮数", default=3)
parser.add_argument("--batch_size", type=int, help="Batch size", default=32 * 8)
parser.add_argument("--lr", type=float, help="学习率", default=2.5 * 1e-4)
parser.add_argument("--gamma", type=float, help="折扣因子gamma", default=0.99)
parser.add_argument("--c1", type=float, help="损失函数价值函数的权重", default=1)
parser.add_argument("--c2", type=float, help="损失函数熵奖励的权重", default=0.01)
parser.add_argument("--n_test_episodes", type=int, help="Number of episodes to render", default=5)
parser.add_argument("--seed", type=int, help="随机种子", default=0)
return vars(parser.parse_args())
Notez que par défaut, les paramètres sont définis comme décrit dans l'article. Idéalement, notre code devrait fonctionner sur le GPU autant que possible, nous devons donc configurer l'équipement de la torche.
def get_device():
if torch.cuda.is_available():
device = torch.device("cuda")
print(f"Found GPU device: {
torch.cuda.get_device_name(device)}")
else:
device = torch.device("cpu")
print("No GPU found: Running on CPU")
return device
Lorsque nous effectuons un apprentissage par renforcement, nous mettons généralement en place un tampon pour stocker l'état, l'action et la récompense rencontrés par le modèle actuel, qui est utilisé pour mettre à jour notre modèle. Nous créons une fonction run_timestampsqui exécutera un modèle donné dans un environnement donné et obtiendra un nombre fixe d'horodatages (réinitialisant l'environnement si l'épisode se termine). Nous utilisons également l'option render=Falseafin de ne vouloir voir que les performances du modèle formé.
@torch.no_grad()
def run_timestamps(env, model, timestamps=128, render=False, device="cpu"):
"""针对给定数量的时间戳在给定环境中运行给定策略。
返回具有状态、动作和奖励的缓冲区。"""
buffer = []
state = env.reset()[0]
# 运行时间戳并收集状态、动作、奖励和终止
for ts in range(timestamps):
model_input = torch.from_numpy(state).unsqueeze(0).to(device).float()
action, action_logits, value = model(model_input)
new_state, reward, terminated, truncated, info = env.step(action.item())
# (s, a, r, t)渲染到环境或存储到buffer
if render:
env.render()
else:
buffer.append([model_input, action, action_logits, value, reward, terminated or truncated])
# 更新当前状态
state = new_state
# 如果episode终止或被截断,则重置环境
if terminated or truncated:
state = env.reset()[0]
return buffer
La valeur de retour de cette fonction (lorsqu'elle n'est pas rendue) est un tampon contenant l'état, les actions entreprises, les probabilités d'action (logits), les valeurs d'évaluateur, les récompenses et l'état terminal de la politique fournie à chaque horodatage. Notez que cette fonction utilise un décorateur @torch.no_grad(), nous n'avons donc pas besoin de stocker les dégradés pour les actions effectuées lors de l'interaction avec l'environnement.
code de base
Avec les fonctions d'outil ci-dessus, nous pouvons développer le code de base de l'optimisation de la stratégie proximale. Tout d'abord, créez un nouveau processus de fonction principale :
def main():
# 解析参数
args = parse_args()
print(args)
# 设置种子
pl.seed_everything(args["seed"])
# 获取设备
device = get_device()
# 创建环境
env_name = "CartPole-v1"
env = gym.make(env_name)
# TODO 创建模型,训练模型,输出结果
model = MyPPO(env.observation_space.shape, env.action_space.n).to(device)
training_loop(env, model, args)
model = load_best_model()
testing_loop(env, model)
Ce qui précède est le cadre de processus du programme global. Ensuite, il nous suffit de définir le modèle PPO, d'entraîner et de tester les fonctions.
L'architecture du modèle PPO n'est pas élaborée ici, nous n'avons besoin que de deux modèles (acteur et critique) qui fonctionnent dans l'environnement. Bien sûr, l'architecture du modèle joue un rôle crucial dans les tâches plus complexes, mais dans notre tâche simple, un MLP peut faire le travail.
Par conséquent, nous pouvons créer une MyPPOclasse . Lors de l'exécution de la méthode directe sur un état, nous renvoyons les actions échantillonnées de l'acteur, les probabilités relatives (logits) de chaque action possible et l'estimation du critique pour chaque état.
class MyPPO(nn.Module):
"""
PPO模型的实现。
相同的代码结构即可用于actor,也可用于critic。
"""
def __init__(self, in_shape, n_actions, hidden_d=100, share_backbone=False):
# 父类构造函数
super(MyPPO, self).__init__()
# 属性
self.in_shape = in_shape
self.n_actions = n_actions
self.hidden_d = hidden_d
self.share_backbone = share_backbone
# 共享策略主干和价值函数
in_dim = np.prod(in_shape)
def to_features():
return nn.Sequential(
nn.Flatten(),
nn.Linear(in_dim, hidden_d),
nn.ReLU(),
nn.Linear(hidden_d, hidden_d),
nn.ReLU()
)
self.backbone = to_features() if self.share_backbone else nn.Identity()
# State action function
self.actor = nn.Sequential(
nn.Identity() if self.share_backbone else to_features(),
nn.Linear(hidden_d, hidden_d),
nn.ReLU(),
nn.Linear(hidden_d, n_actions),
nn.Softmax(dim=-1)
)
# Value function
self.critic = nn.Sequential(
nn.Identity() if self.share_backbone else to_features(),
nn.Linear(hidden_d, hidden_d),
nn.ReLU(),
nn.Linear(hidden_d, 1)
)
def forward(self, x):
features = self.backbone(x)
action = self.actor(features)
value = self.critic(features)
return Categorical(action).sample(), action, value
Notez qu'une Categorical(action).sample()distribution catégorielle est créée avec des logits d'action et des échantillons pour une action (pour chaque état).
Enfin, nous pouvons traiter l'algorithme réel dans training_loopla fonction . Comme nous le savons d'après l'article, la signature réelle de la fonction devrait ressembler à ceci :
def training_loop(env, model, max_iterations, n_actors, horizon, gamma,
epsilon, n_epochs, batch_size, lr, c1, c2, device, env_name=""):
# TODO...
Voici le pseudocode du programme de formation PPO dans l'article :

Le pseudo-code de PPO est relativement simple : nous collectons simplement les interactions avec l'environnement à travers de multiples copies du modèle de politique (appelés acteurs), et optimisons les réseaux d'acteurs et de critiques en utilisant des objectifs préalablement définis.
Puisque nous devons mesurer la récompense cumulée que nous avons réellement obtenue, nous devons créer une fonction qui, étant donné un tampon, remplace la récompense à chaque fois par la récompense cumulée :
def compute_cumulative_rewards(buffer, gamma):
"""
给定一个包含状态、策略操作逻辑、奖励和终止的缓冲区,计算每个时间的累积奖励并将它们代入缓冲区。
"""
curr_rew = 0.
# 反向遍历缓冲区
for i in range(len(buffer) - 1, -1, -1):
r, t = buffer[i][-2], buffer[i][-1]
if t:
curr_rew = 0
else:
curr_rew = r + gamma * curr_rew
buffer[i][-2] = curr_rew
# 在规范化之前获得平均奖励(用于日志记录和检查点)
avg_rew = np.mean([buffer[i][-2] for i in range(len(buffer))])
# 规范化累积奖励
mean = np.mean([buffer[i][-2] for i in range(len(buffer))])
std = np.std([buffer[i][-2] for i in range(len(buffer))]) + 1e-6
for i in range(len(buffer)):
buffer[i][-2] = (buffer[i][-2] - mean) / std
return avg_rew
Notez que nous normalisons la récompense cumulée à la fin. Il s'agit d'une astuce standard pour faciliter les problèmes d'optimisation et rendre l'entraînement plus fluide.
Maintenant que nous avons un tampon contenant l'état, l'action entreprise, la probabilité d'action et la récompense cumulée, nous pouvons écrire une fonction qui, compte tenu du tampon, calcule trois termes de perte pour notre objectif final :
def get_losses(model, batch, epsilon, annealing, device="cpu"):
"""给定模型、给定批次和附加参数返回三个损失项"""
# 获取旧数据
n = len(batch)
states = torch.cat([batch[i][0] for i in range(n)])
actions = torch.cat([batch[i][1] for i in range(n)]).view(n, 1)
logits = torch.cat([batch[i][2] for i in range(n)])
values = torch.cat([batch[i][3] for i in range(n)])
cumulative_rewards = torch.tensor([batch[i][-2] for i in range(n)]).view(-1, 1).float().to(device)
# 使用新模型计算预测
_, new_logits, new_values = model(states)
# 状态动作函数损失(L_CLIP)
advantages = cumulative_rewards - values
margin = epsilon * annealing
ratios = new_logits.gather(1, actions) / logits.gather(1, actions)
l_clip = torch.mean(
torch.min(
torch.cat(
(ratios * advantages,
torch.clip(ratios, 1 - margin, 1 + margin) * advantages),
dim=1),
dim=1
).values
)
# 价值函数损失(L_VF)
l_vf = torch.mean((cumulative_rewards - new_values) ** 2)
# 熵奖励
entropy_bonus = torch.mean(torch.sum(-new_logits * (torch.log(new_logits + 1e-5)), dim=1))
return l_clip, l_vf, entropy_bonus
Notez qu'en pratique, nous utilisons un paramètre de recuit qui commence à 1 et décroît linéairement jusqu'à 0 tout au long de l'apprentissage. Car au fur et à mesure que la formation progresse, nous souhaitons que notre politique change de moins en moins. De plus, contrairement à new_logitset new_values, nous ne gardons pas trace du advantagesgradient de la variable, juste de la différence de tenseur.
Maintenant que nous avons des méthodes pour interagir avec l'environnement et stocker des tampons, calculer la (vraie) récompense cumulée et obtenir le terme de perte, nous pouvons commencer à écrire le code d'entraînement final :
def training_loop(env, model, max_iterations, n_actors, horizon, gamma, epsilon, n_epochs, batch_size, lr,
c1, c2, device, env_name=""):
"""使用最多n个时间戳的多个actor在给定环境中训练模型。"""
# 开始运行新的权重和偏差
wandb.init(project="Papers Re-implementations",
entity="peutlefaire",
name=f"PPO - {
env_name}",
config={
"env": str(env),
"number of actors": n_actors,
"horizon": horizon,
"gamma": gamma,
"epsilon": epsilon,
"epochs": n_epochs,
"batch size": batch_size,
"learning rate": lr,
"c1": c1,
"c2": c2
})
# 训练变量
max_reward = float("-inf")
optimizer = Adam(model.parameters(), lr=lr, maximize=True)
scheduler = LinearLR(optimizer, 1, 0, max_iterations * n_epochs)
anneals = np.linspace(1, 0, max_iterations)
# 训练循环
for iteration in range(max_iterations):
buffer = []
annealing = anneals[iteration]
# 使用当前策略收集所有actor的时间戳
for actor in range(1, n_actors + 1):
buffer.extend(run_timestamps(env, model, horizon, False, device))
# 计算累积奖励并刷新缓冲区
avg_rew = compute_cumulative_rewards(buffer, gamma)
np.random.shuffle(buffer)
# 运行几轮优化
for epoch in range(n_epochs):
for batch_idx in range(len(buffer) // batch_size):
start = batch_size * batch_idx
end = start + batch_size if start + batch_size < len(buffer) else -1
batch = buffer[start:end]
# 归零优化器梯度
optimizer.zero_grad()
# 获取损失
l_clip, l_vf, entropy_bonus = get_losses(model, batch, epsilon, annealing, device)
# 计算总损失并反向传播
loss = l_clip - c1 * l_vf + c2 * entropy_bonus
loss.backward()
# 优化
optimizer.step()
scheduler.step()
# 记录输出
curr_loss = loss.item()
log = f"Iteration {
iteration + 1} / {
max_iterations}: " \
f"Average Reward: {
avg_rew:.2f}\t" \
f"Loss: {
curr_loss:.3f} " \
f"(L_CLIP: {
l_clip.item():.1f} | L_VF: {
l_vf.item():.1f} | L_bonus: {
entropy_bonus.item():.1f})"
if avg_rew > max_reward:
torch.save(model.state_dict(), MODEL_PATH)
max_reward = avg_rew
log += " --> Stored model with highest average reward"
print(log)
# 将信息记录到 W&B
wandb.log({
"loss (total)": curr_loss,
"loss (clip)": l_clip.item(),
"loss (vf)": l_vf.item(),
"loss (entropy bonus)": entropy_bonus.item(),
"average reward": avg_rew
})
# 完成 W&B 会话
wandb.finish()
Enfin, pour voir à quoi ressemblera le modèle au final, on utilise la testing_loopfonction :
def testing_loop(env, model, n_episodes, device):
for _ in range(n_episodes):
run_timestamps(env, model, timestamps=128, render=True, device=device)
De cette façon, notre programme principal deviendra très simple :
def main():
# 解析参数
args = parse_args()
print(args)
# 设置种子
pl.seed_everything(args["seed"])
# 获取设备
device = get_device()
# 创建环境
env_name = "CartPole-v1"
env = gym.make(env_name)
# 创建模型(actor和critic)
model = MyPPO(env.observation_space.shape, env.action_space.n).to(device)
# 训练
training_loop(env, model, args["max_iterations"], args["n_actors"], args["horizon"], args["gamma"], args["epsilon"],
args["n_epochs"], args["batch_size"], args["lr"], args["c1"], args["c2"], device, env_name)
# 加载最佳模型
model = MyPPO(env.observation_space.shape, env.action_space.n).to(device)
model.load_state_dict(torch.load(MODEL_PATH, map_location=device))
# 测试
env = gym.make(env_name, render_mode="human")
testing_loop(env, model, args["n_test_episodes"], device)
env.close()
C'est tout ce qui précède ! Si vous comprenez le code ci-dessus, félicitations, vous avez compris l'algorithme PPO.
en conclusion
Proximal Policy Optimization est un algorithme d'optimisation de pointe pour l'apprentissage du renforcement des politiques qui peut être utilisé dans presque tous les contextes. De plus, l'optimisation de la politique proximale a une fonction objective relativement simple et relativement peu d'hyperparamètres à régler.
ChatGPT s'appuie sur PPO pour obtenir plus de résultats que prévu lors de la troisième étape. Vous pouvez l'utiliser dans vos propres tâches d'apprentissage par renforcement et vous pouvez obtenir des résultats inattendus.